3.3.1 文档类型定义
提供DTD的方式有多种。可以像下面这样将其纳入到XML文档中:
正如你看到的,这些规则被纳入到DOCTYPE声明中,位于由[...]限定界限的块中。文档类型必须匹配根元素的名字,比如我们例子中的conf?iguration。
在XML文档内部提供DTD不是很普遍,因为DTD会使文件长度变得很长。把DTD存储在外部会更具意义,SYSTEM声明可以用来实现这个目标。你可以指定一个包含DTD的URL,例如:
或者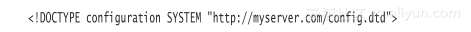
警告:如果你使用的是DTD的相对URL(比如"conf?ig.dtd"),那么要给解析器一个File或URL对象,而不是InputStream。如果必须从一个输入流来解析,那么请提供一个实体解析器(请看下面的说明)。
最后,有一个来源于SGML的用于识别“众所周知的”DTD的机制,下面是一个例子:
如果XML处理器知道如何定位带有公共标识符的DTD,那么就不需要URL了。
注意:如果你使用的是DOM解析器,并且想要支持PUBLIC标识符,请调用DocumentBuilder类的setEntityResolver方法来安装EntityResolver接口的某个实现类的一个对象。该接口只有一个方法:resolveEntity。下面是一个典型实现的代码框架:
你可以从InputStream、Reader或字符串中构建输入源。
既然你已经知道解析器怎样定位DTD了,那么下面就让我们来看看不同类型的规则。
ELEMENT规则用于指定某个元素可以拥有什么样的子元素。可以指定一个正则表达式,它由表3-1中所示的组成部分构成。
下面是一些简单而典型的例子。下面的规则声明了menu元素包含0或多个item元素:
下面这组规则声明font是用一个name后跟一个size来描述的,它们都包含文本:
缩写PCDATA表示被解析的字符数据。这些数据之所以被称为“被解析的”是因为解析器通过寻找表示一个新标签起始的<字符或表示一个实体起始的&字符,来解释这些文本字符串。
元素的规格说明可以包含嵌套的和复杂的正则表达式,例如,下面是一个描述了本书中每一章的结构的规则:
每章都以简介开头,其后是1或多个小节,每个小节由一个标题和1个或多个段落、图片、表格或说明构成。
然而,有一种常见的情况是无法把规则定义得像你希望的那样灵活的。当一个元素可以包含文本时,那么就只有两种合法的情况。要么该元素只包含文本,比如:
要么该元素包含任意顺序的文本和标签的组合,比如:
指定其他任何类型的包含#PCDATA的规则都是不合法的。例如,以下规则是非法的:
必须重写这项规则,以引入另一个caption元素或者允许使用image元素和文本的任意组合。
这种限制简化了XML解析器在解析混合式内容(标签和文本的混合)时的工作。因为在允许使用混合式内容时难免会失控,所以最好在设计DTD时,让其中所有的元素要么包含其他元素,要么只有文本。
注意:实际上,在DTD规则中并不能为元素指定任意的正则表达式,XML解析器会拒绝某些导致非确定性的复杂规则。例如,正则表达式((x,y)|(x,z))就是非确定性的。当解析器看到x时,它不知道在两个选择中应该选取哪一个。这个表达式可以改写成确定性的形式,如(x,(y|z))。然而,有一些表达式不能被改写,如((x,y)*|x?)。Java XML库中的解析器在遇到有歧义的DTD时,不会给出警告。在解析时,它仅仅在两者中选取第一个匹配项,这将导致它会拒绝一些正确的输入。当然,解析器有权这么做,因为XML标准允许解析器假设DTD都是非二义性的。在实际应用中,这不是一个会让你睡不着觉的问题,因为大多数DTD都非常简单,根本不会遇上二义性问题。
还可以指定描述合法的元素属性的规则,其通用语法为:
表3-2显示了合法的属性类型(type),表3-3显示了属性默认值(default)的语法。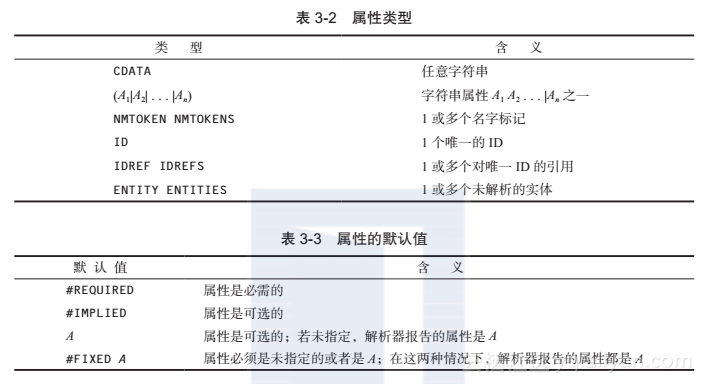
以下是两个典型的属性规格说明:
第一个规格说明描述了font元素的style属性。它有4个合法的属性值,默认值是plain。第二个规格说明表示size元素的unit属性可以包含任意的字符数据序列。
注意:一般情况下,我们推荐用元素而非属性来描述数据。按照这个推荐,font style应该是一个独立的元素,例如...。然而,对于枚举类型,属性有一个不可否认的优点,那就是解析器能够校验其取值是否合法。例如,如果font style是一个属性,那么解析器就会检查它是不是4个允许的值之一,并且如果没有为其提供属性值,那么解析器还会为其提供一个默认值。
CDATA属性值的处理与你前面看到的对#PCDATA的处理有着微妙的差别,并且与<![CDATA[...]]>部分没有多大关系。属性值首先被规范化,也就是说,解析器要先处理对字符和实体的引用(比如é或<),并且要用空格来替换空白字符。
NMTOKEN(即名字标记)与CDATA相似,但是大多数非字母数字字符和内部的空白字符是不允许使用的,而且解析器会删除起始和结尾的空白字符。NMTOKENS是一个以空白字符分隔的名字标记列表。
ID结构是很有用的,ID是在文档中必须唯一的名字标记,解析器会检查其唯一性。在下一个示例程序中,你会看到它的应用。IDREF是对同一文档中已存在的ID的引用,解析器也会对它进行检查。IDREFS是以空白字符分隔的ID引用的列表。
ENTITY属性值将引用一个“未解析的外部实体”。这是从SGML那里沿用下来的,在实际应用中很少见到。在http://www.xml.com/axml/axml.html处的被注解的XML规范中有该属性的一个例子。
DTD也可以定义实体,或者定义解析过程中被替换的缩写。你可以在Firefox浏览器的用户界面描述中找到一个很好的使用实体的例子。这些描述被格式化为XML格式,包含了如下的实体定义:
其他地方的文本可以包含对这个实体的引用,例如: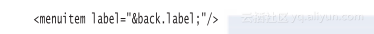
解析器会用替代字符串来替换该实体引用。如果要对应用程序进行国际化处理,只需修改实体定义中的字符串即可。其他的实体使用方法更加复杂,且不太常用,详细说明参见XML规范。
这样我们就结束了对DTD的介绍。既然你已经知道如何使用DTD了,那么你就可以配置你的解析器以充分利用它们了。首先,通知文档生成工厂打开验证特性。
这样,生成器将不会报告文本节点中的空白字符。这意味着,你可以依赖font节点拥有2个子元素这一事实。你再也不用编写下面这样的单调冗长的循环代码了:

而只需仅仅通过如下代码访问第一个和第二个子元素:
这就是DTD如此有用的原因。你不会为了检查规则而使程序负担过重。在得到文档之前,解析器已经做完了这些工作。
提示:许多刚开始使用XML的程序员都对验证不习惯,并且最终还是在程序运行过程中分析DOM树。如果要说服你的同事让他们信服使用验证过的文档所带来的好处,那么就给他们看上述两种不同的编码方式,这样才能使他们相信你。
当解析器报告错误时,应用程序希望对该错误执行某些操作。例如,记录到日志中,把它显示给用户,或是抛出一个异常以放弃解析。因此,只要使用验证,就应该安装一个错误处理器,这需要提供一个实现了ErrorHandler接口的对象。这个接口有三个方法: