2.3 二条均线打天下
问题
如何用R语言编写金融算法模型?
引言
移动平均线(MA)是股市中最常用的一种技术分析方法,用来在大行情的波动段找到有效的交易信号。移动平均线不仅简单,而且有效,对股市操作具有神奇的指导作用。据金融从业人员说,均线模型有效地打败了大部分的主观策略,是炒股、炒期货的必备基本工具。那么本节将深入研究一下均线模型如何在股市中发挥作用。
2.3.1 移动平均线
移动平均(moving average,MA)线是以道·琼斯的“平均成本概念”为理论基础,采用统计学中“移动平均”的原理,将一段时期内的股票价格平均值连成曲线,用来显示股价的历史波动情况,进而反映股价指数未来发展趋势的技术分析方法。它是道氏理论的形象化表述。在技术分析领域中,移动平均线是必不可少的指标工具。移动平均线的计算方法就是求连续若干天的收盘价的算术平均,天数就是MA的参数。
计算公式是MA=(C1+C2+C3+C4+C5+…+Cn)/n,其中C为收盘价,n为移动平均周期数。例如,5日移动平均价格计算方法为:
MA5 = (前四天收盘价+前三天收盘价+前天收盘价+昨天收盘价+今天收盘价)/5
移动平均线依时间长短可分为三种,即短期移动平均线、中期移动平均线、长期移动平均线。短期移动平均线一般以5日或10日为计算期间,中期移动平均线大多以30日、60日为计算期间,长期移动平均线大多以100日和200日为计算期间。
移动平均线根据对数据的处理方法,又可分为3种。
(1)简单移动平均线(simple moving average,SMA):又称“算术移动平均线”,是指对特定期间的收盘价进行简单平均化的意思。一般所提到的移动平均线即指简单移动平均线,本节中介绍的算法模型,也是用的简单移动平均线。
(2)加权移动平均线(weighted moving average,WMA):是一种按时间进行加权运算的移动平均线。时间越近,价格的权重越大。计算方式是基于加权移动平均线日数,将每一个之前日期比重提升。每个价格会乘以一个权重,最新的价格会有最大的比重,其之前的每一日的比重将会递减。加权移动平均线是移动平均线的改良。
(3)指数平滑移动平均线(exponential moving average,EMA):是以指数式递减加权的移动平均。各数值的加权影响力随时间而指数式递减,越近期的数据加权影响力越重,但较旧的数据也给予一定的加权值。
2.3.2 均线模型
在交易软件日K线图中,除了标准的价格K线以外,通常还有4条线,分别是白线、黄线、紫线、绿线,依次分别表示5日、10日、20日和60日移动平均线。通过这4条线与价格K线的交叉,就可以形成不同的均线模型。以乐视网(300104)股票日K线图为例,截取2012年8月到2014年7月的股价数据,如图2-4所示。
从图2-4中,我们看到乐视网股价最低价是13.91元,出现在2012年12月;最高价55.50元,出现在2014年1月。这段时期,乐视网的股价一路震荡向上,波动最小的绿色线为60日均线平滑的股价,趋势性比较明显。![]()
图2-4 乐视网股票日K线图
利用均线平滑的特点,可以发现均线与价格K线会有交叉,各均线之间也有交叉,我们可以通过这些交叉点判断交易信号。
黄金交叉,当10日均线由下往上穿越20日均线,10日均线在上,20日均线在下,其交叉点就是黄金交叉,黄金交叉是多头的表现,出现黄金交叉后,后市会有一定的涨幅空间,这是进场的最佳时机。
死亡交叉,当20日均线与10日平均线交叉时,20日均线由下住上穿越10日均线,形成20日平均线在上,10日均线在下时,其交点称为“死亡交叉”,“死亡交叉”预示空头市场来临,股市将下跌,此时是出场的最佳时机。
如果很好地运用移动平均线理论,再掌握行情的真正趋势,就能获取可观利润。但移动平均线理论也有局限性,具体如下:
移动平均线是股价定型后产生的图形,反映较慢,只适用于日间交易;
移动平均线不能反映股价在当日的变化及成交量的大小,不适用于日内交易;
移动平均线是趋势性模型,如果股价未形成趋势,只是频繁波动,模型不适用。
2.3.3 用R语言实现均线模型
接下来,我们利用R语言对股票数据进行操作,实现一个均线模型的实例。
1.?从互联网下载数据
R语言本身提供了丰富的金融函数工具包,quantmod包就是最常用的一个,不过quantmod包还要配合时间序列包zoo、可扩展的时间序列包xts、指标计算包TTR和可视包ggplot2等一起使用,关于zoo包和xts包的详细使用可以参考《R的极客理想——工具篇》的2.1节和2.2节。
我们首先利用quantmod包,从互联网下载股票数据,并以CSV格式保存到本地。
加载工具包
library(plyr)
library(quantmod)
library(TTR)
library(ggplot2)
library(scales)download<-function(stock,from="2010-01-01"){ # 下载数据并保存到本地
- df<-getSymbols(stock,from=from,env=environment(),auto.assign=FALSE) # 下载数据
- names(df)<-c("Open","High","Low","Close","Volume","Adjusted")
- write.zoo(df,f?ile=paste(stock,".csv",sep=""),sep=",",quote=FALSE) # 保存到本地文件
+}
read<-function(stock){ # 从本地文件读数据
- as.xts(read.zoo(f?ile=paste(stock,".csv",sep=""),header = TRUE,sep=",",
format="%Y-%m-%d"))+}
stock<-"IBM" # 下载IBM的股票行情数据
download(stock,from='2010-01-01')
IBM<-read(stock) # 把数据加载到内存class(IBM) # 查看数据类型
[1] "xts" "zoo"
head(IBM) # 查看前6条数据
Open High Low Close Volume Adjusted2010-01-04 131.18 132.97 130.85 132.45 6155300 121.91
2010-01-05 131.68 131.85 130.10 130.85 6841400 120.44
2010-01-06 130.68 131.49 129.81 130.00 5605300 119.66
2010-01-07 129.87 130.25 128.91 129.55 5840600 119.24
2010-01-08 129.07 130.92 129.05 130.85 4197200 120.44
2010-01-11 131.06 131.06 128.67 129.48 5730400 119.18
利用quantmod包的getSymbols()函数,默认会通过Yahoo金融的开放API下载数据,我们选择IBM的股票行情数据,从2010-01-01到2014-07-09的4年多的日间交易数据。数据类型为xts格式的时间序列,数据包括7个列,以日期做索引列,其他6列分别为开盘价(Open)、最高价(High)、最低价(Low)、收盘价(Close)、交易量(Volume)、调整价(Adjusted)。
2.?实现简单的蜡烛图
直接使用quantmod包的chartSeries()函数,我们可以画出可视化效果还不错的蜡烛图。简单的蜡烛图,如图2-5所示。
chartSeries(IBM) # 画IBM股票的蜡烛图
如果你想在蜡烛图上增加一些技术指标也是非常方便的,直接把指标函数以参数传给chartSeries()函数就行了,画出带SMA、MACD、ROC等指标的蜡烛图,所图2-6所示。
chartSeries(IBM,TA = "addVo(); addSMA(); addEnvelope();addMACD(); addROC()")
# 画带指标的蜡烛图
![]()
非常简单的2个函数,就可以实现股票数据的可视化。当然,这个功能是封装好的通用的函数,如果我们要自定义策略模型,就需要自己写代码来实现了,比如自定义的支持量机(SVM)分类器模型,不过本节不讲太复杂的模型,而是实现均线模型。
3.?自定义均线图
通过自定义的方式,我们就可以脱离quantmod包自由发挥了。我们首先需要自定义均线指标:
日期时间序列为索引
收盘价作为价格指标
不考虑成交量以及其他维度字段
取2010-01-01至2012-01-01的股票的行情数据
画出价格曲线以及5日均线、20日均线、60日均线
用R语言程序实现代码,如下所示。
ma<-function(cdata,mas=c(5,20,60)){ # 移动平均计算函数
- ldata<-cdata
- for(m in mas){
- ldata<-merge(ldata,SMA(cdata,m))
- }
- ldata<-na.locf(ldata, fromLast=TRUE)
- names(ldata)<-c('Value',paste('ma',mas,sep=''))
- return(ldata)
- }
drawLine<-function(ldata,titie="Stock_MA",sDate=min(index(ldata)),eDate=
- g<-ggplot(aes(x=Index, y=Value),data=fortify(ldata[,1],melt=TRUE))
- g<-g+geom_line()
- g<-g+geom_line(aes(colour=Series),data=fortify(ldata[,-1],melt=TRUE))
- g<-g+scale_x_date(labels=date_format("%Y-%m"),breaks=date_breaks
("2 months"),limits = c(sDate,eDate)) - g<-g+xlab("") + ylab("Price")+ggtitle(title)
+ - if(out) ggsave(g,f?ile=paste(titie,".png",sep=""))
- else g
- }
运行程序
cdata<-IBM['2010/2012']$Close # 取收盘价
title<-"Stock_IBM" # 图片标题
sDate<-as.Date("2010-1-1") # 开始日期
eDate<-as.Date("2012-1-1") # 结束日期
ldata<-ma(cdata,c(5,20,60)) # 选择滑动平均指标
drawLine(ldata,title,sDate,eDate) # 画图,如图2-7所示
![]()
通过自己封装的移动平均函数和可视化函数,就实现了与交易软件中类似的日K线图和多条均线结合的可视化输出。
4.?一条均线的交易策略
基于上面的定义的均线函数,我们就可以设计自己的交易策略模型了。模型设计思路如下:
(1)以股价和20日均线的交叉,进行交易信号的判断。
(2)当股价上穿20日均线则买入,下穿20日均线则卖出。
画出股价和20日均线图,如图2-8所示。
ldata<-ma(cdata,c(20)) # 选择滑动平均指标
drawLine(ldata,title,sDate,eDate) # 画图
![]()
图2-8 20日均线图
以散点覆盖20日均线,红色点为买入持有,蓝色点为卖出空仓,如图2-9所示。
均线图+散点
drawPoint<-function(ldata,pdata,titie,sDate,eDate){
- g<-ggplot(aes(x=Index, y=Value),data=fortify(ldata[,1],melt=TRUE))
- g<-g+geom_line()
- g<-g+geom_line(aes(colour=Series),data=fortify(ldata[,-1],melt=TRUE))
- g<-g+geom_point(aes(x=Index,y=Value,colour=Series),data=fortify(pdata,melt=TRUE))
- g<-g+scale_x_date(labels=date_format("%Y-%m"),breaks=date_breaks("2 months"),
limits = c(sDate,eDate)) - g<-g+xlab("") + ylab("Price")+ggtitle(title)
- g
- }
散点数据
pdata<-merge(ldata$ma20[which(ldata$Value-ldata$ma20>0)],ldata$ma20[which
(ldata$Value-ldata$ma20<0)])names(pdata)<-c("down","up")
pdata<-fortify(pdata,melt=TRUE)
pdata<-pdata[-which(is.na(pdata$Value)),]head(pdata)
Index Series Value1 2010-01-04 down 128.7955
2 2010-01-05 down 128.7955
3 2010-01-06 down 128.7955
4 2010-01-07 down 128.7955
5 2010-01-08 down 128.7955
6 2010-01-11 down 128.7955
drawPoint(ldata,pdata,title,sDate,eDate) # 画图,如图2-9所示
![]()
图2-9 20日均线交易信号图
用股价和20日均线价格做比较,把股价大于20日均线的部分用蓝色表示,股价小于20日均线的部分用红色表示。我们看到图中,蓝色点和红色点在20日均线上交替出现,我们可以在每次红色出现的第一个点买入股票,然后在蓝色出现的第一个点卖出股票,这样就构成了交易信号,从直观看上去的感觉还是不错的。
我们要找出这些交易信号点,做量化的统计,看看到底能不能赚钱,能赚多少钱。
Signal<-function(cdata,pdata){ # 交易信号
- tmp<-''
- tdata<-ddply(pdata[order(pdata$Index),],.(Index,Series),function(row){
- if(row$Series==tmp) return(NULL)
- tmp<<-row$Series
- })
- tdata<-data.frame(cdata[tdata$Index],op=ifelse(tdata$Series=='down','B','S'))
- names(tdata)<-c("Value","op")
- return(tdata)
- }
tdata<-Signal(cdata,pdata)
tdata<-tdata[which(as.Date(row.names(tdata))head(tdata)Value op2010-01-04 132.45 B
2010-01-22 125.50 S
2010-02-17 126.33 B
2010-03-09 125.55 S
2010-03-11 127.60 B
2010-04-08 127.61 S
nrow(tdata) # 交易记录
[1] 72
统计发现,一共有72条交易记录,买卖各占一半。
接下来,我们要利用交易信号的数据,进行模拟交易。我们设定交易参数,以10万美元为本金,满仓买入或卖出,手续费为0元。
模拟交易
trade<-function(tdata,capital=100000,position=1,fee=0.00003){
- amount<-0 # 持股数量
- cash<-capital # 现金
+ - ticks<-data.frame()
- for(i in 1:nrow(tdata)){
- row<-tdata[i,]
- if(row$op=='B'){
- amount<-floor(cash/row$Value)
- cash<-cash-amount*row$Value
- }
+ - if(row$op=='S'){
- cash<-cash+amount*row$Value
- amount<-0
- }
+ - row$cash<-cash # 现金
- row$amount<-amount # 持股数量
- row$asset<-cash+amount*row$Value # 资产总值
- ticks<-rbind(ticks,row)
- }
+ - ticks$diff<-c(0,diff(ticks$asset)) # 资产总值差
+ -
赚钱的操作
- rise<-ticks[c(which(ticks$diff>0)-1,which(ticks$diff>0)),]
- rise<-rise[order(row.names(rise)),]
+ -
赔钱的操作
- fall<-ticks[c(which(ticks$diff<0)-1,which(ticks$diff<0)),]
- fall<-fall[order(row.names(fall)),]
+ - return(list(
- ticks=ticks,
- rise=rise,
- fall=fall
- ))
- }
result1<-trade(tdata,100000)
查看每笔交易
head(result1$ticks)
Value op cash amount asset diff2010-01-04 132.45 B 0.25 755 100000.00 0.00
2010-01-22 125.50 S 94752.75 0 94752.75 -5247.25
2010-02-17 126.33 B 5.25 750 94752.75 0.00
2010-03-09 125.55 S 94167.75 0 94167.75 -585.00
2010-03-11 127.60 B 126.55 737 94167.75 0.00
2010-04-08 127.61 S 94175.12 0 94175.12 7.37
盈利的交易
head(result1$rise)
Value op cash amount asset diff2010-03-11 127.60 B 126.55 737 94167.75 0.00
2010-04-08 127.61 S 94175.12 0 94175.12 7.37
2010-07-22 127.47 B 108.79 633 80797.30 0.00
2010-08-12 128.30 S 81322.69 0 81322.69 525.39
2010-09-09 126.36 B 120.40 632 79979.92 0.00
2010-11-16 142.24 S 90016.08 0 90016.08 10036.16
亏损的交易
head(result1$fall)
Value op cash amount asset diff2010-01-04 132.45 B 0.25 755 100000.00 0.00
2010-01-22 125.50 S 94752.75 0 94752.75 -5247.25
2010-02-17 126.33 B 5.25 750 94752.75 0.00
2010-03-09 125.55 S 94167.75 0 94167.75 -585.00
2010-04-09 128.76 B 51.56 731 94175.12 0.00
2010-04-12 128.36 S 93882.72 0 93882.72 -292.40
通过模拟交易,我们就能精确地算出每笔交易的盈利情况了。这其中,有56笔交易其实是亏损的,只有16笔交易是有盈利的。查看最后的资金情况。
tail(result1$ticks,1)
Value op cash amount asset diff2011-12-21 181.47 S 96363.76 0 96363.76 -3063.87
最后,资金剩余96363.76美元,也就是我们亏了3636.24美元。为什么最后会亏损呢?中间的大波段应该赚到了足够多的钱。通过资金曲线我们可以找到亏损的原因。画出资金曲线,如图2-10所示。
股价+现金流量
drawCash<-function(ldata,adata){
- g<-ggplot(aes(x=Index, y=Value),data=fortify(ldata[,1],melt=TRUE))
- g<-g+geom_line()
- g<-g+geom_line(aes(x=as.Date(Index), y=Value,colour=Series),data=fortify
(adata,melt=TRUE)) - g<-g+facet_grid(Series ~ .,scales = "free_y")
- g<-g+scale_y_continuous(labels = dollar)
- g<-g+scale_x_date(labels=date_format("%Y-%m"),breaks=date_breaks("2 months"),
limits = c(sDate,eDate)) - g<-g+xlab("") + ylab("Price")+ggtitle(title)
- g
- }
现金流量
adata<-as.xts(result1$ticks[which(result1$ticks$op=='S'),]['cash'])
drawCash(ldata,adata) # 画图
![]()
图2-10 20日均线策略现金曲线
我们把股价和现金流量并排放置,从2010-09开始均线策略开始大幅赚钱,到2011-10到达最高点,并且超过了本金,然后开始下滑,截至2012-01亏损3859.86美元。这是由于我们把赚到的利润继续投资,增大了头寸,以至于2011年年底的震荡市让模型失效,从而赔了更多的钱。
这样就完成一条20日均线的交易策略模型,并用IBM的股票做了测试。
5.?二条均线的交易策略
一条均线模型,在大的趋势下是可以稳定赚钱的,但由于一条均线对于波动非常敏感,如果小波动过于频繁,不仅会增加交易次数,而且会让模型失效。然后,就有二条均线的策略模型,它可以降低对波动的敏感性。
二条均线策略模型,与一条均线模型思路类似,以5日均线价格替换股价,是通过5日均线和20日均线交叉来进行交易的。我们首先画出股价5日均线和20日均线图,如图2-11所示。
ldata<-ma(cdata,c(5,20)) # 选择滑动平均指标
drawLine(ldata,title,sDate,eDate) # 画图
![]()
图2-11 5日均线和20日均线图
以散点覆盖20日均线,红色点为买入持有,紫色点为卖出空仓,如图2-12所示。
散点数据
pdata<-merge(ldata$ma20[which(ldata$ma5-ldata$ma20>0)],ldata$ma20[which(ldata$ma5-
ldata$ma20<0)])names(pdata)<-c("down","up")
pdata<-fortify(pdata,melt=TRUE)
pdata<-pdata[-which(is.na(pdata$Value)),]head(pdata)
Index Series Value1 2010-01-04 down 128.7955
2 2010-01-05 down 128.7955
3 2010-01-06 down 128.7955
4 2010-01-07 down 128.7955
5 2010-01-08 down 128.7955
6 2010-01-11 down 128.7955
drawPoint(ldata,pdata,title,sDate,eDate) # 画图,如图2-12所示。
![]()
图2-12 5日均线和20日均线交易信号图
用5日均线和20日均线价格做比较,把5日均线小于20日均线的部分用紫色表示,5日均线大于20日均线的部分用红色表示。我们看到图中,紫色点和红色点在20日均线上交替出现。同样,我们可以在每次红色出现的第一个点买入股票,然后在紫色出现的第一个点卖出股票。直观看上去与一条均线模型类似,都是赚钱的。
我们要找出这些交易信号点,做量化的统计,看看到底能不能赚钱。
> tdata<-Signal(cdata,pdata)
> tdata<-tdata[which(as.Date(row.names(tdata))<eDate),]
> head(tdata)
Value op
2010-01-04 132.45 B
2010-01-26 125.75 S
2010-02-18 127.81 B
2010-03-10 125.62 S
2010-03-16 128.67 B
2010-04-12 128.36 S
> nrow(tdata) # 交易记录
[1] 36
一共有36条交易记录,买卖各占一半,比一条均线模型少了36笔交易。
模拟交易
result2<-trade(tdata,100000)
查看每笔交易
> head(result2$ticks)
Value op cash amount asset diff
2010-01-04 132.45 B 0.25 755 100000.00 0.00
2010-01-26 125.75 S 94941.50 0 94941.50 -5058.50
2010-02-18 127.81 B 106.48 742 94941.50 0.00
2010-03-10 125.62 S 93316.52 0 93316.52 -1624.98
2010-03-16 128.67 B 30.77 725 93316.52 0.00
2010-04-12 128.36 S 93091.77 0 93091.77 -224.75
盈利的交易
> head(result2$rise)
Value op cash amount asset diff
2010-09-10 127.99 B 75.34 649 83140.85 0.00
2010-11-18 144.36 S 93764.98 0 93764.98 10624.13
2010-12-07 144.02 B 2.66 638 91887.42 0.00
2011-02-23 160.18 S 102197.50 0 102197.50 10310.08
2011-03-28 161.37 B 124.70 582 94042.04 0.00
2011-05-20 170.16 S 99157.82 0 99157.82 5115.78
亏损的交易
head(result2$fall)
Value op cash amount asset diff2010-01-04 132.45 B 0.25 755 100000.00 0.00
2010-01-26 125.75 S 94941.50 0 94941.50 -5058.50
2010-02-18 127.81 B 106.48 742 94941.50 0.00
2010-03-10 125.62 S 93316.52 0 93316.52 -1624.98
2010-03-16 128.67 B 30.77 725 93316.52 0.00
2010-04-12 128.36 S 93091.77 0 93091.77 -224.75
通过模拟交易,我们精确地算出每笔交易的盈利情况了,有26笔交易是亏损的,16笔交易是有盈利的。
查看最后的资金情况。tail(result2$ticks,1)
Value op cash amount asset diff2011-12-19 182.89 S 96828.9 0 96828.9 -3581.33
利用交易信号数据,进行模拟交易。我们设定交易参数,以100000美元为本金,满仓买入或卖出,手续费为0,传入交易信号。最后,资金剩余96828.9美元,亏了3171.1美元。查看资金曲线,如图2-13所示。
> adata<-as.xts(result2$ticks[which(result2$ticks$op=='S'),]['cash'])
> drawCash(ldata,adata)
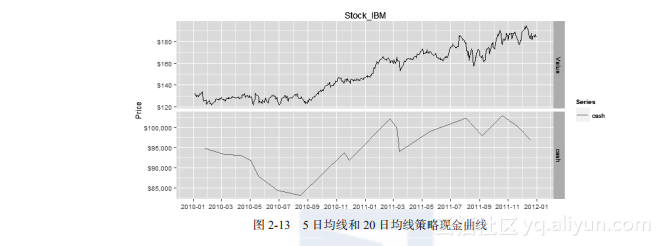
图2-13 5日均线和20日均线策略现金曲线
我们可以发现,虽然最后资金也是赔了3171.1美元,比一条均线策略模型赔的少一点,但二条均线策略模型有3次高于本金的情况,而且最差的情况也比一条均线最差的情况要好。如果我们在获得盈利后,把赚到的钱从账户取出,只保持原来本金的继续交易,那么这部分利润就是可以锁定了。
6.?对比两个模型的盈利情况
我们再进一步对比两个模型的盈利情况,找出两个模型中所有赚钱的交易。
# 盈利的交易rise<-merge(as.xts(result1$rise[1]),as.xts(result2$rise[1]))
names(rise)<-c("plan1","plan2")
# 查看数据情况
> riseplan1 plan2
2010-03-11 127.60 NA
2010-04-08 127.61 NA
2010-07-22 127.47 NA
2010-08-12 128.30 NA
2010-09-09 126.36 NA
2010-09-10 NA 127.99
2010-11-16 142.24 NA
2010-11-18 NA 144.36
2010-12-07 NA 144.02
2010-12-08 144.98 NA
2011-02-22 161.95 NA
2011-02-23 NA 160.18
2011-03-25 162.18 NA
2011-03-28 NA 161.37
2011-05-16 168.86 NA
2011-05-20 NA 170.16
2011-06-21 166.22 NA
2011-06-23 NA 166.12
2011-08-02 178.05 NA
2011-08-04 NA 171.48
2011-09-14 167.24 NA
2011-09-16 NA 172.99
2011-09-22 168.62 NA
2011-09-23 169.34 NA
2011-10-18 178.90 NA
2011-10-21 NA 181.63
plan1是一条均线模型,plan2是二条均线模型。plan1比plan2多了6次交易,但从中可以发现,多的这几次交易是由于对波动敏感性引起的,反而减少了趋势行情所带来的收益。
最后,我们画出2个模型盈利部分的交易区间。均线图+交易区间
drawRange<-function(ldata,plan,titie="Stock_2014",sDate=min(index(ldata)),
- g<-ggplot(aes(x=Index, y=Value),data=fortify(ldata[,1],melt=TRUE))
- g<-g+geom_line()
- g<-g+geom_line(aes(colour=Series),data=fortify(ldata[,-1],melt=TRUE))
- g<-g+geom_rect(aes(NULL, NULL,xmin=start,xmax=end,f?ill=plan),ymin = yrng[1],
ymax = yrng[2],data=plan) - g<-g+scale_f?ill_manual(values =alpha(c("blue", "red"), 0.2))
- g<-g+scale_x_date(labels=date_format("%Y-%m"),breaks=date_breaks
("2 months"),limits = c(sDate,eDate)) - g<-g+xlab("") + ylab("Price")+ggtitle(title)
+ - if(out) ggsave(g,f?ile=paste(titie,".png",sep=""))
- else g
- }
# 盈利区间
> yrng <-range(ldata$Value)
> plan1<-as.xts(result1$rise[c(1,2)])
> plan1<-data.frame(start=as.Date(index(plan1)[which(plan1$op=='B')]),end=
as.Date(index(plan1)[which(plan1$op=='S')]),plan='plan1')
> plan2<-as.xts(result2$rise[c(1,2)])
> plan2<-data.frame(start=as.Date(index(plan2)[which(plan2$op=='B')]),end=
as.Date(index(plan2)[which(plan2$op=='S')]),plan='plan2')
> plan<-rbind(plan1) # plan1的盈利区间
> drawRange(ldata,plan,title,sDate,eDate) # 画图
plan1的盈利区间,如图2-14所示。
> plan<-rbind(plan1,plan2) # 合并plan1和plan2的盈利区间
> drawRange(ldata,plan,title,sDate,eDate) # 画图
plan1和plan2同时存在的盈利区间,如图2-15所示。
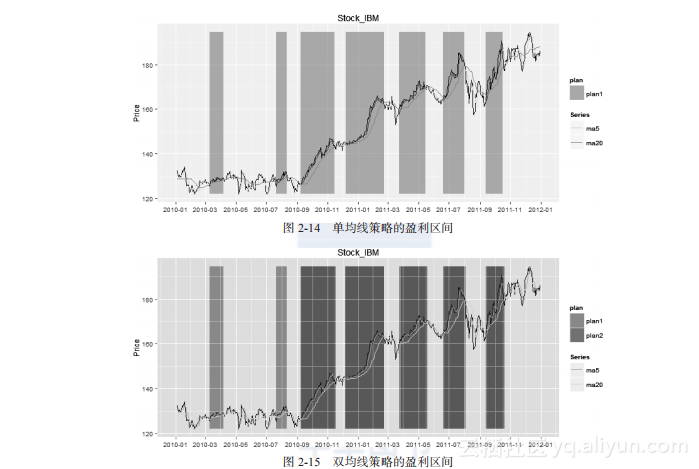
从盈利区间我们可以看到,这印证了一条均线对波动敏感性的问题,二条均线模型是对一条均线模型的优化,这样我们就实现了一个完整均线模型的实例研发。
7.?模型优化
从交易的角度讲,上面的模型还不能算完成,因为还有很多的赔钱交易,要进行更多地优化,减少最大回撤,在更确定的时机做多、反向做空等。模型优化的问题,会在《R的极客理想——量化投资篇》中再进行详细的介绍。
看起来均线模型是如此简单,但实盘交易时真能在趋势行情中跑赢双均线(优化)模型,也真不是一件容易的事情。二条均线打天下,不说是东方不败,也至少是独孤求败。
如果按照我所介绍的方法,赚到钱的朋友,可以请我喝杯茶,分享一下经验;没有赚到钱的朋友,还要继续努力,总有一天可以实现财富自由的目标的。