2.4 Hadoop 2.0
MapReduce已经进行了全新升级,即Hadoop 2.0,升级后的版本经常被称为MapReduce 2.0(MR v2)或者YARN。本书中常常提到其版本号2.x,虽然发行版本小数点后面的数字有变化,但是系统架构或者其运行方式并不会发生根本的变化。
MR v2是一套应用编程接口(API),该接口兼容MR v1,根据MR v1接口编写的程序仅需重新编译即可。Hadoop 2.x系统的底层架构已经完全改变了,Hadoop 1.x中的作业调度器承担两个主要功能:
- 资源管理(Resource management)
- 作业调度/作业监控(Job scheduling/job monitoring)
YARN把这两个功能分为两个守护进程来分别承担。这样的设计使得系统有一个全局的资源管理器以及每个程序有一个应用程序管理器(Application Master)。注意,我们这里提到了程序(application),而不是作业(job)。在新的Hadoop 2.x系统中,一个程序(application)既可以指传统概念上的一个单独的MapReduce作业,也可以指一系列作业组成的有向无环图(Directed Acyclic Graph,DAG)。DAG是一个由许多节点相连构成的图,图中没有循环。也就是说,无论使用什么样的方法来遍历这张图,你都不可能遇到已经在遍历过程中经过的节点。用简单明了的话说就是,多个作业组成了有向无环图就意味着这些作业之间存在着层属关系(hierarchical relationship)。
YARN还使得Hadoop的功用不仅仅局限于MapReduce。在后续章节中,我们会发现MapReduce框架存在着诸多局限。新的框架已经开始突破这些局限。举个例子,Apache Hive给Hadoop系统带来了SQL特性,Apache PIG可以让用户使用基于脚本的数据流方式在Hadoop系统中处理数据。像HAMA这样的新框架使得Hadoop系统更加适合迭代计算,这在机器学习这样的应用场景中非常有用。
来自Berkley的Spark/Shark框架是Hive 和 HAMA的结合,提供了低延时的SQL访问和一些内存计算能力。这些框架都是运行在HDFS之上的,Hadoop系统不能仅仅只支持其中的某一种。对框架重新设计是非常必需的,以使得基于海量数据批处理计算框架(不仅限于MapReduce模型),基于HAMA的数据整体同步并行计算(BSP)框架或者基于Shark/Spark的内存缓存和计算框架都能运行在统一的Hadoop系统之上。
经过重新设计的新框架可以使得整个Hadoop系统对其提供一致的原生支持。这会使得关于安全和资源管理的系统级策略能以一致的方式应用,所有系统都共享相同的底层HDFS。
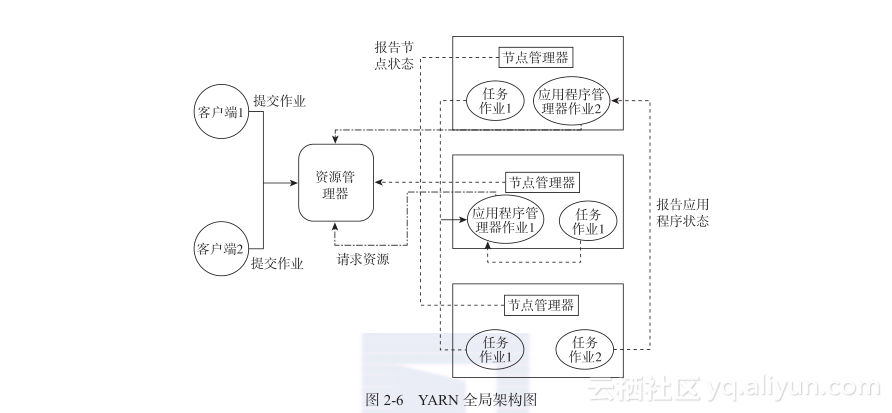
YARN系统由以下几个组成部分:
- 全局资源管理器(Global Resource Manager)
- 节点管理器(Node Manager)
- 针对每种应用程序的应用程序管理器(Application-specific Application Master)
- 调度器(Scheduler)
- 容器(Container)
一部分CPU内核和一部分内存构成了一个容器。一个应用程序(application)运行在一组容器中。应用程序管理器的一个实例会向全局资源管理器请求获取资源。调度器会通过每个节点的节点管理器(Node Manager)来分配资源(容器)。节点管理器会向全局资源管理器汇报每个容器的使用情况。
全局资源管理器和每个节点的节点管理器构成了新MapReduce框架的管理系统。全局资源管理器全权负责系统资源的分配。每种应用程序都有一个应用程序管理器。(比如,MapReduce是一种应用程序,每个MapReduce作业是MapReduce类型程序的一个实例,就像面向对象编程中的类和对象之间的关系一样)。针对同一应用程序类型的所有应用程序,一个应用程序管理器实例被初始化。应用程序管理器实例(instance)向全局资源管理器协商获得容器来运行作业。全局资源管理器利用调度器(全局组件)与每个节点的节点管理器的沟通结果来分配资源。从系统角度来看,应用程序管理器也是运行在一个容器之中的。
YARN全局架构如图2-6所示。
为了确保对已经存在的MapReduce程序的向后兼容,对MapReduce v1框架进行了重用,并没有做任何重大的修改。
我们来更详细地讲解YARN中的每个组件。从整体上来说,我们在一群商用服务器上搭建了Hadoop集群,每台服务器称为一个节点。
2.4.1容器
容器(Container)是YARN框架中的计算单元。它是一个任务进行工作的单元子系统。也可以这么认为,YARN框架中的容器相当于MapReduce v1中的一个任务(task)执行器。集群节点与容器之间的关系是:一个节点可以运行多个容器,但一个容器只能运行在一个节点之内。
一个容器就是已分配的一组系统资源。目前支持两种类型的系统资源:
- 中央处理器内核(CPU core)
- 内存(单位为MB)
拥有系统资源的容器在某一节点上执行,所以一个容器中隐含了“资源名称”的概念,这个“资源名称”就是容器所在的机架和节点的名称。请求一个容器的时候,就会向一个节点发出请求。容器使得程序可以在某个节点上获得指定数量的CPU内核和一定数量的内存。
实际上,任何任务或者程序(单个任务或者多个任务组成的有向无环图)都运行在一个或者多个容器中。在YARN框架中全权负责分配容器的组件叫做节点管理器。
2.4.2节点管理器
节点管理器(Node Manager)运行在集群中的一个节点上,集群中每个节点都会运行一个自己的节点管理器。它是作为一个从属服务(slave service):它接受来自另外一个称为资源管理器的组件的请求,然后分配容器给应用程序。它还负责监控和汇报资源使用情况给资源管理器。在Hadoop集群中,节点管理器与资源管理器一起协同工作,负责管理分配Hadoop系统资源。资源管理器是一个Hadoop集群的全局组件,节点管理器作为各个节点的代理来负责管理集群中每个节点的健康情况。节点管理器的任务如下:
- 接受来自资源管理器的请求,为作业的执行分配容器。
- 与资源管理器交换信息,确保整个集群的稳定运行。资源管理器依靠各个节点管理器的汇报来跟踪整个集群的健康状况,节点管理器作为代理任务来监控和管理本节点的健康状况。
- 管理每个已启动的容器的整个生命周期。
- 每个节点的日志管理。
- 运行各种YARN应用程序使用的辅助服务(auxiliary service)。举个例子,在目前的Hadoop系统实现中,MapReduce程序中的Shuffle服务就是一个辅助服务。
当一个节点启动,它会向资源管理器注册,并且告诉资源管理器有多少资源(最终可分配给容器使用的资源)可用。在节点运行期间,节点管理器和资源管理器会协同工作,不停地更新系统资源状态,保证集群资源有效地、优化地利用。
节点管理器仅对抽象出来的容器进行管理,而对单个应用程序或者应用程序类型的情况一无所知。负责管理这部分内容的是一个被称为应用程序管理器(Application Master)的组件。在我们介绍应用程序管理器之前,先简单介绍一下资源管理器。
2.4.3资源管理器
资源管理器的核心是一个调度器:当多个应用程序竞争使用集群资源的时候,它来负责资源的分配调度,确保集群资源的优化合理使用。资源管理器有一个插件化的调度器,该调度器按照程序队列和集群的处理能力,负责为正在运行的多个应用程序分配其所需的集群资源。Hadoop自带了计算能力调度器和公平调度器,在后面的章节中我们会详细地介绍这两种调度器。
一个任务的启动、配置及其资源的监控都由计算节点上的节点管理器(Node Manager)来负责。这种职责的分离使得资源管理器相比传统的作业调度器(JobScheduler)具备更好的系统扩展性。
2.4.4应用程序管理器
应用程序管理器(Application Master)是老的MapReduce v1 框架和YARN之间的关键区别之处。应用程序管理器是一个特定的框架函数库(framework-specific library)实例。它同资源管理器协调沟通资源,并通过节点管理器来获取这些系统资源,然后执行任务。应用程序管理器就是与资源管理器沟通以获取拥有系统资源的容器的组件。
应用程序管理器为YARN框架主要带来了以下好处:
- 提高了可扩展性。
- 框架更加通用。
在MapReduce v1中,负责处理任务失败的责任由作业跟踪器承担。作业跟踪器还要负责给要执行的任务分配系统资源。资源管理器(作业跟踪器的替代者)现在仅仅负责系统资源的调配,使得MapReduce v1系统框架的可扩展性获得了提升。管理作业或应用程序的工作就交给了应用程序管理器。如果一个任务失败了,应用程序管理器会同资源管理器协调沟通以获取系统资源,并尝试着重新执行该任务。
在MapReduce v1中,Hadoop系统框架仅仅支持MapReduce类型的作业,所以它并不是一个通用的框架。其主要原因就是因为系统中比如作业跟踪器和任务跟踪器这样的关键组件,它们的设计开发过于局限于Map和Reduce概念。随着MapReduce使用的越来越广泛,人们发现某些类型的数据计算是不适用MapReduce框架的。由此新框架被开发出来,比如基于Apache HAMA和Apache Giraph的BSP框架。这些新框架适合图计算,在HDFS系统上运行得很好。本书成稿之际,像Shark/Spark这样的内存框架越来越引起人们的注意。虽然它们在HDFS上运行得很好,但是却无法运行在Hadoop 1.x之中,因为他们对计算框架的设计思路完全不同。
在Hadoop 2.x中把应用程序管理器作为YARN的一部分引入进来,改变了这一切。使用不同的应用程序管理器来管理基于不同设计思想的计算框架,使得多种计算框架可以共存于一个统一的管理系统之中。在Hadoop 1.x中,Hadoop/HAMA/Shark虽然运行于相同的HDFS系统,但是只能分别运行在不同的管理系统之中,这样就造成了系统不一致和系统资源冲突,现在他们可以运行在同一个Hadoop2.x系统之中了。它们都通过资源管理器来公平地申请使用系统资源。YARN使得Hadoop系统的使用变得更加广泛。Hadoop系统现在不仅支持MapReduce类型的计算,它变得更加插件化:如果系统要增加某种类型的计算框架,就开发一个对应的应用程序管理器,并把这个程序管理器以插件的形式整合到Hadoop系统之中。应用程序管理器的概念使得Hadoop系统突破了MapReduce的限制,使得MapReduce可以与其他类型的计算框架共存并相互协作。
2.4.5分步详解YARN请求
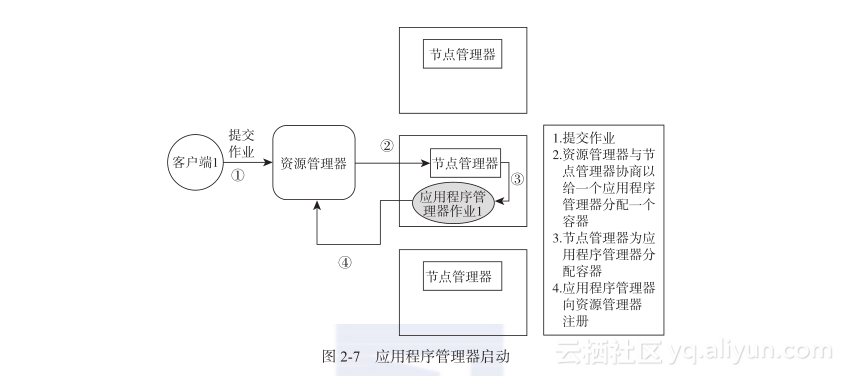
当一个用户向Hadoop2.x框架提交了一份作业,YARN框架后台处理该请求(如图2-7所示)。
步骤如下:
1)一个客户端提交作业程序。该应用程序的类型确定了,就决定了使用何种应用程序管理器。
2)资源管理器协调资源,在一个节点上获取一个用于运行应用程序管理器实例的容器。
3)应用程序管理器在资源管理器中注册。注册之后,客户端就可以向资源管理器查询该应用程序管理器的详细信息了。客户端将会与应用程序管理器通信,应用程序管理器已经通过自己的资源管理器启动了。
4)在这个操作过程中,应用程序管理器通过资源请求与资源管理器协商资源。除了其他内容,一个资源请求包括被请求的容器所在的节点和该容器的详细说明(CPU核数量和内存大小)。
5)在启动的容器中运行的应用程序会通过该应用程序特定的协议向应用程序管理器汇报它的执行进度(有可能是远程的)。
6)通过应用程序特定的协议,客户端与应用程序管理器通信。客户端通过查询在步骤3中注册的资源管理器的信息就可以找到对应的应用程序管理器。
上面的步骤如图2-8所示:
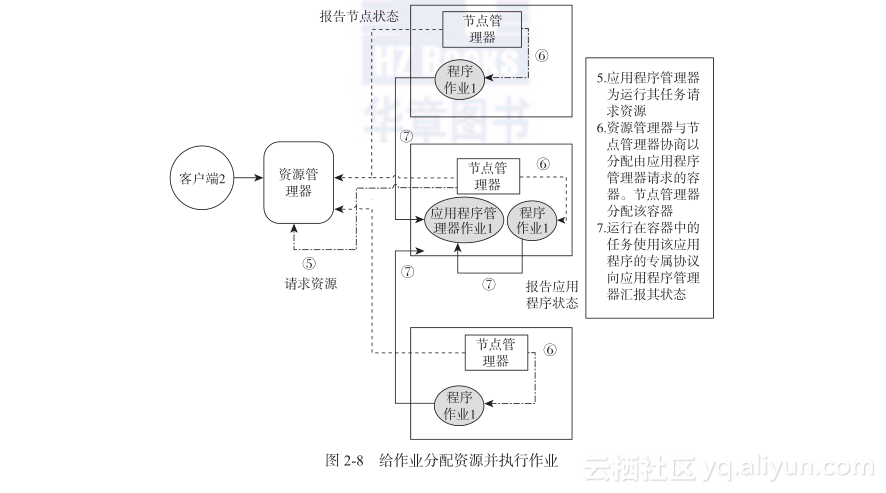
当应用程序执行完毕,应用程序管理器就会从资源管理器中取消注册,作业占用的容器将会被释放回系统中。