
容器是传统虚拟机的轻量级版本。它们不会占用您服务器上的大量空间,易于创建和消除,而且启动速度很快。它们还可以轻松地创建可重复使用的数据科学环境。
对于数据科学家来说,可以直接运行一个已经配备了执行特定分析所需的各种库和工具的容器,而无需花费几个小时在不同的环境中调试数据包或配置自定义的环境。这就是为什么 DataScience.com 使用 Docker 容器来处理该平台上的各种应用程序,例如用户可以启动独立的 Jupyter 和 RStudio 会话,其中已经配备了他们选择的库和工具。
什么是容器?
在 Docker 网站上,将容器定义为“一种标准化的软件单元”。那到底是什么意思呢?
容器就像它的名称一样:它包含一些内容。
在这里,软件容器包含运行软件应用程序所需的代码、框架和库。因为它只包含这些东西,所以就变得非常小;这意味着可以在一个操作系统上放置多个容器。这也意味着当您运行该软件的时候,会胸有成竹,因为您需要的一切都已经在那个容器里了。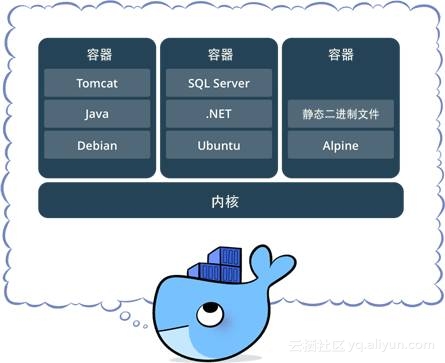
不过,真正重要的是容器所带来的标准化和效率。您的团队不再需要为每个分析建立一个新的环境,而是将某些类型的分析所需的工具和数据包 (例如 scikit-learn、TensorFlow、Jupyter 等) 放入容器中,创建该容器的镜像,并让每位用户从该镜像中启动一个独立的、标准化的环境。
等一下,什么是镜像?
镜像实质上是在特定时间点运行的容器的快照,它可以作为其他容器的模板。所有正在运行的容器都来自一个镜像,您可以对任何正在运行的容器进行快照以创建新镜像。您也可以从该镜像中根据需要启动多个容器。这下明白了吧?
像 Docker Hub 这样的存储库包含数十万个镜像,可以免费下载。这当中肯定有一个镜像,其中包含你执行特定分析所需的工具。
如果您在 DataScience.com 平台上工作,那么要找到含有所需工具的镜像非常简单,只需在启动环境时从下拉菜单中选择合适的镜像即可。我们已经为深度学习、自然语言处理和其他数据科学技术创建了许多预先配置好的镜像,可用于我们平台上的 RStudio 和 Jupyter 会话。
为什么要将数据科学环境配置在容器中?
其中一个考虑因素就是速度。我们希望使用我们平台的数据科学家可以在几分钟内就启动一个 Jupyter 或 RStudio 会话,而不是几个小时。我们还希望他们拥有快速的用户体验,同时仍然在一个受监管的中心式架构(而不是在他们的本地机器上)中工作。每家公司的环境搭建和运行的过程各不相同,但在某些情况下,数据科学家必须向 IT 部门提交正式申请,并等待数天或数周,这取决于他们手头积压的工作。这给两个团队都带来了工作压力。
容器化对于数据科学和 IT 技术运维团队而言都有利。例如,在 DataScience.com 平台上,我们允许 IT 在管理仪表板中配置具有不同语言、库和设置的环境,并使这些镜像出现在数据科学家启动会话时的下拉菜单中。这些环境可以用于任何运行、会话、计划作业或 API。(或者您不必配置任何内容。我们提供了大量的标准环境模板供您选择。)
最终,容器从企业层面上解决了开展数据科学工作遇到的许多常见问题。IT 人员不再为每个分析创建定制的环境,不再需要标准化数据科学家的工作方式,不再需要耗费精力确保旧代码不会因为环境变化而停止运行,这让他们的压力大减。
文章转载自:Docker官方公众号,原文链接
Docker 企业版在中国由我们的战略合作伙伴阿里巴巴提供
联系阿里云销售人员获取 Docker 企业版,或访问阿里云市场在线购买