原创 2016-07-05 熊军 Oracle
编辑手记:在理解Oracle技术细节时,我们不仅应该读懂概念,还要能够通过测试验证细节,理解那些『功夫在诗外』的部分,例如全表扫描和单块读。
开发人员在进行新系统上线前的数据校验测试时,发现一条手工执行的 SQL 执行了超过1小时还没有返回结果。SQL 很简单:

下面是这条 SQL 的真实的执行计划:
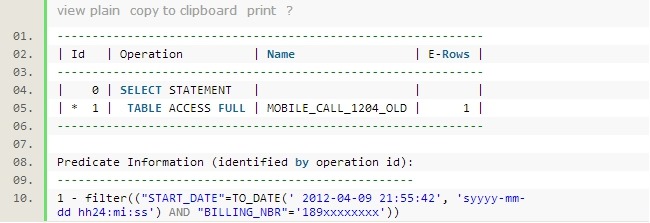
很显然,在这个表上建 billing_nbr 和 start_date 的复合索引,这条 SQL 就能很快执行完(实际上最后也建了索引)。但是这里我们要探讨的是,为什么这么一条简单的 SQL 语句,执行了超过1小时还没有结果。 MOBILE_CALL_1204_OLD 这张表的大小约为 12GB ,以系统的 IO 能力,正常情况下不会执行这么长的时间。简单地看了一下,系统的 CPU 以及 IO 压力都不高。假设单进程全表扫描表,每秒扫描 50MB 大小(这实际上是一个很保守的扫描速度了),那么只需要245秒就可以完成扫描。
下面来诊断一下 SQL 为什么会这么不正常地慢。看看会话的等待(以下会用到 Oracle 大牛Tanel Poder的脚本):
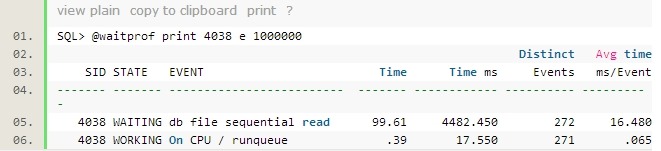
明明是全表扫描的 SQL ,为什么99%以上的等待时间是 db file sequential read ,即单块读?!多执行几次 waitprof 脚本,得到的结果是一致的(注意这里的数据,特别是平均等待时间并不一定是准确的值,这里重点关注的是等待时间的分布)。
那么 SQL 执行计划为全表扫描(或索引快速全扫描)的时候,在运行时会有哪些情况实际上是单块读?我目前能想到的有:
1. db_file_multiblock_read_count 参数设置为1
2. 表或索引的大部分块在 buffer cache 中,少量不连续的块在磁盘上。
3. 一些特殊的块,比如段头
4. 行链接的块
5. LOB 列的索引块和 cache 的 LOB 块(虽然10046事件看不到 lob 索引和 cache 的 lob 的读等待,但客观上是存在的。)
那么在这条 SQL 语句产生的大量单块读,又是属于什么情况呢?我们来看看单块读更细节的情况:
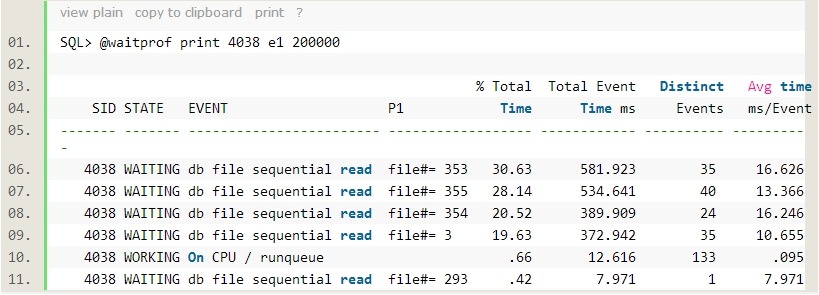
多次执行同样的 SQL ,发现绝大部分的单块读发生在3、353-355这四个文件上,我们来看看这4个文件是什么:

原来是 UNDO 表空间。那么另一个疑问就会来了,为什么在 UNDO 上产生了如此之多的单块读?首先要肯定的是,这条简单的查询语句,是进行的一致性读。那么在进行一致性读的过程中,会有两个动作会涉及到读 UNDO 块,延迟块清除和构建 CR 块。下面我们用另一个脚本来查看会话当时的状况:

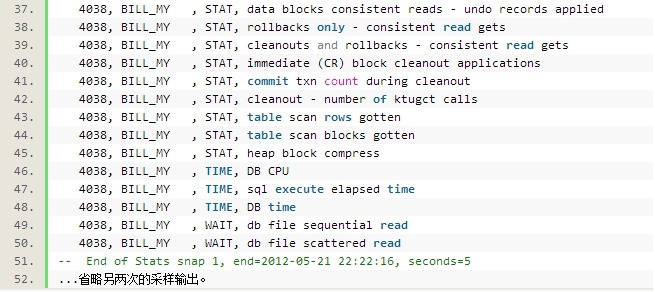
上面的结果是5秒左右的会话采样数据。再一次提醒,涉及到时间,特别要精确到毫秒的,不一定很精确,我们主要是看数据之间的对比。从上面的数据来看,会话请求了382次 IO 请求,单块读和多块读一共耗时4219.17ms(4.17s+49.17ms),平均每次 IO 耗时 11ms。这个单次 IO 速度对这套系统的要求来说相对较慢,但也不是慢得很离谱。data blocks consistent reads - undo records applied 这个统计值表示进行一致性读时,回滚的 UNDO 记录条数。
比这个统计值可以很明显地看出,这条 SQL 在执行时,为了得到一致性读,产生了大量的 UNDO 记录回滚。那么很显然,在这条 SQL 语句开始执行的时候,表上有很大的事务还没有提交。当然还有另一种可能是 SQL 在执行之后有新的很大的事务(不过这种可能性较小一些,因为那样的话这条 SQL 可能比较快就执行完了)。
询问发测试的人员,称没有什么大事务运行过,耳听为虚,眼见为实:
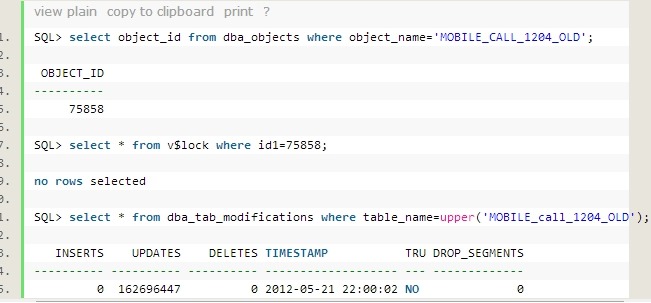
这张表目前没有事务,但是曾经 update 了超过1.6亿条记录。最后一次 DML 的时间正是这条执行很慢的 SQL 开始运行之后的时间(这里不能说明最后一次事务量很大,也不能说明最后一次修改对 SQL 造成了很大影响,但是这里证明了这张表最近的确是修改过,并不是像测试人员说的那样没有修改过)。
实际上对于这张表要做的操作,我之前是类似的表上是有看过的。这张表的总行数有上亿条,而这张表由于进行数据的人工处理,需要 update 掉绝大部分的行, update 时使用并行处理。那么这个问题到,从时间顺序上来讲,应该如下:
在表上有很大的事务,但是还没有提交。
问题 SQL 开始执行查询。
事务提交。
在检查 SQL 性能问题时,表上已经没有事务。
由于 update 量很大,那么 UNDO 占用的空间也很大,但是可能由于其他活动的影响,很多 UNDO 块已经刷出内存,这样在问题 SQL 执行时,大量的块需要将块回滚到之前的状态(虽然事务开始于查询 SQL ,但是是在查询 SQL 开始之后才提交的,一致性读的 SCN 比较是根据 SQL 开始的 SCN 与事务提交 SCN 比较的,而不是跟事务的开始 SCN 比较),这样需要访问到大量的 UNDO 块,但是 UNDO 块很多已经不在内存中,就不得不从磁盘读入。
对于大事务,特别是更新或 DELETE 数千万记录的大事务,在生产系统上尽量避免单条 SQL 一次性做。这造成的影响特别大,比如:
v 事务可能意外中断,回滚时间很长,事务恢复时过高的并行度可能引起负载增加。
v 表中大量的行长时间被锁住。
v 如果事务意外中断,长时间的回滚(恢复)过程中,可能严重影响 SQL 性能(因为查询时需要回滚块)。
v 事务还未提交时,影响 SQL 性能,比如本文中提到的情况。
v 消耗过多 UNDO 空间。
v 对于 DELETE 大事务,有些版本的 oracle 在空闲空间查找上会有问题,导致在 INSERT 数据时,查找空间导致过长的时间。
v 对于 RAC 数据库,由于一致性读的代价更大,所以大事务的危害更大。
那么,现在我们可以知道,全表扫描过程还会产生单块读的情况有,读 UNDO 块。
对于这条 SQL ,要解决其速度慢的问题,有两种方案:
① 在表上建个索引,如果类似的 SQL 还要多次执行,这是最佳方案。
② 取消 SQL ,重新执行。因为已经没有事务在运行,重新执行只是会产生事务清除,但不会回滚 UNDO 记录来构建一致性读块。
继续回到问题,从统计数据来看:
l 每秒只构建了少量的一致性读块(CR block created,table scan blocks gotten这两个值均为2);
l 每秒的 table scan rows gotten 值为98.4,通过 dump 数据块可以发现块上的行数基本上在49行左右,所以一致性读块数和行数是匹配的;
l session logical reads 每秒为97.6,由于每回滚一条 undo 记录都要记录一次逻辑读,这个值跟每秒获取的行数也是匹配的(误差值很小),与 data blocks consistent reads - undo records applied 的值也是很接近的。
问题到这儿,产生了一个疑问,就是单块读较多(超过70),因此可以推测,平均每个 undo 块只回滚了不到2条的 undo 记录,同时同一数据块上各行对应的 undo 记录很分散,分散到了多个 undo 块中,通常应该是聚集在同一个块或相邻块中,这一点非常奇怪,不过现在已经没有这个环境(undo 块已经被其他事务重用),不能继续深入地分析这个问题,就留着一个疑问,欢迎探讨(一个可能的解释是块是由多个并发事务修改的,对于这个案例,不会是这种情况,因为在数据块的 dump 中没有过多 ITL,另外更不太可能是一个块更新了多次,因为表实在很大,在短时间内不可能在表上发生很多次这样的大事务)。
在最后,我特别要提到,在生产系统上,特别是 OLTP 类型的系统上,尽量避免大事务。
About Me
.........................................................................................................................................................................................................
● 本文来自于微信公众号转载文章,若有侵权,请联系小麦苗及时删除,非常感谢原创作者的无私奉献
● 本文在ITpub(http://blog.itpub.net/26736162)、博客园(http://www.cnblogs.com/lhrbest)和个人微信公众号(xiaomaimiaolhr)上有同步更新
● 小麦苗分享的其它资料:http://blog.itpub.net/26736162/viewspace-1624453/
● QQ群: 230161599 微信群:私聊
● 联系我请加QQ好友(642808185),注明添加缘由
● 【版权所有,文章允许转载,但须以链接方式注明源地址,否则追究法律责任】
.........................................................................................................................................................................................................
长按下图识别二维码或微信客户端扫描下边的二维码来关注小麦苗的微信公众号:xiaomaimiaolhr,学习最实用的数据库技术。
