1.12 研究热点
下面从社区问答系统的三个元素(问题、答案、社区)出发,对当前的研究热点进行简单介绍。表 1列出了社区问答系统中比较具有代表性的研究问题。
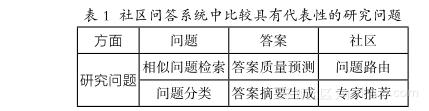
1 . 问题相关研究
(1) 相似问题检索
相似问题检索(Question Retrieval)是指给定用户提交的查询问题(Queried Question),从已有历史问题答案库中,检索出与查询问题在语义上相同或相似的历史问题(Historical Question),并将这些问题及其答案返给用户。如果用户能很快找到满意的相似问题及其答案,这样不但可满足用户的信息需求,节省用户的等待时间,提高系统的用户体检,而且还可以避免用户的重复提交。因此,对相似问题检索进行深入研究具有非常重要的意义。相似问题检索所面临的最大挑战是解决查询问题与历史问题之间的词汇鸿沟问题[1-2] 。在已有研究工作中,具有代表性的方法主要包括基于翻译建模的检索模型[2-3] 、基于话题建模的检索模型[4-5] 、基于结构建模的检索模型 [6-7] 、基于深度学习的检索模型[8-10] 。除了缓解相似问题检索中词汇鸿沟的问题,还有一些研究工作[11-14] 提出不同的方法,利用问题的叶子类别信息,增强相似问题检索的性能。
(2) 问题分类
问题分类(Question Classification)作为挖掘社区问答系统中用户查询问题意图的重要手段,引起了广泛的研究。许多研究人员根据不同的任务需求,定义不同的分类目标,对问题进行分类。Li 等人在文献 [15]中将问题的主客观判断定义为一个分类任务。Liu 等人在文献 [16] 中将问题的紧急性判断定义为一个分类任务。Pal 等人在文献 [17] 中将问题答案对的期效性定义为一个分类任务。Cai 等人在文献 [18] 中提出将问题分类到社区问答系统中预定的层次分类体系中。
2 . 答案相关研究
(1) 答案质量预测
由于社区问答系统的开放性,问题和答案均由用户产生,内容质量参差不齐。能否自动从众多的候选答案中检测出高质量答案,将直接影响用户体验。通常,答案质量预测(Answer Quality Prediction)被描述为分类问题,所抽取的特征包括内容的文本特征、用户活跃度等非文本特征。常用的分类器包括最大熵模型[19] 、决策树[20]以及层次分类器[21-22] 。
(2) 答案摘要生成
在社区问答系统中,通常一个问题只有一个最佳答案,并且该最佳答案由提问者从用户回答的多个答案中选出或者由社区用户投票产生。然而,Liu等人在文献[23]中的分析表明,尽管大多数选出的最佳答案是可重用的,但其中有近乎一半并非唯一的最佳答案;特别是开放性问题和观点性问题通常会有多个比较好的答案。为了充分利用其他用户给出的答案,更全面地满足提问者的信息需求,文献 [23] 利用自动文摘技术对问题的多个答案进行摘要生成,并针对不同类型的问题提出了不同的摘要生成方法。Tang 等人在文献 [24] 中提出了一个最大覆盖模型,对答案进行摘要生成。Sakai 等人在文献 [25]中利用自动文摘和自动问答评价技术,提出了包含多个评价标准和分级相关的分级体系。
3 . 社区相关研究
(1) 问题路由
问题路由是将提问者新提交的问题推送给潜在的对该问题有兴趣,并最有可能提供答案的回答用户来回答,从而使新提交问题能够在较短的时间内得到回答。问题路由的关键在于如何对用户的专业知识进行建模。传统的思路主要考虑使用用户曾经回答过的所有问题来衡量用户的专业知识,并分别提出了基于语言模型建模的方法[26] 、基于话题建模的方法 [27-28] 。此外,Zhou 等人在文献 [29] 中将问题路由看成一个分类任务,即确定一个用户是否有能力回答当前问题。Ji等人在文献 [30] 中利用回答者与提问者之间的偏序关系,提出了一种基于排序学习的问题路由方法。而 Xu等人在文献 [28] 中系统考虑了不同用户角色对结果的影响。考虑到用户的专业知识及其兴趣会随着时间的推移发生变化,Yeniterzi 等人在文献 [31] 中首次提出一种动态的用户建模方法来进行问题路由。
(2) 专家推荐
专家推荐(Expert Recommendation)是从众多的专家用户中,找出能够对提问者新提交问题提供比较高质量、完整并且可信的答案的用户,并且将新提交问题推送给这些排名靠前的专家用户去回答,从而使提问者能够得到满意的答案。专家推荐与问题路由明显不同的是,此时的任务重点强调挖掘社区用户中的专家用户以向提问者的问题提供高质量的答案;而问题路由的任务重点则强调挖掘社区用户中的所有潜在回答者以使得提问者的问题在较短的时间得到回答,但不一定是高质量的答案。前者强调答案的质量,而后者则更强调回答的时效性。Liu 等人在文献 [32] 中首次提出该研究问题,并提出将查询似然语言模型和基于话题建模的模型进行结合,同时融入了用户权威度和用户活跃度信息来将问题推送给排名靠前的专家用户来回答。Riahi 等人在文献 [33] 中提出了一个新的话题模型,对用户的配置文件进行建模,并使用该模型将新问题推送给专家用户来回答。Yang等人在文献[34]
中使用问题的标签信息对用户进行建模,并取得了非常有效的专家推荐性能。