目录[-]
注意,IK Analyzer需要使用其下载列表中的 IK Analyzer 2012FF_hf1.zip,否则在和Lucene 4.10配合使用时会报错。
我使用 intellij IDEA 12进行的测试。
建立java项目
建立项目HelloLucene,导入Lucene的几个库。“File”->“Project Structure”->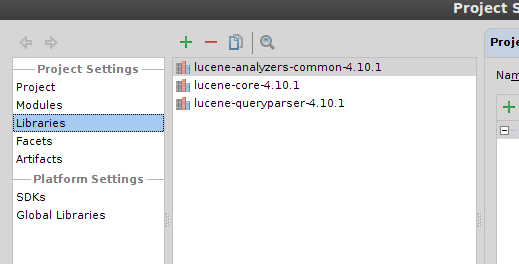
将IK Analyzer 2012FF_hf1.zip解压后的源码放入src目录,并将字典和配置文件放入src目录,最终如下:

一个示例:
IKAnalyzerDemo.java中是我在其他地方找的一个示例,和IK的官方示例很像。内容如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 |
|
这段代码是将索引文件放入内存中(RAMDirectory),运行结果如下:
|
1 2 3 4 |
|
这段代码有两个问题:
1、Field()已经不推荐按使用。
2、QueryParser()的使用方式也改变了。
下面是更加符合要求的示例。
第二个示例:
MyIndex类用来创建索引:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
|
索引以文件的形式存储在/home/letian/lucene-test/index目录中,Field被替换成了TextField,注意对于全文索引,不要使用StringField。
运行上面的代码,创建索引的结果如下: 
MySearch.java是一个搜索的示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
|
得到的结果如下:
|
1 2 3 |
|
目录[-]
注意,IK Analyzer需要使用其下载列表中的 IK Analyzer 2012FF_hf1.zip,否则在和Lucene 4.10配合使用时会报错。
我使用 intellij IDEA 12进行的测试。
建立java项目
建立项目HelloLucene,导入Lucene的几个库。“File”->“Project Structure”->
将IK Analyzer 2012FF_hf1.zip解压后的源码放入src目录,并将字典和配置文件放入src目录,最终如下:
一个示例:
IKAnalyzerDemo.java中是我在其他地方找的一个示例,和IK的官方示例很像。内容如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 |
|
这段代码是将索引文件放入内存中(RAMDirectory),运行结果如下:
|
1 2 3 4 |
|
这段代码有两个问题:
1、Field()已经不推荐按使用。
2、QueryParser()的使用方式也改变了。
下面是更加符合要求的示例。
第二个示例:
MyIndex类用来创建索引:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
|
索引以文件的形式存储在/home/letian/lucene-test/index目录中,Field被替换成了TextField,注意对于全文索引,不要使用StringField。
运行上面的代码,创建索引的结果如下:
MySearch.java是一个搜索的示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
|
得到的结果如下:
|
1 2 3 |
|