2.1 用R重写Mahout协同过滤算法
问题
如何用R语言实现推荐算法?
引言
推荐系统在互联网应用中很常见,比如亚马逊为你推荐购书列表,豆瓣为你推荐电影列表。Mahout是Hahoop家族用于机器学习的分步式计算框架,主要包括三类算法,即推荐算法、聚类算法和分类算法。本节将用R语言来重写推荐部分的基于用户的协同过滤算法。用R语言重写Mahout的基于用户的协同过滤推荐算法,将完全按照Mahout的思路和设计进行实现,并与Mahout的计算结果进行对比。
2.1.1 Mahout的推荐算法模型
首先我们需要了解一下,协同过滤算法在Mahout中是如何实现的。Mahout的推荐算法定义了一套标准化的模型构建过程和调用过程,以基于用户的协同过滤算法(UserCF)为例,如图2-1所示。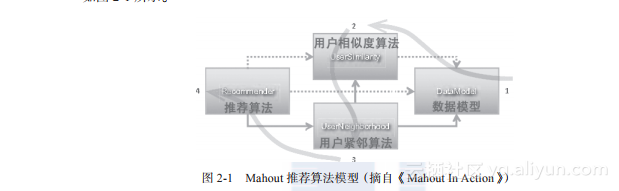
图2-1 Mahout推荐算法模型(摘自《Mahout In Action》)
从图2-1中我们可以看到,基于用户的协同过滤算法是被模块化的,通过4个模块进行统一的方法调用。首先,创建数据模型(DataModel),然后定义用户的相似度算法(UserSimilarity),接下来定义用户近邻算法(UserNeighborhood),最后调用推荐算法(Recommender)完成计算过程。而基于物品的协同过滤算法(ItemCF)过程也是类似的,去掉第三步计算用户的近邻算法就行了。
本节中将用R语言对Mahout的0.5版本算法进行重新实现,下面是Mahout在Maven中版本定义。
org.apache.mahout
mahout-core
0.5
我们选用一组比较简单的测试数据集testCF.csv,数据集分为3列:用户ID、物品ID以及用户对物品的打分。一共21行数据。
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0
我们先看一下如何用Java语言使用Mahout库的API,实现基于用户的协同过滤算法的代码。Java程序实现代码如下所示。
/**
- UserCF测试,单机算法实现程序
*/
public class UserCF {f?inal static int NEIGHBORHOOD_NUM = 2; // 取2个近邻
f?inal static int RECOMMENDER_NUM = 3; // 保留3个推荐结果public static void main(String[] args) throws IOException, TasteException {
String f?ile = "item.csv"; // 读入数据集
DataModel model = new FileDataModel(new File(f?ile)); // 加载数据到内存对象DataModel
UserSimilarity user = new EuclideanDistanceSimilarity(model);
// 定义用户相似度距离
NearestNUserNeighborhood neighbor = new NearestNUserNeighborhood
(NEIGHBORHOOD_NUM, user, model); // 定义近邻
Recommender r = new GenericUserBasedRecommender(model, neighbor, user);
// 创建推荐模型
LongPrimitiveIterator iter = model.getUserIDs(); // 取得用户列表while (iter.hasNext()) { // 循环用户列表,计算给每个用户的推荐结果 long uid = iter.nextLong(); List list = r.recommend(uid, RECOMMENDER_NUM); System.out.printf("uid:%s", uid); for (RecommendedItem ritem : list) { System.out.printf("(%s,%f)", ritem.getItemID(), ritem.getValue()); // 打印推荐结果 } System.out.println(); }}
}
运行Java程序,输出推荐结果。
uid:1(104,4.250000)(106,4.000000)
uid:2(105,3.956999)
uid:3(103,3.185407)(102,2.802432)
uid:4(102,3.000000)
uid:5
对结果的解读如下。
给uid=1的用户,推荐计算得分最高的2个物品,104和106。
给uid=2的用户,推荐计算得分最高的1个物品,105。
给uid=3的用户,推荐计算得分最高的2个物品,103和102。
给uid=4的用户,推荐计算得分最高的1个物品,102。
给uid=5的用户,没有推荐。
2.1.2 R语言模型实现
接下来,我们使用R语言重写Mahout的实现,R语言代码将完全按照Mahout源代码的程序设计思路进行实现。为保证与Java程序思路一致,R代码用了for循环实现,这里暂时不考虑R程序的性能。
用R语言构建算法模型,将按照下面的5个步骤进行:
(1)建立数据模型
(2)欧氏距离相似度算法
(3)用户近邻算法
(4)推荐算法
(5)运行程序
1.?建立数据模型
创建数据模型的函数FileDataModel(),主要用于从CSV文件中读取数据,然后以R语言中矩阵类型(matrix)加载到内存中。
FileDataModel<-function(f?ile){ # 数据模型函数
data<-read.csv(f?ile,header=FALSE) # 读CSV文件到内存
names(data)<-c("uid","iid","pref") # 增加列名user <- unique(data$uid) # 计算用户数
item <- unique(sort(data$iid)) # 计算产品数
uidx <- match(data$uid, user)
iidx <- match(data$iid, item)
M <- matrix(0, length(user), length(item)) # 定义存储矩阵
i <- cbind(uidx, iidx, pref=data$pref)for(n in 1:nrow(i)){ # 给矩阵赋值
M[i[n,][1],i[n,][2]]<-i[n,][3]
}dimnames(M)[[2]]<-item
M # 返回矩阵数据
}
2.?欧氏距离相似度算法
我们在计算用户相似度算法的时候可以有多种选择,如欧氏距离相似度算法、皮尔森相似度算法、余弦相似度算法、Spearman秩相关系数相似度算法、曼哈顿距离相似度算法、对数似然相似度算法等,很多算法都有对应的R语言函数,直接调用就可以了。按照Mahout的代码实现思路,它对于基础的算法做了一些优化,因此我们也需要完全从底层重写这些算法。
下面将以欧氏距离相似度算法为例,创建欧氏距离相似度的计算函数Euclidean-
DistanceSimilarity(),加载用户物品的矩阵数据,通过欧氏距离来计算用户的相似度。
EuclideanDistanceSimilarity<-function(M){
row<-nrow(M)
s<-matrix(0, row, row) # 相似度矩阵for(z1 in 1:row){
for(z2 in 1:row){
if(z1<z2){
num<-intersect(which(M[z1,]!=0),which(M[z2,]!=0)) # 可计算的列sum<-0 for(z3 in num){ sum<-sum+(M[z1,][z3]-M[z2,][z3])^2 } s[z2,z1]<-length(num)/(1+sqrt(sum)) if(s[z2,z1]>1) s[z2,z1]<-1 # 对算法的阈值进行限制 if(s[z2,z1]<-1) s[z2,z1]<- -1}
}
}ts<-t(s) # 补全三角矩阵
w<-which(upper.tri(ts))
s[w]<-ts[w]
s # 返回用户相似度矩阵
}
3.?用户近邻算法
我们在计算用户近邻的时候,也有2种算法来选择。一种是以个数来计算的,选出最近的前几个;另一种是以百分比来计算的,选出最近的前百分之几的数量。下面将以个数计算为例,选出最近的前N个用户。创建最近邻计算的函数NearestNUserNeighborhood(),传入用户的相似度矩阵和个数,就能计算出用户最近邻了。
NearestNUserNeighborhood<-function(S,n){
row<-nrow(S)
neighbor<-matrix(0, row, n)
for(z1 in 1:row){
for(z2 in 1:n){
m<-which.max(S[,z1])
neighbor[z1,][z2]<-m
S[,z1][m]=0
}
}
neighbor # 返回前n个最近邻
}
4.?推荐算法
我们在计算推荐的时候,也有几种算法可以选择,如基于用户的推荐算法、基于物品的推荐算法、slopeOne推荐算法、itemKNN推荐算法、SVD推荐算法、TreeCluster推荐算法,这几种推荐算法要与上面定义的数据和相似度算法进行匹配才能一起使用。
下面我们创建基于用户的推荐算法计算的函数UserBasedRecommender(),通过用户物品数据矩阵、用户相似度矩阵、用户最近邻,按基于用户的协同过滤算法实现,计算出推荐结果。
UserBasedRecommender<-function(uid,n,M,S,N){
row<-ncol(N)
col<-ncol(M)
r<-matrix(0, row, col)
N1<-N[uid,]
for(z1 in 1:length(N1)){
num<-intersect(which(M[uid,]==0),which(M[N1[z1],]!=0)) # 可计算的列
for(z2 in num){
r[z1,z2]=M[N1[z1],z2]*S[uid,N1[z1]]
}
}print(r) # 打印每个用户的推荐矩阵
sum<-colSums(r)
s2<-matrix(0, 2, col)
for(z1 in 1:length(N1)){
num<-intersect(which(colSums(r)!=0),which(M[N1[z1],]!=0))
for(z2 in num){
s2[1,][z2]<-s2[1,][z2]+S[uid,N1[z1]]
s2[2,][z2]<-s2[2,][z2]+1
}
}s2[,which(s2[2,]==1)]=10000
s2<-s2[-2,]r2<-matrix(0, n, 2)
rr<-sum/s2
item <-dimnames(M)[[2]]
for(z1 in 1:n){
w<-which.max(rr)
if(rr[w]>0.5){
r2[z1,1]<-item[which.max(rr)]
r2[z1,2]<-as.double(rr[w])
rr[w]=0
}
}
r2
}
这样基于用户的协同过滤算法的函数,我们都已经用R程序实现了。下面按照调用关系,我们运行这些功能函数。
5.?运行程序FILE<-"item.csv" # 数据文件
NEIGHBORHOOD_NUM<-2 # 取2个最大近邻
RECOMMENDER_NUM<-3 # 保留最多3个推荐结果
M<-FileDataModel(FILE) # 把数据文件,换成矩阵加载到内存
S<-EuclideanDistanceSimilarity(M) # 计算用户相似度矩阵
N<-NearestNUserNeighborhood(S,NEIGHBORHOOD_NUM) # 计算用户近邻R1<-UserBasedRecommender(1,RECOMMENDER_NUM,M,S,N);R1 # 查看对User=1的推荐结果
[,1] [,2]
[1,] "104" "4.25"
[2,] "106" "4"
[3,] "0" "0"
R2<-UserBasedRecommender(2,RECOMMENDER_NUM,M,S,N);R2 # 查看对User=2的推荐结果
[,1] [,2]
[1,] "105" "3.95699903407931"
[2,] "0" "0"
[3,] "0" "0"
R3<-UserBasedRecommender(3,RECOMMENDER_NUM,M,S,N);R3 # 查看对User=3的推荐结果
[,1] [,2]
[1,] "103" "3.18540697329411"
[2,] "102" "2.80243217111765"
[3,] "0" "0"
R4<-UserBasedRecommender(4,RECOMMENDER_NUM,M,S,N);R4 # 查看对User=4的推荐结果
[,1] [,2]
[1,] "102" "3"
[2,] "0" "0"
[3,] "0" "0"
R5<-UserBasedRecommender(5,RECOMMENDER_NUM,M,S,N);R5 # 查看对User=5的推荐结果
[,1] [,2]
[1,] 0 0
[2,] 0 0
[3,] 0 0
最后我们看到计算结果,同调用Mahout的API的Java程序的计算结果是一致的。
2.1.3 算法实现的原理——矩阵变换
那么我们算法实现的原理是什么呢?所谓协同过滤算法,其实就是矩阵变换的结果!请大家下面留意每一步的矩阵变换。从原始数据文件开始,如下所示。
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0
第一步的矩阵变换,通过FileDataModel()函数,输出用户物品矩阵。
101 102 103 104 105 106 107
[1,] 5.0 3.0 2.5 0.0 0.0 0 0
[2,] 2.0 2.5 5.0 2.0 0.0 0 0
[3,] 2.5 0.0 0.0 4.0 4.5 0 5
[4,] 5.0 0.0 3.0 4.5 0.0 4 0
[5,] 4.0 3.0 2.0 4.0 3.5 4 0
第二步,利用欧氏相似度算法进行矩阵变换,运行EuclideanDistanceSimilarity()函数,结果如下所示。
[,1] [,2] [,3] [,4] [,5]
[1,] 0.0000000 0.6076560 0.2857143 1.0000000 1.0000000
[2,] 0.6076560 0.0000000 0.6532633 0.5568464 0.7761999
[3,] 0.2857143 0.6532633 0.0000000 0.5634581 1.0000000
[4,] 1.0000000 0.5568464 0.5634581 0.0000000 1.0000000
[5,] 1.0000000 0.7761999 1.0000000 1.0000000 0.0000000
第三步,通过用户相似度矩阵,计算出用户最近邻,运行EuclideanDistanceSimilarity()函数,结果如下所示。
top1 top2
[1,] 4 5
[2,] 5 3
[3,] 5 2
[4,] 1 5
[5,] 1 3
第四步,把上面的矩阵合并计算,通过基于用户的推荐算法,得到每个用户的推荐矩阵。以uid=1的用户为例,运行UserBasedRecommender()函数,结果如下所示。
101 102 103 104 105 106 107
4 0 0 0 4.5 0.0 4 0
5 0 0 0 4.0 3.5 4 0
打开注释行:UserBasedRecommender()函数的代码注释print(r) #打印每个用户的推荐矩阵。
第五步,过滤推荐矩阵的结果,取前2个得分最高的推荐结果返回。以uid=1的用户为例,结果如下所示。
推荐物品 物品得分
[1,] "104" "4.25"
[2,] "106" "4"
通过这5步矩阵变换,我们就可以清楚地看到基于用户的协同过滤算法的本质了。当然,Mahout所提供的算法。都是以矩阵为基础的可以处理海量数据的算法。如果我们的数据量很小,可以把上面的算法过程优化并改进,降低矩阵计算的复杂度。
2.1.4 算法总结
本节只是用R语言重写了Mahout的基于用户的、欧氏距离相似度、个数最近邻的协同过滤算法,重写其他的算法过程也是类似的。另外,在读Mahout源代码的过程中发现,Mahout做各种算法时,都有自己的优化,并不是简单地套用教课书上的算法公式。比如,计算基于欧氏距离的用户相似度时,并不是标准的欧氏距离算法,而是改进的欧氏距离算法。
similar = 1/(1+sqrt( (a-b)^2 + (a-c)^2 )) # 欧氏距离算法
similar = n/(1+sqrt( (a-b)^2 + (a-c)^2 )) # 改进的欧氏距离算法
公式解释:
a, b是被两个用户都打分的物品,也可能是1个或者多个
n是被两个用户都打分的物品的个数
当similar>1时,则similar=1
当similar<-1时,则similar=-1
通过算法的优化,Mahout可以给出更准确的推荐结果。所以,想用Mahout做推荐引擎的同学,就要对自己要求高一点,不仅要会Java,会Mahout,还要知道底层算法以及Mahout对算法的改动,这样Mahout在你手中才能发挥出真正的威力!关于Mahout的更多文章,请查阅笔者的博客(http://blog.fens.me/hadoop-mahout-roadmap/)。