1.4 数据挖掘建模过程
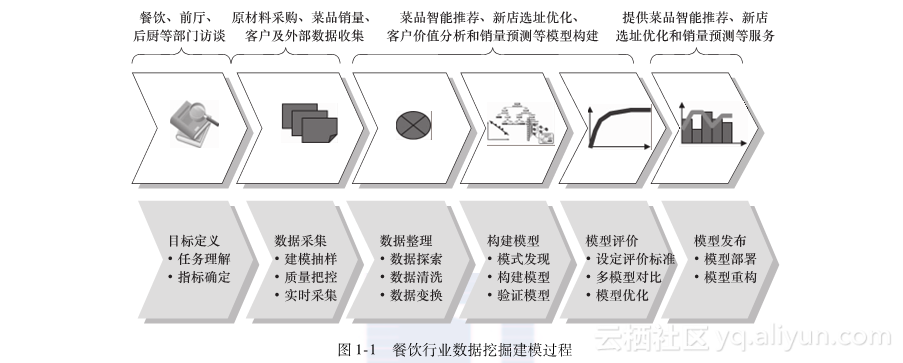
从本节开始,将以餐饮行业的数据挖掘应用为例来详细介绍数据挖掘的建模过程,如图1-1所示。
1.4.1 定义挖掘目标
针对具体的数据挖掘应用需求,首先要明确本次的挖掘目标是什么?系统完成后能达到什么样的效果?因此我们必须分析应用领域,包括应用中的各种知识和应用目标,了解相关领域的有关情况,熟悉背景知识,弄清用户需求。要想充分发挥数据挖掘的价值,必须要对目标有一个清晰明确的定义,即决定到底想干什么。
针对餐饮行业的数据挖掘应用,可定义如下挖掘目标:
实现动态菜品智能推荐,帮助顾客快速发现自己感兴趣的菜品,同时确保推荐给顾客的菜品也是餐饮企业所期望的,实现餐饮消费者和餐饮企业的双赢;
对餐饮客户进行细分,了解不同客户的贡献度和消费特征,分析哪些客户是最有价值的,哪些是最需要关注的,对不同价值的客户采取不同的营销策略,将有限的资源投放到最有价值的客户身上,实现精准化营销;
基于菜品历史销售情况,综合考虑节假日、气候和竞争对手等影响因素,对菜品销量进行趋势预测,方便餐饮企业准备原材料;
基于餐饮大数据,优化新店选址,并对新店所在位置的潜在顾客口味偏好进行分析,以便及时进行菜式调整。
1.4.2 数据取样
在明确需要进行数据挖掘的目标后,接下来就需要从业务系统中抽取出一个与挖掘目标相关的样本数据子集。抽取数据的标准,一是相关性,二是可靠性,三是有效性,而不是动用全部企业数据。通过数据样本的精选,不仅能减少数据处理量,节省系统资源,而且使我们想要寻找的规律性更加突显出来。
进行数据取样,一定要严把质量关。在任何时候都不能忽视数据的质量,即使是从一个数据仓库中进行数据取样,也不要忘记检查其质量如何。因为数据挖掘是要探索企业运作的内在规律性,原始数据有误,就很难从中探索规律性。若真的从中探索出了“规律性”,再依此去指导工作,则很可能会造成误导。若从正在运行的系统中进行数据取样,更要注意数据的完整性和有效性。
衡量取样数据质量的标准包括:
1)资料完整无缺,各类指标项齐全;
2)数据准确无误,反映的都是正常(而不是异常)状态下的水平。
对获取的数据,可再从中作抽样操作。抽样的方式是多种多样的,常见的有:
随机抽样:在采用随机抽样方式时,数据集中的每一组观测值都有相同的被抽样的概率。如按10%的比例对一个数据集进行随机抽样,则每一组观测值都有10%的机会被取到。
等距抽样:如按5%的比例对一个有100组观测值的数据集进行等距抽样,则有:100/5=20,等距抽样方式是取第20、40、60、80和第100这5组观测值。
分层抽样:在这种抽样操作时,首先将样本总体分成若干层次(或者说分成若干个子集)。在每个层次中的观测值都具有相同的被选用的概率,但对不同的层次可设定不同的概率。这样的抽样结果通常具有更好的代表性,进而使模型具有更好的拟合精度。
从起始顺序抽样:这种抽样方式是从输入数据集的起始处开始抽样。抽样的数量可以给定一个百分比,或者直接给定选取观测值的组数。
分类抽样:在前述几种抽样方式中,并不考虑抽取样本的具体取值。分类抽样则依据某种属性的取值来选择数据子集,如按客户名称分类、按地址区域分类等。分类抽样的选取方式就是前面所述的几种方式,只是抽样以类为单位。
基于1.4.1节定义的针对餐饮行业的挖掘目标,需从客户关系管理系统、前厅管理系统、后厨管理系统、财务管理系统和物资管理系统抽取用于建模和分析的餐饮数据,主要包括:
1)餐饮企业信息:名称、位置、规模、联系方式,以及部门、人员、角色等;
2)餐饮客户信息:姓名、联系方式、消费时间、消费金额等;
3)餐饮企业菜品信息:菜品名称、菜品单价、菜品成本、所属部门等;
4)菜品销量数据:菜品名称、销售日期、销售金额、销售份数;
5)原材料供应商资料及商品数据:供应商姓名、联系方式、商品名称,以及客户评价信息;
6)促销活动数据:促销日期、促销内容、促销描述;
7)外部数据:如天气、节假日、竞争对手以及周边商业氛围等。
1.4.3 数据探索
前面所叙述的数据取样,多少是带着人们对如何实现数据挖掘目标的先验认识进行操作的。当我们拿到一个样本数据集后,它是否达到我们原来设想的要求;其中有没有什么明显的规律和趋势;有没有出现从未设想过的数据状态;属性之间有什么相关性;它们可区分成哪些类别……,这都是要首先探索的内容。
对所抽取的样本数据进行探索、审核和必要的加工处理,是保证最终挖掘模型的质量所必需的。可以说,挖掘模型的质量不会超过所抽取样本的质量。数据探索和预处理的目的是保证样本数据的质量,从而为保证模型质量打下基础。
针对1.4.2节采集的餐饮数据,数据探索主要包括:异常值分析、缺失值分析、相关性分析、周期性分析等,有关介绍详见第3章。
1.4.4 数据预处理
当采样数据维度过大时,如何进行降维处理、缺失值处理等都是数据预处理要解决的问题。
由于采样数据中常常包含许多含有噪声、不完整,甚至不一致的数据,对数据挖掘所涉及的数据对象必须进行预处理。那么如何对数据进行预处理以改善数据质量,并最后达到完善最终数据挖掘结果的目的呢?
针对采集的餐饮数据,数据预处理主要包括:数据筛选、数据变量转换、缺失值处理、坏数据处理、数据标准化、主成分分析、属性选择、数据规约等,有关介绍详见第4章。
1.4.5 挖掘建模
样本抽取完成并经预处理后,接下来要考虑的问题是:本次建模属于数据挖掘应用中的哪类问题(分类、聚类、关联规则、时序模式或者智能推荐),选用哪种算法进行模型构建?
这一步是数据挖掘工作的核心环节。针对餐饮行业的数据挖掘应用,挖掘建模主要包括基于关联规则算法的动态菜品智能推荐、基于聚类算法的餐饮客户价值分析、基于分类与预测算法的菜品销量预测、基于整体优化的新店选址。
以菜品销量预测为例,模型构建是对菜品历史销量,是综合了节假日、气候和竞争对手等采样数据轨迹的概括,它反映的是采样数据内部结构的一般特征,并与该采样数据的具体结构基本吻合。模型的具体化就是菜品销量预测公式,公式可以产生与观察值有相似结构的输出,这就是预测值。
1.4.6 模型评价
从1.4.5节的建模过程中会得出一系列的分析结果,模型评价的目的之一就是从这些模型中自动找出一个最好的模型,另外就是要根据业务对模型进行解释和应用。
对分类与预测模型和聚类分析模型的评价方法是不同的,具体评价方法详见5.1节和5.2节介绍。