在今天的文章中,我们将共同了解十三款机器学习框架,这些框架中最值得关注的特性,在于它们正致力于通过简单而新颖的方式应对与机器学习相关的种种挑战。
过去几年以来,机器学习已经开始以前所未有的方式步入主流层面。这种趋势并非单纯由低成本云环境乃至极为强大的GPU硬件所推动; 除此之外,面向机器学习的可用框架也迎来了爆发式增长。此类框架全部为开源成果,但更重要的是它们在设计方面将最为复杂的部分从机器学习中抽象了出来,从而保证相关技术方案能够为更多开发人员服务。

在今天的文章中,我们将共同了解十三款机器学习框架,一部分去年刚刚发布、另一部分则在不久前进行了全部升级。而这些框架中最值得关注的特性,在于它们正致力于通过简单而新颖的方式应对与机器学习相关的种种挑战。
Apache Spark MLlib
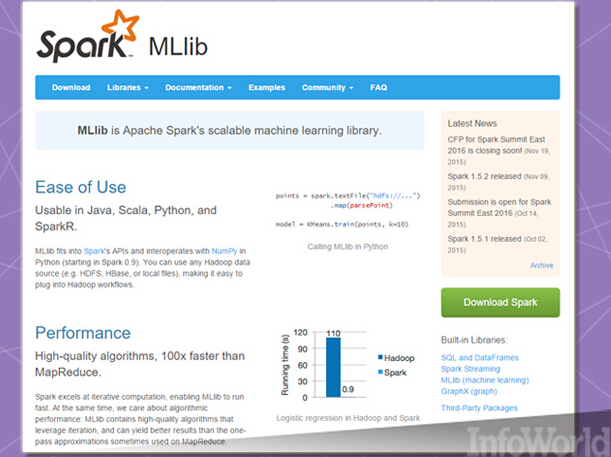
Apache Spark可能算得上当前Hadoop家族当中最为耀眼的成员,但这套内存内数据处理框架在诞生之初实际与Hadoop并无关系,且凭借着自身出色的特性在Hadoop生态系统之外闯出一片天地。Spark目前已经成为一款即时可用的机器学习工具,这主要归功于其能够以高速将算法库应用至内存内数据当中。
Spark仍处于不断发展当中,而Spark当中的可用算法亦在持续增加及改进。去年的1.5版本添加了众多新算法,对现有算法做出改进,同时进一步通过持续流程恢复了MLlib中的Spark ML任务。
Apache Singa
这套“深层学习”框架能够支持多种高强度机器学习功能,具体包括自然语言处理与图像识别。Singa最近被纳入Apache孵化器项目,这套开源框架致力于降低大规模数据的深层学习模型训练难度。
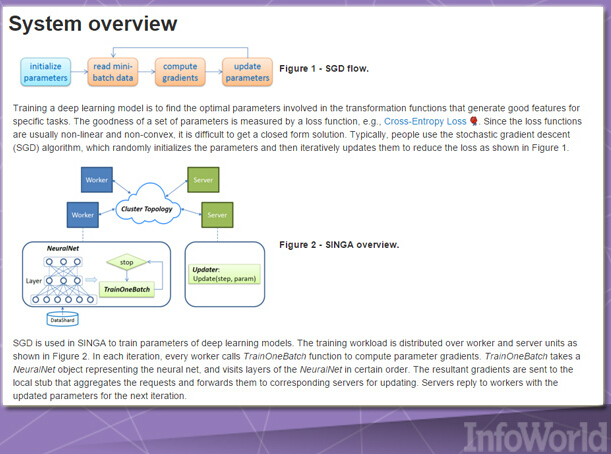
Singa提供一套简单的编程模式,用于跨越一整套设备集群进行深层学习网络训练,同时支持多种常规训练任务类型; 卷积神经网络、受限玻尔兹曼机与复发性神经网络。各模型能够进行同步(一一)或者异步(并行)训练,具体取决于实际问题的具体需求。Singa还利用Apache Zookeeper对集群设置进行了简化。
Caffe
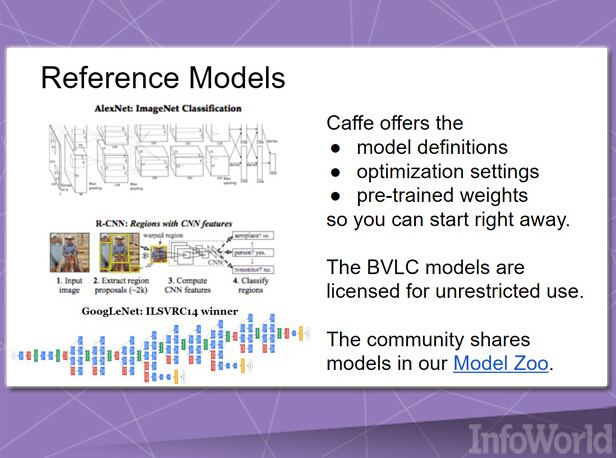
深层学习框架Caffe是一套“立足于表达、速度与模块化”的解决方案。其最初诞生于2013年,主要用于机器视觉项目。Caffe自出现之后就一直将多种其它应用囊括入自身,包括语音与多媒体。
由于优先考量速度需求,因此Caffe全部利用C++编写而成,同时支持CUDA加速机制。不过它也能够根据需要在CPU与GPU处理流程间往来切换。其发行版中包含一系列免费与开源参考模型,主要面向各类常规典型任务; 目前Caffe用户社区亦在积极开发其它模型。
微软Azure ML Studio
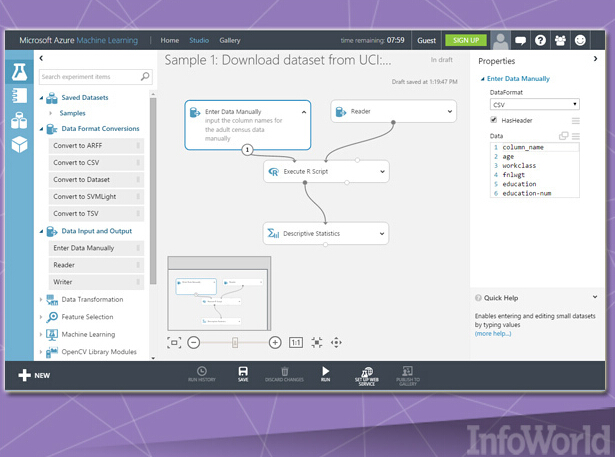
根据机器学习任务的实际数据规模与计算性能需求,云往往能够成为机器学习应用的一大理想运行环境。微软公司已经立足于Azure发布了其按需计费机器学习服务,即Azure ML Studio,其能够提供按月、按小时以及免费等分层版本。(微软公司的HowOldRobot项目亦利用这套系统创建而成。)
Azure ML Studio允许用户创建并训练模型,而后将其转化为能够由其它服务消费的API。每个用户账户能够为模型数据提供最高10 GB存储容量,不过大家也可以将自己的Azure存储资源连接至服务当中以承载规模更大的模型。目前可用算法已经相当可观,其分别由微软自身以及其它第三方所提供。大家甚至不需要账户即可体验这项服务; 用户可以匿名登录并最多使用八小时Azure ML Studio。
Amazon Machine Learning
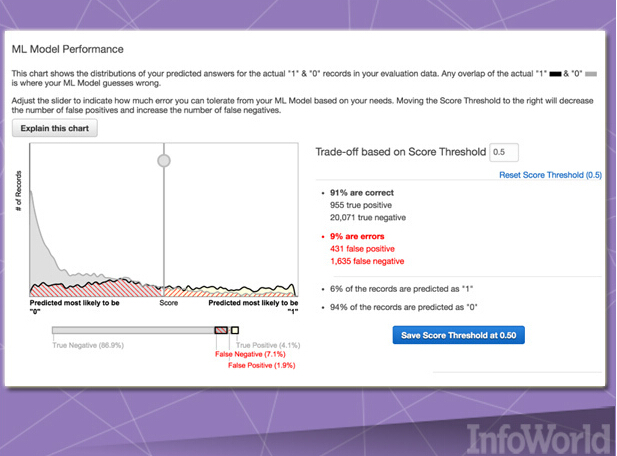
Amazon的这套面向云服务的通用型方案遵循既定模式。其提供核心用户最为关注的运行基础,帮助他们立足于此寻求自身最需要的机器学习方案并加以交付。
Amazon Machine Learning同时也是云巨头首次尝试推出机器学习即服务方案。它能够接入被保存在Amazon S3、Redshift或者RDS当中的数据,并能够运行二进制分类、多类分类或者数据递归以创建模型。然而,该服务高度依赖于Amazon本身。除了要求数据必须被存储于Amazon之内之外,其结果模型也无法进行导入与导出,另外训练模型的数据库集亦不可超过100 GB。当然,这只是Amazon Machine Learning的起步成效,其也足以证明机器学习完全具备可行性——而非技术巨头的奢侈玩物。
微软分布式机器学习工具包
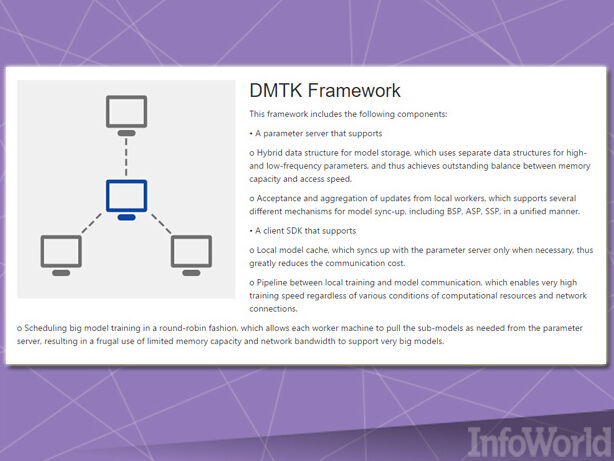
我们用于解决机器学习难题的设备数量越多,实际效果就越好——但将大量设备汇聚起来并开发出能够顺利跨越各设备运行的机器学习应用绝非易事。微软的DMTK(即分布式机器学习工具包)框架则能够轻松跨越一整套系统集群解决多种机器学习任务类型的分发难题。
DMTK的计费机制归属于框架而非完整的开箱即用解决方案,因此其中实际涉及的算法数量相对较小。不过DMTK在设计上允许用户进行后续扩展,同时发挥现有集群之内的有限资源。举例来说,集群中的每个节点都拥有一套本地缓存,其能够由中央服务器节点为当前任务提供参数,从而降低实际流量规模。
谷歌TensorFlow
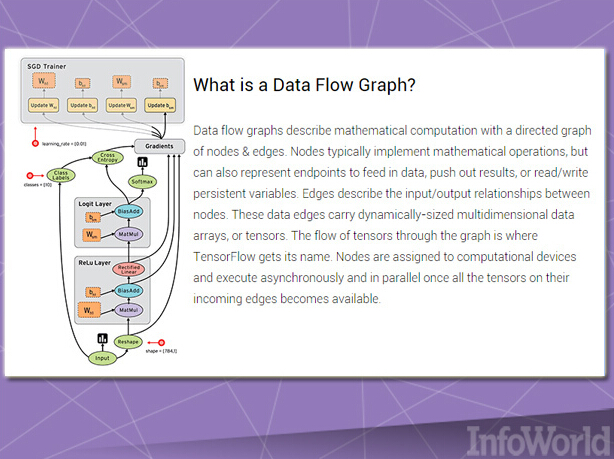
与微软的DMTK类似,谷歌TensorFlow是一套专门面向多节点规模设计而成的机器学习框架。与谷歌的Kubernetes类似,TensorFlow最初也是为谷歌内部需求所量身打造,但谷歌公司最终决定将其以开源产品进行发布。
TensorFlow能够实现所谓数据流图谱,其中批量数据(即‘tensor’,意为张量)可通过一系列由图谱描述的算法进行处理。系统之内往来移动的数据被称为“流”,可由CPU或者GPU负责处理。谷歌公司的长期规划在于通过第三方贡献者推动TensorFlow项目的后续发展。
微软计算网络工具包
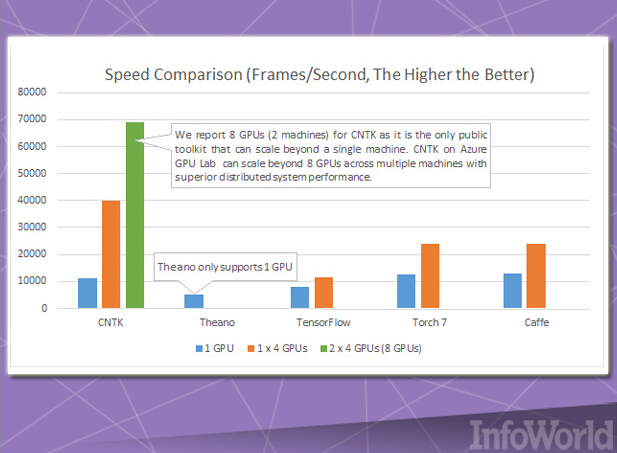
趁着DMTK的推出良机,微软公司还发布了另一套机器学习工具包,即计算网络工具包——或者简称CNTK。
CNTK与谷歌TensorFlow非常类似,因为它允许用户通过有向图的方式建立神经网络。另外,微软还将其视为可与Caffe、Theano以及Torch等项目相媲美的技术成果。它的主要亮点在于出色的速度表现,特别是以并行方式利用多CPU与多GPU的能力。微软公司宣称,其利用CNTK与Azure之上的GPU集群共同将Cortana语音识别服务训练的速度提升到了新的数量级。
最初作为微软语音识别项目组成部分开发而成的CNTK,最终于2015年4月以开源项目形式走向公众视野——但其随后以更为宽松的MIT类别许可在GitHub进行了重新发布。
Veles (三星)
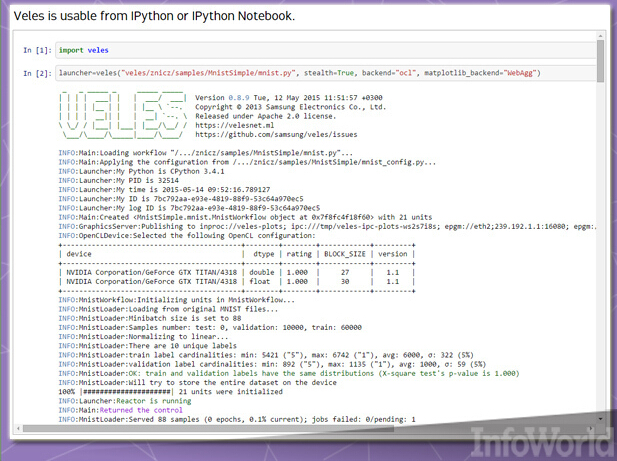
Veles是一套面向深层学习应用程序的分布式平台,而且与TensorFlow与DMTK一样,它也由C++编写而成——不过它利用Python在不同节点之间执行自动化与协作任务。相关数据集可在被供给至该集群之前经过分析与自动标准化调整,另外其还具备REST API以允许将各已训练模型立即添加至生产环境当中(假设大家的硬件已经准备就绪)。
Veles并非单纯利用Python作为其粘合代码。IPython(如今已被更名为Jupyter)数据可视化与分析工具能够对来自Veles集群的结果进行可视化处理与发布。三星公司希望能够将该项目以开源形式发布,从而推进其进一步发展——例如面向Windows与Mac OS X。
Brainstorm
作为瑞士卢加诺博士生Klaus Greff于2015年开发的技术成果,Brainstorm项目的目标在于“帮助深层神经网络实现高速、灵活与趣味性。”目前其已经包含有一系列常见神经网络模型,例如LSTM。
Brainstorm采用Python代码以提供两套“hander”,或者称之为数据管理API——其一来自Numpy库以实现CPU计算,其二通过CUDA使用GPU资源。大部分工作由Python脚本完成,所以各位没办法指望其提供丰富的GUI前端——大家需要自己动手接入相关界面。不过从长期规划角度看,其能够使用“源自多种早期开源项目的学习经验”,同时利用“能够与多种平台及计算后端相兼容的新的设计元素。”
mlpack 2
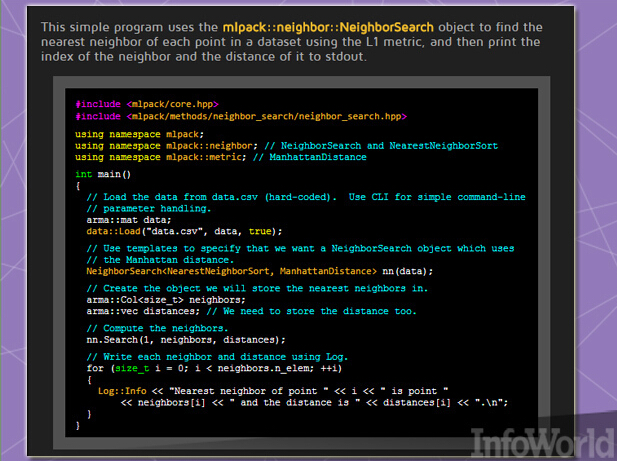
mlpack这套基于C++的机器学习库最初诞生于2011年,其设计倾向为“可扩展性、速度性与易用性,”该库构建者们指出。用户可以通过命令行可执行缓存运行mlpack以实现快速运行、“黑盒”操作或者通过C++ API完成其它更为复杂的任务。
其2.0版本则拥有一系列重构与新特性,其中包括多种新算法,并对现有算法加以修改以提升运行速度或者缩小其体积。举例来说,它能够将Boost库的随机数生成器指向C++ 11的原生随机功能。
mlpack的固有劣势在于其缺乏除C++之外的任何其它语言绑定能力,这意味着从R语言到Python语言的各类其他用户都无法使用mlpack——除非其他开发者推出了自己的对应语言软件包。目前该项目正积极添加对MatLab的支持能力,不过此类项目一般更倾向于直接面向各承载机器学习任务的主流环境。
Marvin

作为另一套刚刚诞生的方案,Marvin神经网络框架为Princeton Vision集团的开发成果。它可谓“为hack而生”,因为项目开发者们在其说明文档当中直接做出这样的描述,且仅仅依赖于C++编写的数个文件及CUDA GPU框架即可运行。尽管其代码本身的体积非常小巧,但其中仍然存在相当一部分能够复用的部分,并可以将pull请求作为项目自身代码进行贡献。
Neon
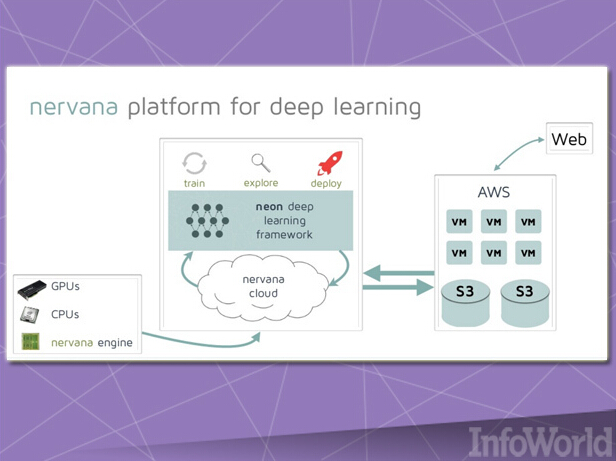
Nervana公司专门构建自己的深层学习硬件与软件平台,其推出了一套名为Neon的深层学习框架,并将其作为开源项目。该项目利用可插拔模块以支持高强度负载在CPU、GPU或者Nervana自有定制化硬件上运行。
Neon主要由Python语言编写而成,C++为其编写了多条代码片段并带来可观的运行速度。这样的特性让Neon立即成为各Python开发之数据科学场景或者其它绑定Python之框架的理想解决方案。
