
Python 垃圾回收机制
内存管理
Python中的内存管理机制的层次结构提供了4层,其中最底层则是C运行的malloc和free接口,往上的三层才是由Python实现并且维护的,第一层则是在第0层的基础之上对其提供的接口进行了统一的封装,因为每个系统都可能差异性。

内存池
Python为了避免频繁的申请和删除内存所造成系统切换于用户态和核心态的性能问题,从而引入了内存池机制,专门用来管理小内存的申请和释放。内存池分为四层:block、pool、arena和内存池。如下图:
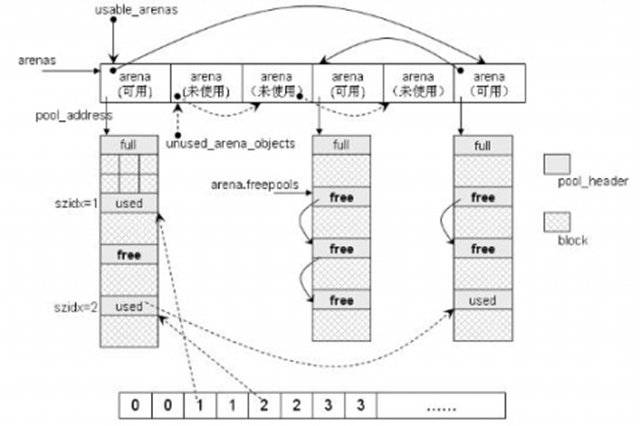
block:有很多种block,不同种类的block都有不同的内存大小,申请内存的时候只需要找到适合自身大小的block即可,当然申请的内存也是存在一个上限,如果超过这个上限,则退化到使用最底层的malloc进行申请。
pool:一个pool管理着一堆有固定大小的内存块,其大小通常为一个系统内存页的大小。
arena:多个pool组合成一个arena。
内存池:一个整体的概念。
垃圾回收
Python的GC模块主要运用了引用计数来跟踪和回收垃圾。在引用计数的基础上,还可以通过“标记-清除”解决容器对象可能产生的循环引用的问题。通过分代回收以空间换取时间进一步提高垃圾回收的效率。
引用计数
原理:当一个对象的引用被创建或者复制时,对象的引用计数加1;当一个对象的引用被销毁时,对象的引用计数减1,当对象的引用计数减少为0时,就意味着对象已经再没有被使用了,可以将其内存释放掉。
优点:引用计数有一个很大的优点,即实时性,任何内存,一旦没有指向它的引用,就会被立即回收,而其他的垃圾收集技术必须在某种特殊条件下才能进行无效内存的回收。
缺点:但是它也有弱点,引用计数机制所带来的维护引用计数的额外操作与Python运行中所进行的内存分配和释放,引用赋值的次数是成正比的,这显然比其它那些垃圾收集技术所带来的额外操作只是与待回收的内存数量有关的效率要高。同时,引用技术还存在另外一个很大的问题-循环引用,因为对象之间相互引用,每个对象的引用都不会为0,所以这些对象所占用的内存始终都不会被释放掉。如下:
标记-清除
标记-清除的出现打破了循环引用,也就是它只关注那些可能会产生循环引用的对象,显然,像是PyIntObject、PyStringObject这些不可变对象是不可能产生循环引用的,因为它们内部不可能持有其它对象的引用。Python中的循环引用总是发生在container对象之间,也就是能够在内部持有其它对象的对象,比如list、dict、class等等。这也使得该方法带来的开销只依赖于container对象的的数量。
原理:将集合中对象的引用计数复制一份副本,这个计数副本的作用是寻找root object集合(该集合中的对象是不能被回收的)。当成功寻找到root object集合之后,首先将现在的内存链表一分为二,一条链表中维护root object集合,成为root链表,而另外一条链表中维护剩下的对象,成为unreachable链表。一旦在标记的过程中,发现现在的unreachable可能存在被root链表中直接或间接引用的对象,就将其从unreachable链表中移到root链表中;当完成标记后,unreachable链表中剩下的所有对象就是名副其实的垃圾对象了,接下来的垃圾回收只需限制在unreachable链表中即可。
缺点:该机制所带来的额外操作和需要回收的内存块成正比。
分代
原理:将系统中的所有内存块根据其存活时间划分为不同的集合,每一个集合就成为一个“代”,垃圾收集的频率随着“代”的存活时间的增大而减小。也就是说,活得越长的对象,就越不可能是垃圾,就应该减少对它的垃圾收集频率。那么如何来衡量这个存活时间:通常是利用几次垃圾收集动作来衡量,如果一个对象经过的垃圾收集次数越多,可以得出:该对象存活时间就越长。
本文作者:banananana
来源:51CTO