11.53 合成人脸画像质量评价
下面对以上三章中提到的基于稀疏近邻选择方法(SFS, Sparse Feature Selection)、基于人脸幻 象 思 想 的 合 成 方 法(SFS-SVR, Sparse FeatureSelection & Support Vector Regression) 和 基 于 直推式学习的方法(TFSS, Transductive Face SketchSynthesis)三种算法,以及基于位置的人脸画像合成方法 (PFSS, Position based Face Sketch Synthesis)[15]和基于马尔科夫权重场的方法 (MWF, MarkovWeight Field) [7] 进行质量评价。用这五种算法在CUHK 学生画像数据库[6]和 AR 画像数据库[16]上进行合成实验,每种算法生成 223 张画像(CUHK学生数据库 100 张,AR 数据库 123 张),算法部分合成结果示于图 5 中。图中,第一列为数据库中照片;第二列为画家手绘真实画像;第三列至最后一列分别为 SFS 方法、SFS-SVR 方法、PFSS 方法、MWF 方法及 TFSS 方法。
这里采用的主观评价算法是两两成对比较。由于进行评价的目的是评价合成算法合成的效果,因而进行成对比较时,只需要比较对应于数据库中同一人的 5 种算法生成的画像的质量,即成对比较的内容是“相同”的(这里的内容相同指他们都属于同一个人的合成画像)。评价合成画像质量时,一般从两个方面来评价。① 合成的画像跟输入照片像不像;② 合成的画像纹理好不好。后台打分的规则是:画像 A 比画像 B 质量高,则 A 画像得 2 分,反之 B 得 2 分。如果无法判定(即不确定两者质量孰好孰坏)则两者均得 1 分。故每幅画像最高得分为 8 分(与其余四种算法合成的对应身份的画像质量相比,均判断为更好),最低得分为 0 分(其余四种算法合成的对应身份的画像质量与之相比均判断为更好)。实验中共邀请 16 位测评者进行测评,这些测评者来自各行各业,有工程师、学生、工人和老师等。
图 6 示出了主观质量评价的一种统计展示,其中,横轴为评价分数取值范围为 0~8 分;纵轴为百分比,表示某个合成算法合成的画像质量评价分数,大于横轴对应的分数的画像占该算法合成画像总数(本数据库中为 223)的百分比。该百分比越大,说明对应算法取得大于某分数的合成画像数量越多。从图中可以看出,TFSS 方法取得效果最佳。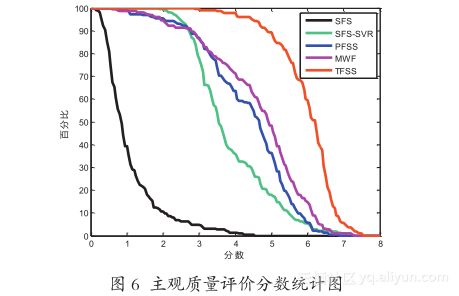
从图 6 中可以看出,基于直推式学习的合成方法 TFSS 总体评价值最高,基于马尔科夫权重场的合成方法 MWF 与基于位置的合成方法 PFSS 在大于 3 分小于 6 分的区间内领先于 SFS 和 SFS-SVR。但在小于 3 分的区间内,SFS-SVR 领先于除 TFSS之外的所有方法。由于模糊的原因,SFS 方法在五个合成算法中合成效果最差。这里需要注意的是由于主观评价做的是成对比较,比较的是算法,故这里 SFS 合成效果差只是相对于其他四种算法,并不是绝对的。SFS-SVR 方法大于所有的合成图像都大于 1 分,大于 2 分的占 99.5% ,说明仅有一张图像小于 2 分,且该图像得分大于 1 分。所有方法最终得到的平均质量评价分数没有等于 8 分(本系统中质量评价值最高位 8 分)的,说明没有一张合成画像是所有测评者认为其质量均优于其他四种算法合成效果的。
此外,我们还进行了基于上面五种算法合成的画像的人脸识别实验。由于本文的重点是异质人脸图像合成,人脸识别是提出的合成算法的下游应用之一,因此这里不再深究具体的人脸识别算法,而采用最常用的 3 个人脸识别算法,即 Eigenface[17] 、Fisherface [18]和 NLDA (Null-space LinearDiscriminant Analyisis) [19] 。XM2VTS 数据库[20]中的 195 对画像和照片作为训练人脸识别算法的数据集。表 1 给出了基于 5 种方法合成的人脸画像的最高识别率 , 以及对应的特征维数 ( 括号中的数字 )。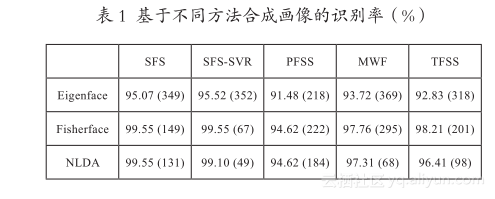
从表 1 中可以看出,SFS 方法和 SFS-SVR 合成方法在使用 Fisherface 和 NLDA 识别方法时,能够在特征维数很低的情况下取得最高的准确率,维数越低,运算量越低,实时性越高。Fisherface 和 NLDA方法是监督学习方法,而 Eigenface 是无监督方法,故 Fisherface 和 NLDA 的人脸识别准确率明显高于Eigenface 方法。结合前面图 6 中给出的主观质量评价结果可以看出,并不是主观评价质量越高的图像越适合计算机进行人脸识别。人们评价图像时会被细节信息吸引,而这些细节信息有时并不一定适合于计算机进行识别,对于计算机而言,这些细节信息可能是“噪声”。现有的识别方法更多的是基于统计的一些信息来进行识别,而不是细节的一些信息,故而在主观评价质量值最低的两个方法 (SFS 和SFS-SVR) 反而能取得最高的人来识别准确率。