![]()
python包索引(PyPI)提供了超过10万个代码库的包,它能够帮助python程序员完成许多工作,无论是构建web应用程序还是分析数据。另外PyPI还提供了很多诸如 twilio 之类的API的辅助库。
下面让我们通过使用4个不同的 Python HTTP 库来学习如何从 RESTful API 检索和解析 JSON 数据,以此来演示PyPI包的强大功能。
文中的每个示例都包含以下内容:
- 定义要解析的URL,我们将使用Spotify API,因为它不需要在请求时进行身份验证。
- 创建一个 HTTP GET 去请求这个URL。
- 解析返回的JSON数据。
我们将要使用的四个库用了不同的方法得到同一个结果。如果你把结果输出,将会看到一个有Spotify搜索结果的字典:
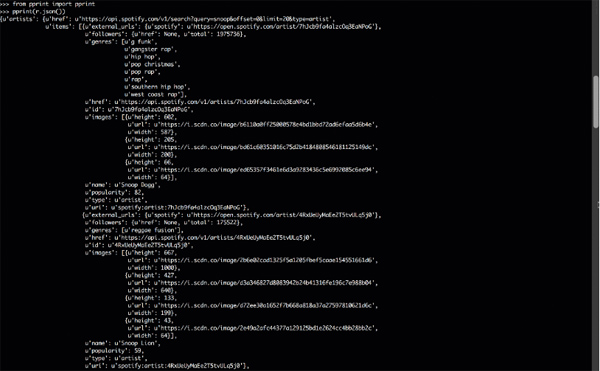
*注意:结果可能会根据你使用的Python版本而有所不同。在这篇文章中,所有的代码都使用Python 3编写。 如果你仍在使用Python 2.X,那么请考虑为Python 3设置一个virtualenv。
以下说明将帮助您使用virtualenv与Python 3:
- 为Python 3测试创建一个名为pythreetest的目录。
- 一旦安装了virtualenv,从项目目录中执行以下命令:
使用以下命令创建一个新的virtualenv:
- virtualenv -p python3 myvenv
使用source命令激活myvenv:
- source myvenv/bin/activate
现在你将能够使用pip安装需要的库,并在virtualenv中使用Python 3启动解释器,在那里您可以成功导入包。
urllib
urllib是一个内置在Python标准库中的模块,并使用http.client来实现HTTP和HTTPS协议的客户端。
由于urllib是同Python一起进行分发和安装的,因此无需使用 pip 进行安装。 如果你重视稳定性,那么这就是给你准备的。
twilio-python助手库就使用了urllib。
urllib同其他库比起来需要做更多的工作。 例如:你必须在发出HTTP请求之前创建一个URL对象。
- import urllib.request
- import urllib.parse
- url = 'https://api.spotify.com/v1/search?type=artist&q=snoop'
- f = urllib.request.urlopen(url)
- print(f.read().decode('utf-8'))
在上面的例子中,我们将请求URL发送到CGI的stdin,并读取返回给我们的数据。
Requests
Requests是Python社区中最喜欢的库,因为它简洁易用。 Requests由urllib3提供支持,有玩笑说这是“唯一的非转基因HTTP库,适合人类消费”。
Requests 抽象了大量的程式化的代码,使得HTTP请求比使用内置urllib库更简单。
首先用pip进行安装
- pip install requests
向 Spotify 发送请求
- import requests
- r = requests.get('https://api.spotify.com/v1/search?type=artist&q=snoop')
- r.json()
输出结果:
- from pprint import pprint
- pprint(r.json())
我们刚刚向Spotify发出了一个GET请求,同时创建了一个名为r的Response 对象,之后使用内置的JSON解码器来处理我们请求的内容。
Octopus
Octopus是为想要GET一切的开发人员准备的。它允许你多任务去访问Spotify。就像它的名字一样,这个库使用线程并发地检索和报告HTTP请求的完成情况,同时可以使用你所熟悉的库。
或者,你可以使用 Tornado 的 IOLoop 进行异步请求,不过在这里就不尽兴尝试了。
通过pip安装:
- pip install octopus-http
Octopus的设置比前面的例子稍微多一些。 我们必须构建一个响应处理器,并使用内置的JSON库对JSON进行编码。
- import json
- from pprint import pprint
- from octopus import Octopus
- def create_request(urls):
- data = []
- otto = Octopus(
- concurrency=4, auto_start=True, cache=True, expiration_in_seconds=10
- )
- def handle_url_response(url, response):
- if "Not found" == response.text:
- print ("URL Not Found: %s" % url)
- else:
- data.append(response.text)
- for url in urls:
- otto.enqueue(url, handle_url_response)
- otto.wait()
- json_data = json.JSONEncoder(indent=None,
- separators=(',', ': ')).encode(data)
- return pprint(json_data)
- print(create_request(['https://api.spotify.com/v1/search?type=artist&q=snoop',
- 'https://api.spotify.com/v1/search?type=artist&q=dre']))
在上面的代码片段中,我们定义了create_requests函数来使用线程Octopus请求。 我们从一个空的list开始,data,并创建Octopus类的一个实例dotto。 最后配置了默认设置。
然后我们构建响应处理器,其中的response参数是Octopus.Response的一个实例。 当每个请求成功后,响应内容将被添加到数据列表中。在响应处理器内部,我们可以使用Octopus类的主要方法。.enqueue方法用于加入新的URL。
我们指定.wait方法等待队列中的所有URL完成加载,然后对JSON列表进行JSON编码并打印结果。
吁,终于结束了。

HTTPie
HTTPie适用于希望快速与HTTP服务器、RESTful API 和 Web 服务进行交互的开发人员,它仅仅需要一行代码。
这个库是“一个可以让你微笑的开源 CLI HTTP客户端:用户友好的 curl
替代方案”。虽然它可以不依赖Python环境,但是它可以通过Pip安装,并用来创建HTTP请求。
- pip install httpie
默认协议是HTTP,但您可以创建一个别名,并重置HTTPS为默认值,如下所示:
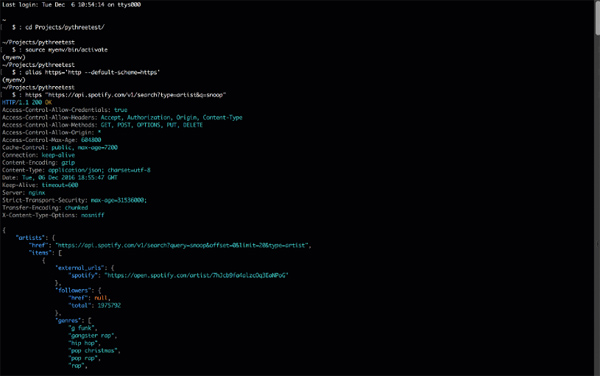
- alias https='http —default-scheme=https'
之后创建请求:
- https "https://api.spotify.com/v1/search?type=artist&q=snoop"
使用HTTPie仅需要URL就够了。
最后的想法
Python 生态提供了许多与 JSON api 交互的选择。虽然这些方法对于最简单的请求是相似的, 但随着 HTTP 请求的复杂性增加, 这些差异变得更加明显。多进行尝试, 看看哪一个最适合你的需求。你甚至可以尝试用另一种语言, 如 Ruby。
作者:疯狂的技术宅
来源:51CTO