背景引入
执行计划缓存是SQL Server内存管理中非常重要的特性,这篇文章是巧用执行计划缓存系列文章之五,探讨如何从执行计划缓存中获取查询语句执行计划编译的性能消耗,比如:
编译时间消耗
编译CPU消耗
编译内存消耗
缓存大小消耗
等等一系列非常有价值的统计信息。
什么是执行计划编译
SQL查询语句在提交到SQL Server主机服务之后,数据查询访问动作发生之前,SQL Server的编译器需要将查询语句进行编译,然后查询优化器生成最优执行计划。而这个编译和最优执行计划选择的过程,往往比较消耗系统性能,因此,SQL Server会将最优的执行计划存储在执行计划缓存中,以供将来类似的查询语句(相同的语句或者已经参数化的查询)直接从内存中获取执行计划,而避免重新编译,以此来节约系统性能开销,提高查询语句执行效率。
详情参加如下图所示: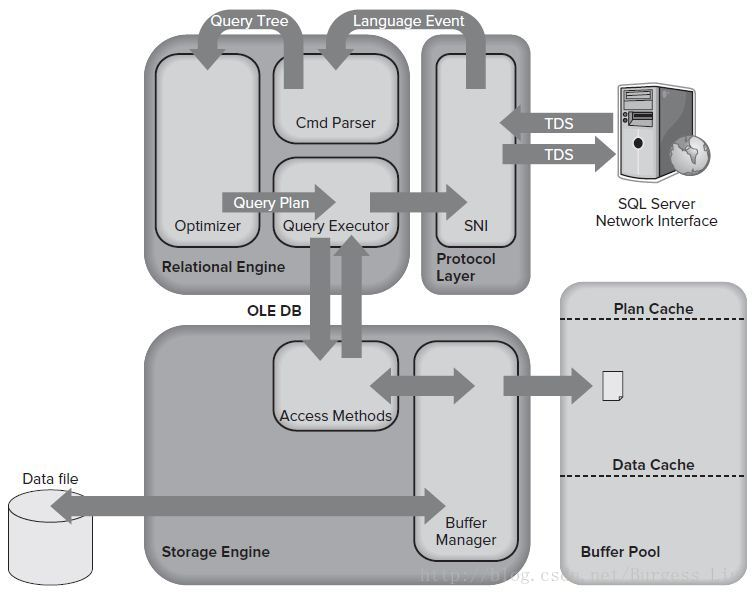
备注:
图片来自于SQL Server架构----查询的生命周期(上)。
执行计划编译消耗统计
解释了什么是执行计划编译,以及明白了查询语句编译过程比较消耗性能,那么我们如何定量的分析查询语句对性能的消耗呢?比如:
查询语句对编译时间的开销
查询语句对CPU开销
查询语句编译过程的内存开销
查询语句对执行计划缓存占用大小
要得到这些统计信息,我们完全可以通过分析执行计划缓存来得到,详情参见如下代码。这段代码可以获取前面我们提到的所有性能指标,甚至更多,我们可以修改默认的排序字段来获取不同性能指标的TOP查询语句,以及相应的性能开销。
use master
GO
SET NOCOUNT ON
IF OBJECT_ID('tempdb..#temp', 'U') IS NOT NULL
DROP TABLE #temp
DECLARE
@sql NVARCHAR(MAX)
,@orderCol SYSNAME
,@TOPN INT
;
SELECT
@sql = N'SELECT TOP(@TOPN) * FROM #temp ORDER BY '
,@TOPN = 20
,@orderCol = '' -- by default CPU: cpu/memory/duration/cachesize/
;WITH XMLNAMESPACES (DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan'),
DataInfo AS (
SELECT
T.c.value('xs:hexBinary(substring((@QueryHash)[1],3))', 'varbinary(max)') AS QueryHash,
T.c.value('xs:hexBinary(substring((@QueryPlanHash)[1],3))', 'varbinary(max)') AS QueryPlanHash,
T.c.value('(QueryPlan/@CachedPlanSize)[1]', 'int') AS CachedPlanSize_KB,
T.c.value('(QueryPlan/@CompileTime)[1]', 'int') AS CompileTime_ms,
T.c.value('(QueryPlan/@CompileCPU)[1]', 'int') AS CompileCPU_ms,
T.c.value('(QueryPlan/@CompileMemory)[1]', 'int') AS CompileMemory_KB,
qp.query_plan
FROM sys.dm_exec_cached_plans AS cp WITH(NOLOCK)
CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) AS qp
CROSS APPLY qp.query_plan.nodes('ShowPlanXML/BatchSequence/Batch/Statements/StmtSimple') AS T(c)
)
SELECT
CompileTime_ms,
CompileCPU_ms,
CompileMemory_KB,
CachedPlanSize_KB,
qs.execution_count,
CAST(qs.total_elapsed_time*1.0/1000 AS decimal(12,2))AS duration_ms,
CAST(qs.total_worker_time*1.0/1000 AS decimal(12,2)) as cputime_ms,
CAST((qs.total_elapsed_time*1.0/qs.execution_count)/1000 AS decimal(12,2)) AS avg_duration_ms,
CAST((qs.total_worker_time*1.0/qs.execution_count)/1000 AS decimal(12,2)) AS avg_cputime_ms,
CAST(qs.max_elapsed_time*1.0/1000 AS decimal(12,2)) AS max_duration_ms,
CAST(qs.max_worker_time*1.0/1000 AS decimal(12,2)) AS max_cputime_ms,
SUBSTRING(st.text, (qs.statement_start_offset / 2) + 1,
(CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(st.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset) / 2 + 1) AS StmtText,
query_hash,
query_plan_hash
INTO #temp
FROM DataInfo AS tab
INNER JOIN sys.dm_exec_query_stats AS qs WITH(NOLOCK)
ON tab.QueryHash = qs.query_hash
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS st
SET
@sql = @sql +
CASE @orderCol
WHEN 'cpu' THEN ' CompileCPU_ms DESC'
WHEN 'memory' THEN ' CompileMemory_KB DESC'
WHEN 'duration' THEN ' CompileTime_ms DESC'
WHEN 'cachesize' THEN ' CachedPlanSize_KB DESC'
ELSE ' CompileCPU_ms DESC'
END
;
EXEC sys.sp_executesql @sql
,N'@TOPN INT'
,@TOPN = @TOPN;
以上查询是获取查询语句编译对CPU消耗最多的TOP 20查询语句,以及相关的性能指标。如下截图: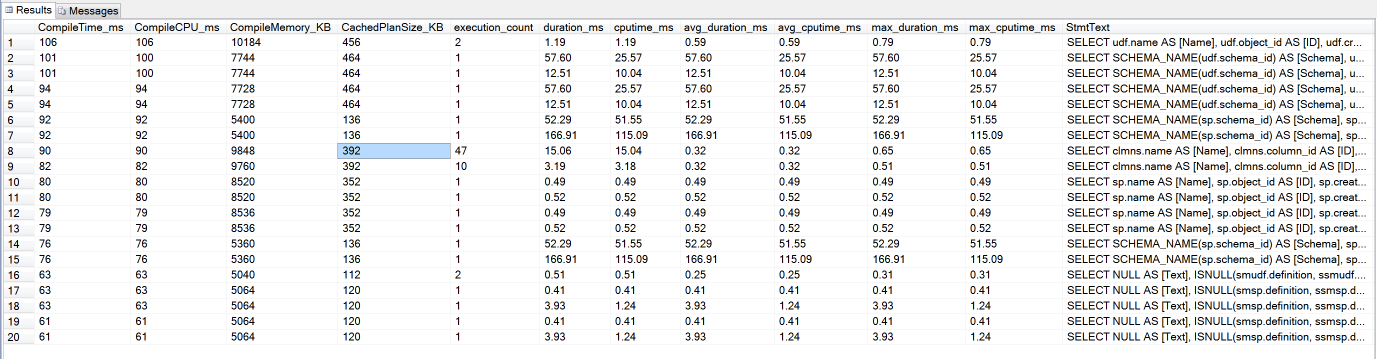
把前四个字段数据绘制成一张图表,如下所示: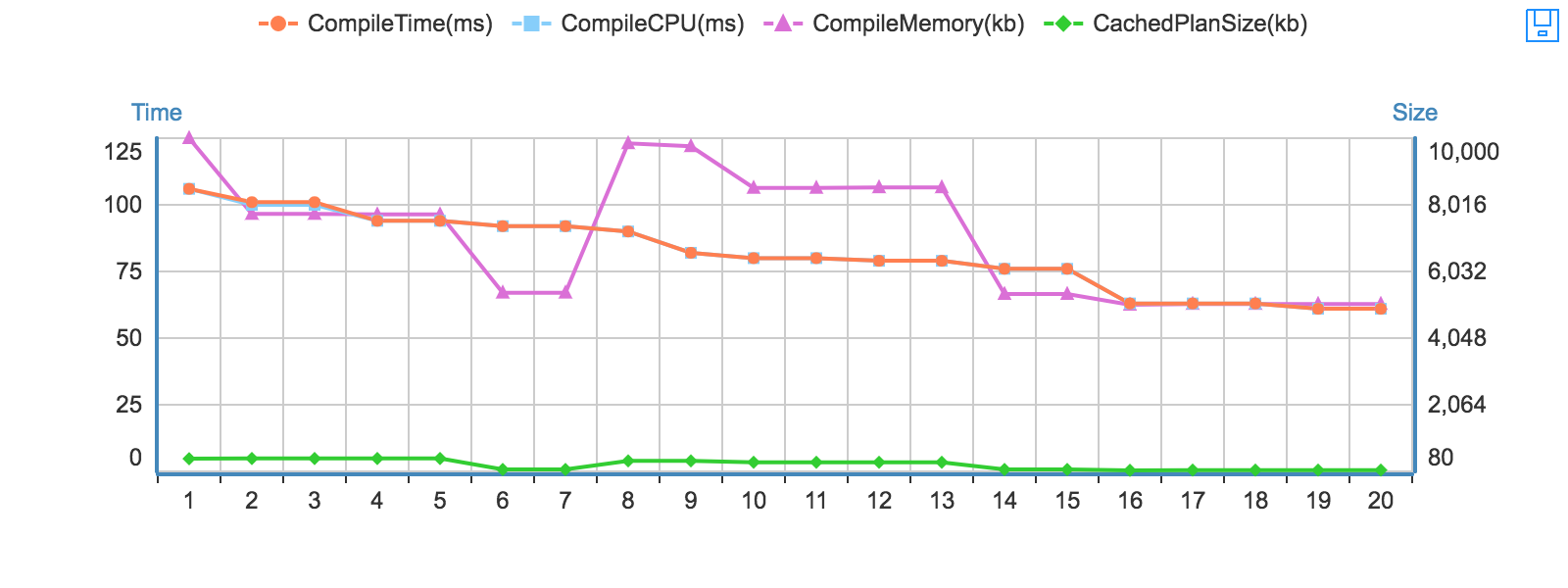
最后总结
SQL Server执行计划缓存中蕴含大量有价值信息,从中统计查询语句编译性能消耗就是其中有价值信息之一。这篇文章提供了一种非常简单的方法来统计查询语句编译带来的各个性能指标开销。