本节书摘来自华章出版社《机器学习与R语言(原书第2版)》一书中的第2章,第2.3节,美] 布雷特·兰茨(Brett Lantz) 著,李洪成 许金炜 李舰 译更多章节内容可以访问“华章计算机”公众号查看。
2.3 探索和理解数据
在收集数据并把它们载入R数据结构以后,机器学习的下一个步骤是仔细检查数据。在这个步骤中,你将开始探索数据的特征和案例,并且找到数据的独特之处。你对数据的理解越深刻,你将会更好地让机器学习模型匹配你的学习问题。
理解数据探索的最好方法就是通过例子。在本节中,我们将探索usedcars.csv数据集,它包含在流行的美国网站上最近发布的关于二手车打折销售广告的真实数据。
usedcars.csv数据集能在Packt出版社网站的本书支持页面上下载。如果你要和例子一起操作,一定要确保这个文件下载且保存在你的R工作目录中。
因为数据集存储为CSV形式,所以我们能用read.csv()函数把数据载入R数据框中:
有了usedcars数据框,现在我们将担任数据科学家的角色,任务是理解二手车数据。尽管数据探索是一个不确定的过程,但可以把这个步骤想象成一个调查过程,在这个步骤中回答关于数据的问题。具体的问题可能会因任务的不同而有所不同,但问题的类型一般是相似的。不管数据集的大小,你应该能把这个调查的基本步骤应用到任何你感兴趣的数据集中。
2.3.1 探索数据的结构
调查一个新数据集的第一个问题应该是数据是怎么组织的。如果你足够幸运,数据源会提供一个数据字典,它是一个描述数据特征的文档。在我们的例子里,二手车数据并不包含这个文件,所以我们需要创建我们自己的数据字典。
函数str()提供了一个显示数据框、向量和列表这样的R数据结构的方法。这个函数可以用来创建数据字典的基本轮廓: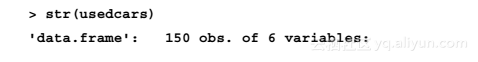

使用这样一条简单的命令,我们就知道了关于数据集的大量信息。语句150 obs告诉我们数据包含150个观测值,这是数据包含150个记录或例子的另一种说法。观测值的数量一般简写为n。因为我们知道数据描述的是二手车,所以现在可以认为供销售的车有n=150辆。
语句6 variables指的是数据中记录了6个特征。这些特征根据名称排列成独立的行。查看特征color所在的那一行,我们注意到一些额外的信息:
在变量名的后面,chr告诉我们这个特征是字符型的。在这个数据集中,3个变量是字符型,另外3个注明是int,表明是整数型。尽管这个数据集仅包含整数型和字符型,但当使用非整数型数据时,你还可能碰到数值型num。所有因子都列为factor型。在每个变量类型的后面,R给出这个特征的最前面的几个值。值"Yellow"、"Gray"、"Silver"和"Gray"是color特征的前4个值。
根据相关领域知识,特征名称和特征值可以使我们对变量所代表的含义做出假定。变量year可能指汽车制造的时间,也可能指汽车广告贴出的时间。接下来我们将更加仔细地调查这个特征,因为这4个案例值(2011 2011 2011 2011)适用于上述任何一个可能性。变量model、price、mileage、color和transmission极有可能指的是销售汽车的特征。
尽管数据似乎被赋予了有内在含义的变量名,但实际应用中并不是所有的数据都是这样的。有时候,数据集的特征可能是没有具体含义的名称、代号或者像V1这样的简单数字。通过进一步调查,确定特征名称确切代表的含义是必不可少的。然而,即使特征名称有具体的含义,也要谨慎检查提供给你的标签含义的正确性。我们继续进行下面的分析。
2.3.2 探索数值变量
为了调查二手车数据中的数值变量,我们将使用一组普遍使用的描述数值的指标,它们称为汇总统计量。summary()函数给出了几个常用的汇总统计量。我们看看二手车数据中的year特征:
即使你对汇总统计量不熟悉,你也能从summary()函数输出结果的标题中猜出一些。现在先不管特征year所代表的具体含义,事实上,当我们看到诸如2000、2008以及2009这样的数字时,我们相信变量year表示汽车制造的时间而不是汽车广告打出的时间,因为我们知道汽车是最近才挂牌出售的。
我们也能使用summary()函数同时得到多个数值变量的汇总统计量: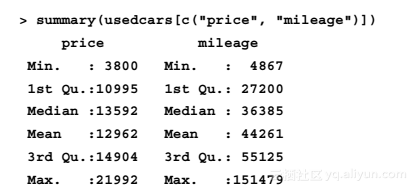
summary()函数提供的6个汇总统计量是探索数据简单但强大的工具。汇总统计量可以分为两种类型:数据的中心测度和分散程度测度。
1.测量中心趋势—平均数和中位数中心趋势测度是这样一类统计量,它们用来标识一组数据的中间值。你应该已经熟悉常用的一个测量中心趋势的指标—平均数。在一般使用中,当一个数被认为是平均数时,它落在数据的两个极值之间的某个位置。一个中等学生的成绩可能落在他的同学成绩的中间;一个平均体重不会是特别重或者特别轻。平均数是具有代表性的,它和组里的其他值不会差得太多。你可以把它设想成一个所有其他值用来进行参照的值。
在统计学中,平均数也叫作均值,它定义为所有值的总和除以值的个数。例如,要想计算收入分别是$36 000、$44 000和$56 000的3个人的平均收入,我们可以如下计算: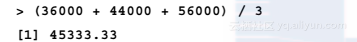
R也提供一个mean()函数,它能计算数值向量的均值:
这组人的平均收入是$45 333.33。从概念上来说,你可以想象这个值是,如果所有收入平等分给每一个人,每个人应该得到的收入。
回忆先前的summary()函数的输出,它列出了变量price和mileage的平均值。price的平均值为12 962,mileage的平均值为44 261,这表明数据集中具有代表性的二手车的价格应该标为$12 962,里程表的读数为44 261。这些告诉我们数据的什么信息呢?因为平均价格相对偏低,所以可以预料我们数据中包括经济型汽车。当然,数据中也有可能包括新型的豪华汽车,有着高里程数,但是相对较低的平均里程数的统计数据并不提供支持这个假设的证据。另一方面,数据并没有提供证据让我们忽略这个可能性。所以,在进一步检验数据时我们要留意这一点。
尽管到目前为止,均值是最普遍引用的测量数据集中心的统计量,但它不一定是最合适的。另一个普遍使用的衡量中心趋势的指标是中位数,它位于有序的值列表的中间。和均值一样,R提供了函数median()来获得这个值,可以把它应用到工资数据中,如下所示:
因为中间值是44 000,所以收入的中位数是$44 000。
如果数据集有偶数个值,那么就没有最中间值。在这种情况下,一般是计算按顺序排列的值列表最中间的两个值的平均值作为中位数。例如,1,2,3,4的中位数是2.5。
乍一看,好像中位数和均值是很类似的度量。肯定的是,均值$45 333.33和中位数$44 000并没有太大的区别。为什么会有这两种中心趋势呢?这是由于落在值域两端的值对均值和中位数的影响是不同的。尤其是均值,它对异常值,或者那些对大多数数据而言异常高或低的值,是非常敏感的。因为均值对异常值是非常敏感的,所以它很容易受到那一小部分极端值的影响而改变大小。
再回忆summary()函数输出的二手车数据集的中位数。尽管price的均值和中位数非常相似(相差大约5%),但mileage的均值和中位数就非常不同。对于mileage来说,均值44 261比中位数36 385大了超过20%。因为均值比中位数对极端值更敏感,所以均值比中位数大很多这个事实,令我们怀疑数据集中的一些二手车有极高的mileage值。为了进一步调查这一点,我们需要在分析中应用一些额外的汇总统计量。
2.测量数据分散程度—四分位数和五数汇总
测量数据的均值和中位数给我们一个迅速概括数据的方法,但是这些中心测度在数值的大小是否具有多样性方面给我们提供了很少的信息。为了测量这种多样性,我们需要应用另一种汇总统计量,它们是与数据的分散程度相关的,或者说它们是与数据之间“空隙”的紧密或者松弛有关系的。知道了数据之间的差异,就对数据的最大值和最小值有了了解,同时也会对大多数值是否接近均值和中位数有了了解。
五数汇总是一组5个统计量,它们大致描述一个数据集的差异。所有的5个统计量包含在函数summary()的输出结果中。按顺序排列,它们是:
1)最小值(Min.)。
2)第一四分位数,或Q1(1st Qu.)。
3)中位数,或Q2(Median)。
4)第三四分位数,或Q3(3rd Qu.)。
5)最大值(Max.)。
如你预期的那样,最小值和最大值是数据集中能发现的最极端的两个值,分别表示数据的最小值和最大值。R提供了函数min()和函数max()来分别计算数据向量中的最小值和最大值。
最小值和最大值的差值称为极差。在R中,range()函数同时返回最小值和最大值。把range()函数和差值函数diff()相结合,你能够用一条命令来检验数据的极差:
第一四分位数和第三四分位数(即Q1和Q3)指的是有1/4的值小于Q1和有1/4的值大于Q3。它们和中位数(Q2)一起,3个四分位数把一个数据集分成4部分,每一部分都有相同数量的值。
四分位数是分位数的一种特殊类型,分位数把数据分为相等数量的数值。除了四分位数外,普遍使用的分位数包括三分位数(分成3部分)、五分位数(分成5部分)、十分位数(分成10部分)和百分位数(分成100部分)。
百分位数通常用来给数据进行等级评定。例如,一个学生的考试成绩排列在百分位数的第99分位数,说明他表现得比其他99%的测试者好。
我们对Q1和Q3之间的50%的数据特别感兴趣,因为它们就是数据分散程度的一个测度。Q1和Q3之间的差称为四分位距(Inter Quartile Range,IQR),可以用函数IQR()来计算,例如:
我们也能从summary()输出的usedcars$price变量的结果来手动计算这个值,即计算14 904-10 995=3909。我们计算的值与IQR()输出结果之间有差别,这是因为R自动对summary()输出结果进行四舍五入。
quantile()函数提供了稳健的工具来给出一组值的分位数。默认情况下,quantile()函数返回五数汇总的值。把这个函数应用到二手车数据中,将产生与前面一样的统计量: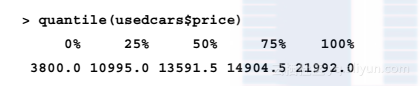
当计算分位数时,有很多种方法处理并列数值和没有中间值的数据集。通过指定type参数,quantile()函数能够在9个不同算法之间选择计算分位数的方法。如果你的项目要求一个精确定义的分位数,使用?quantile命令来阅读该函数的帮助文件是很重要的。
如果我们指定另一个probs参数,它用一个向量来表示分割点,我们能就得到任意的分位数,比如第1和第99的百分位数可以按如下方式求得:
序列函数seq()用来产生由等间距大小的值构成的向量。这个函数使得获得其他分位数变得很容易,比如要想输出五分位数(5个组),可以使用如下所示的命令:
由于理解了五数汇总,所以我们重新检查对二手车数据应用函数summary()的输出结果。对变量price,最小值是$3800、最大值是$21 992。有趣的是,最小值和Q1之间的差是$7000,与Q3和最大值的差是一样的。然而,Q1和中位数的差,以及中位数和Q3的差大约是$2000。这就表明上、下25%的值的分布比中间50%的值更分散,似乎中心周围的值聚集得更加紧密。没有意外的是,我们从变量mileage也看到了相似的趋势。在本章后面你将学到,这个分散模式非常普遍,此时称数据为“正态”分布。
mileage变量的分散程度同时也呈现了另一个有趣的性质:Q3和最大值之间的差远大于最小值和Q1之间的差。换句话说,较大的值比较小的值更分散。
这个发现解释了均值远大于中位数的原因。因为均值对极端值更敏感,所以均值会被极端大的值拉高,而中位数则相比变化不大。这是一个很重要的性质,当数据可视化地呈现出来时就更显而易见。
3.数值变量的可视化—箱图
可视化数值变量对诊断数据问题是有帮助的。一种对五数汇总的常用可视化方式是箱图(或者称为箱须图)。箱图以一种特定方式显示数值变量的中心和分散程度,这种方式使你能很快了解变量的值域和偏度,或者它还可以和其他变量进行比较。
下面观察二手车数据的变量price和变量mileage的箱图。要想得到一个变量的箱图,可以使用函数boxplot()。我们也将指定一些其他参数—main和ylab,它们分别为图形加一个标题和为y轴(即垂直轴)加一个标签。创建变量price和变量mileage箱图的命令是:
R将产生下面的图形: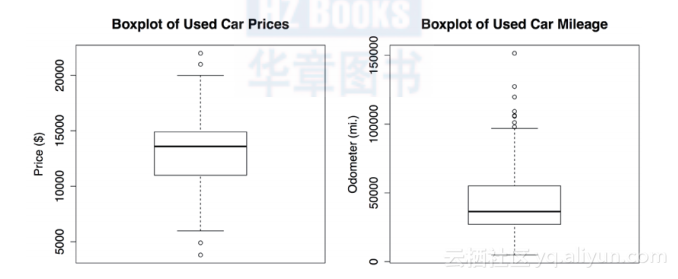
箱图使用水平线和点来表示五数汇总值。在每个图的中间,构成盒子的水平线从下向上,依次代表Q1、Q2(中位数)和Q3。中位数用粗黑线表示,对于变量price,这条线在垂直轴上的纵坐标是$13 592;对于变量mileage,这条线的垂直坐标是36 385。
在如上图所示的简单箱图中,箱图的宽度是任意的,它不能说明任何数据特征。为了满足更加复杂分析的需要,用盒子的形状和尺寸,对多组数据进行比较是可能的。要想知道更多关于箱图的这种特征的信息,可以通过?boxplot命令,查询R中boxplot()函数的帮助文件中的notch和varwidth选项。
最小值和最大值是用细线(whisker)来表示的,就是在盒子下面和上面的细线。然而,通常仅允许细线延伸到最小为低于Q1的1.5倍IQR的最小值,或者延伸到最大为高于Q3的1.5倍IQR的最大值。任何超出这个临界值的值都认为是异常值,并且用圆圈或者点来表示。例如,变量price的IQR是3909,Q1是10995,Q3是14904。因此异常值是任何小于10 995-1.5×3909=5131.5或者大于14 904+1.5×3909=20 767.5的值。
箱图在高端和低端都会出现这类异常值。在mileage的箱图中,在低端没有这样的异常值,所以底部的细线延伸到最小值4867。在高端,我们看到了几个比100 000英里大的异常值。那些异常值就可以解释我们前面探索中所发现的问题,即解释了均值远大于中位数。
4.数值变量可视化—直方图
直方图(histogram)是另一种形象化描述数值变量间差异的方式。它和箱图相似的地方在于,它也把变量值按照预先设定的份数进行分隔,或者说按照预先定义的容纳变量值的分段进行分隔。两者的相似性就是这些。一方面,箱图要求4部分数据的每部分必须包含相同数量的值,根据需要分段也可以变宽或变窄。另一方面,直方图可以有相同宽度的任意数量的分段,但是分段可以包含不同数量的值。
可以用函数hist()为二手车数据的变量price和mileage绘制直方图。就像我们绘制箱图时那样,可以用参数main来指定图形的标题,用参数xlab标记x轴。绘制直方图的命令如下:
产生的直方图如下图所示。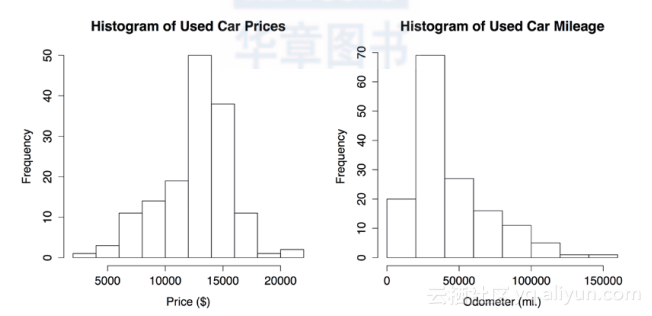
直方图是由一系列的竖条组成,其高度表示落在等长的划分数据值的分段内的数据值的个数或频率。分割每一个竖条的垂直线,就像横坐标的标签一样,表明分段内值的起始点和终点。
你可能注意到前面的直方图中有不同数量的竖条。这是因为hist()函数试图为给定的变量范围找出合理数量的竖条。如果你想重写这里的默认值,使用参数breaks。设置breaks = 10将创建等宽度的10个竖条,设置参数breaks为一个向量,如c(5000, 10000, 15000, 20000)将以给出的特定值为分隔点来创建竖条。
在变量price的直方图上,10个竖条中的每一个都表示范围为$2000的分段,这些分段的范围是从$2000开始,到$14 000结束。直方图中间最高的竖条代表的分段范围为$12 000~$14 000,频率是50。因为我们知道数据中有150辆汽车,其中1/3汽车的价格是为$12 000~$14 000。接近90辆汽车(超过一半)的报价为$12 000~$16 000。
变量mileage的直方图包括8个竖条,它表明每个分段长度都是20 000英里,值域从0开始,到160 000英里结束。与变量price的直方图不一样,在变量mileage的直方图中,最高的竖条不在数据的中心,而是在直方图的左侧。这个最高竖条所在的分段中有70辆车,里程表的范围为20 000~40 000英里。
你可能也注意到了两个直方图的形状有一点不同。似乎二手车price的图形趋向于平均分布在中心的两侧,而汽车mileage的图形则偏到了左侧。这个性质称为偏度(skew),具体来说是右偏,因为与低端的值(右侧)相比高端的值(右侧)更加分散。如下图所示,偏斜数据的直方图看上去偏到了一边。
![]()
能在数据中快速诊断出这类模式是直方图作为数据探索工具的优点之一。在我们检验其他数值数据模型的模式时,这个优点将更为重要。
5.了解数值数据—均匀分布和正态分布
描述数据的中心和分散程度的直方图、箱图和统计量都提供了检验变量分布的方法。变量的分布描述了一个值落在不同值域中的可能性大小。
如果所有值都是等可能发生的,这个分布就称为均匀分布,例如,记录投掷一个均匀的六边形骰子所得结果的数据集。容易用直方图来检测一个均匀分布,因为其直方图的竖条大致有一样的高度。当用直方图来可视化数据时,它可能如下图所示。
![]()
需要注意的重要一点是,并非所有的随机事件都服从均匀分布。例如,掷一个六边重量不同的魔术骰子,将使得某些数字发生的概率比其他的大。每一次掷骰子会产生一个随机数字,但6个数字出现的概率不相等。
例如,回到前面的二手车数据。很明显,这个数据不是均匀分布的,因为有些值明显比其他值发生的可能性更大。事实上,在变量price的直方图上,可以看出中心值两边的值,偏离中心越远,发生的频率就越小,这就是一个钟形的数据分布。这个特征在现实世界的数据中非常普遍,它成为所谓的正态分布的标志性特征。钟形曲线的典型形状如下图所示。
![]()
尽管有许多非正态分布的类型,但许多现象产生的数据都可以用正态分布来描述。因此,正态分布的性质已被研究得很透彻了。
6.测量数据的分散程度—方差和标准差
分布使我们能够用少量的参数来描述大量值的特性。描述现实生活中大量数据的正态分布,可以用两个参数来定义:中心和分散程度。正态分布的中心可以用均值来定义,正如我们在前面使用的那样。分散程度通过一种称为标准差的统计量来测量。
为了计算标准差,我们必须先获得方差,方差定义为每一个值与均值之间的差的平方的均值。用数学符号表示,一组具有n个值的变量x的方差可以通过下面的公式定义。希腊字母表示数值的均值,方差用希腊字母的平方来表示: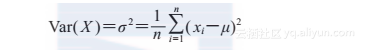
标准差就是方差的平方根,用来表示,如下所示: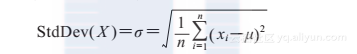
要想在R中获得方差和标准差,可以应用函数var()和函数sd()。例如,计算变量price与变量mileage的方差与标准差,如下所示:
当我们解释方差时,方差越大表示数据在均值周围越分散。标准差表示平均来看每个值与均值相差多少。
如果你用上面的公式手动计算这些统计量,你得出的结果将会与R的内置函数得出的结果略有不同。这是因为上面的公式给出的是总体方差(除以n),而R内置函数用的是样本方差(除以n-1)。除非数据集很小,否则这两种结果的区别是很小的。
在假设数据服从正态分布的条件下,标准差能用来快速地估计一个给定值有多大程度的偏大或者偏小。68-95-99.7规则说明在正态分布中68%的值落在均值左右1个标准差的范围内,而95%和99.7%的值分别落在均值左右2个和3个标准差的范围内。这个规则可以由下图来说明。
![]()
把这个知识应用到二手车数据中,我们知道变量price的均值和标准差分别为$12 962和$3122,假设price数据是正态分布,该数据中大约有68%的车的广告价格为$12 962-$3122=$9840到$12 962+$3122=$16 804。
尽管严格地说,68-95-99.7规则仅仅局限于正态分布中,但是这个基本准则能应用到所有的数据中,数值落在均值的3个标准差以外是极端罕见的事件。
2.3.3 探索分类变量
我们记得二手车数据集有3个分类变量:model、color和transmission。因为在载入数据时,我们使用了stringsAsFactors = FALSE参数,所以R把它们作为字符变量而不是自动把它们转化成factor类型。此外,我们可能考虑把year看作分类变量。尽管把它作为数值(int)向量载入的,但是每一个year值是一个类别,该类别可以应用到多辆汽车上。
与数值数据相比,分类数据是用表格而不是汇总统计量来探索的。表示单个分类变量的表格称为一元表。函数table()能用来产生二手车数据的一元表: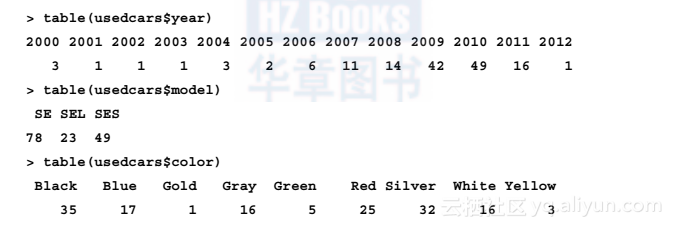
table()的输出列出了名义变量的不同类别和属于该类别的值的数量。由于我们知道数据集有150个二手车数据,所以我们能确定其中大约有1/3是在2010年制造的,因为49/150=0.327。
R也能在table()函数产生的表格上应用函数prop.table(),直接计算表格比例,如下所示:
函数prop.table()的结果能与其他R函数相结合来转换输出的结果。假设我们想要把结果用保留一位小数的百分数来表示,就可以把各个比例值乘以100,再用round()函数并指定digits = 1来实现,如下所示:
尽管它包含的信息和prop.table()函数默认的输出结果一样,但是相对来说这样更容易阅读。结果显示Black(黑色)是最普遍的颜色,因为在广告列出的所有汽车中将近有1/4(23.3%)是Black(黑色)的。Silver(银灰色)与之接近,排在第二位,有21.3%;Red(红色)是第三,有16.7%。
衡量中心趋势—众数
在统计术语中,一个特征(即变量)的众数是指出现最频繁的那个值。与均值和中位数一样,众数是另一个测量中心趋势的统计量。它通常应用在分类数据中,因为均值和中位数并不是为名义变量定义的。
例如,在二手车数据中,year变量的众数是2010,而model和color的众数分别为SE和Black。一个变量可能有多个众数;只有一个众数的变量是单峰的,有两个众数的变量为双峰的。有多个众数的数据通常称为多峰的。
尽管你可能猜测能用mode()函数得到众数,但是R却是用这个函数得出变量的类型(如数值型,列表等),而不是统计量众数。相反,为了找到统计量众数,只需要查看表格输出结果中具有最大值的类别即可。
众数是从定性的角度来了解数据集中的重要值。然大多数。例如,尽管Black是二手车变量color的众数,但是Black仅占所有列出汽车的1/4。
考虑众数时最好把它和其他的类别联系起来。是否有一个类别占主导地位,或者多个类别占主导地位?据此,我们可能会问:最常见的值告诉我们被测量变量的哪些信息。如果Black和Silver是最普遍使用的二手车颜色,那么我们可以假设数据是从奢华汽车中得来的,这类汽车趋向于销售更加保守的颜色;或者它们也可能是经济型汽车,这类汽车有更少可供选择的颜色。在我们进一步检验这些数据时,我们要记住这些问题。
把众数考虑成最普遍的值,使得我们能够把统计量众数的概念应用到数值数据。严格地说,连续变量是不可能有众数的,因为没有两个值可能是重复的。然而,如果我们把众数考虑成直方图中最高的那个竖条,就能够讨论如变量price和变量mileage的众数。当探索数值数据时,考虑众数是很有帮助的,特别要检验数据是否为多峰的。
![]()
2.3.4 探索变量之间的关系
到目前为止,我们一次只检验一个变量,只计算单变量统计量。在我们的研究过程中,我们列举了当时尚不能回答的一些问题:
price数据有没有暗示我们只检验了经济类的汽车,还是检验的数据中也包括高里程的奢华汽车呢?
model和color数据之间的关系,提供了关于我们所检验的汽车类型的洞察吗?
这类问题能通过关注二变量关系,即考虑两个变量之间的关系来进行处理。超过两个变量之间的关系称为多变量关系。下面从二变量的情况开始讨论。
1.变量之间关系的可视化—散点图
散点图是一种可视化二变量之间关系的图形。它是一个二维图形,将点画在坐标平面中,该坐标平面的横坐标x是其中一个特征的值,纵坐标y由另一个特征的值来标识。坐标平面上点的排放模式,揭示了两个特征之间的内在关系。
为了回答变量price和mileage之间的关系,下面来分析一个散点图。我们将使用plot()函数以及在前面绘图中用过的标记图形的参数main、xlab和ylab。
为了使用plot()函数,我们需要指定x向量和y向量,它们含有图形中点子位置的值。尽管无论用哪个变量来表示x坐标和y坐标,结论都是一样的,但是惯例规定,y变量是假定依赖于另一个变量的变量(因此称为因变量)。因为里程表的读数不能被卖家修改,所以它不可能由汽车的价格决定。相反,我们假设price是由里程表的里程数(mileage)决定的。因此,我们将把price作为y坐标,或者称因变量。
绘制散点图的全部命令如下:
这将产生下面的散点图:
![]()
使用散点图,我们可以了解二手车的价格和里程表的读数之间的一个清晰关系。为了研究这张图,我们观察当x轴变量的值增加时,y轴变量的值是如何改变的。在这个例子中,当mileage值增加时,price值变得越来越低。如果你曾经卖过或者买过二手车,这一点不难得到。
一个更有趣的发现可能是,除了125 000英里和$14 000所构成的一个异常点以外,有很少一部分汽车同时有很高的price和很高的mileage。缺少更多这样的点,就提供了证据来支持下列结论:数据中不可能包含高里程的奢华汽车。数据中所有贵的汽车,特别是那些$17 500以上的汽车,看上去都有超低的里程数,这暗示我们可能看到的是一类全新的卖价为$20 000的汽车。
变量price和变量mileage之间的关系是负相关的,因为散点图是一条向下倾斜的直线。正相关看起来是形成一条向上倾斜的直线。一条水平的线,或者一个看上去随机分布的点集,证明两个变量完全不相关。两个变量之间线性关系的强弱是通过统计量相关系数来测量的。相关系数在第6章中详细讨论,第6章将学习如何使用回归方法建立线性关系。
注意不是所有的关联都形成直线。有时,点会形成一个U形或者V形;有时,关联模式看上去随着x变量或者y变量的增加而变弱或者变强。这样的模式说明两个变量之间的关系不是线性的。
2.检验变量之间的关系—双向交叉表
为了检验两个名义变量之间的关系,使用双向交叉表(two-way cross-tabulation,也称为交叉表或者列联表)。交叉表和散点图相类似,它允许你观察一个变量的值是如何随着另一个值的变化而变化的。双向交叉表的格式是:行是一个变量的水平,列是另一个变量的水平。每个表格的单元格中的值用来表明落在特定行、列的单元格中的值的数量。
为了回答我们关于model和color之间关系的问题,我们观察一个交叉表。R中的多个函数都能生成双向表,包括table()函数,我们也可以把table()函数用在单向表中。由Gregory R. Warnes创建的gmodels添加包中的CrossTable()函数可能是用户最喜欢用的函数,因为它在一个表格中提供了行、列和边际百分比,省去了我们要自己组合这些数据的麻烦。要想安装gmodels添加包,输入:
在安装了添加包后,仅需要输入命令library(gmodels)载入该添加包。在每次用到CrossTable()函数时,你需要在R系统中载入这个添加包。
在我们继续分析以前,让我们通过减少color变量中水平的数量来简化我们的任务。这个变量有9个水平,但是我们并不是真的需要如此详细。我们真正感兴趣的是汽车的颜色是否是保守的。为此,我们把9种颜色分为两组:第一组包括保守的颜色:Black、Gray、Silver和White;第二组包括Blue、Gold、Green、Red和Yellow。我们创建一个二元指示变量(常常称为哑变量),根据我们的定义来表示汽车的颜色是否是保守的。如果是保守的颜色,指示变量的值就是1,否则值为0。
这里,你可能注意到一个新的命令:%in%运算符,它根据左边的值是否在右边的向量中,为运算符左边向量中的每一个值返回TRUE或者FALSE。简单地说,你可以理解为“这辆二手车的颜色是在black、gray、silver和white这组中吗?”
观察由table()得到的我们新建变量的输出结果,我们看到2/3的汽车有保守的颜色,而1/3的汽车没有保守的颜色:
现在,让我们看看交叉表中conservative(保守)颜色汽车的比例是如何随着model变化而变化的。因为我们假设汽车的型号决定了颜色的选择,所以我们把conservative作为因变量(y)。CrossTable()命令的应用如下:
由此产生了下面的表格: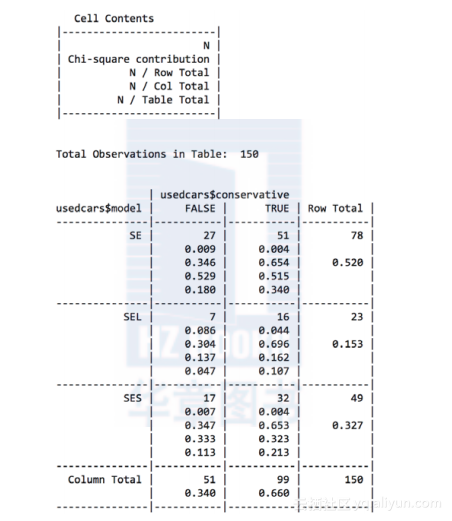
CrossTable()的输出中包含了大量数据。最上面的一张图(标示为Cell Contents)说明如何解释每一个值。表格的行表示了二手车的3个型号:SE、SEL和SES(再加上额外的一行用来表示所有型号的汇总)。表格的列表示汽车的颜色是否是保守的(加上额外的一列表示对所有两种颜色求和)。每个格子中的第一个值表示那个型号和那个颜色的汽车的数量。比例分别表示这个格子的卡方统计量,以及在行、列和整个表格中占的比例。
在表格中,我们最感兴趣的是保守颜色汽车占每一种型号的行比例。行比例告诉我们0.654(65%)的SE汽车用保守的颜色,SEL汽车的这个比例是0.696(70%),SES汽车是0.653(65%)。这些数值的差异相对来说是较小的,这暗示不同型号的汽车选择的颜色类型没有显著的差异。
卡方值指出了在两个变量中每个单元格在皮尔森卡方独立性检验中的贡献。这个检验测量了表格中每个单元格内数量的不同只是由于偶然的可能性有多大。如果概率值是非常低的,那么就提供了充足的证据表明这两个变量是相关的。
你能在引用CrossTable()函数时增加一个额外的参数,指定chisq = TRUE来获得卡方检验的结果。在这个案例中,概率值是93%,暗示单元格内数量的变化很可能仅仅是由于偶然,而不是在model和color之间真的存在关联。