1.3 概率基础和R语言
问题
如何用R语言学习概率?![]()
引言
R语言是统计语言,概率又是统计的基础,所以可以想到,R语言必然要从底层API上提供完整、方便、易用的概率计算的函数。下面就让R语言帮我们学好概率的基础课。
1.3.1 随机变量介绍
随机变量(random variable)表示随机现象各种结果的实值函数,定义在样本空间S上。由于它的自变量是随机试验的结果,而随机试验结果的出现具有随机性,因此,随机变量的取值具有一定的随机性。样本空间是随机试验的一切可能的基本结果组成的集合,记为S。样本空间的元素,即随机试验的每一个可能的结果,称为样本点。
如果随机变量x的全部可能的取值只有有限多个,则称x为离散型随机变量。如果随机变量可以在某个区间内取任意实数,即变量的取值可以是连续的无穷多个,这种随机变量就称为连续型随机变量。
本节的系统环境是:
Windows 7 64bit
R: 3.1.1 x86_64-w64-mingw32/x64 (64-bit)
R程序:生成在样本空间(1, 2, 3, 4, 5)上的离散型随机变量X,X只能取值`javascript
1, 2, 3, 4或5。
S<-1:5
x<-sample(S,1);x
[1] 2
下面的程序生成在样本空间(0, 1)上的连续随机变量Y,取10个值。y<-runif(10,0,1);y
[1] 0.3819569 0.7609549 0.6692581 0.6314708 0.5552201 0.8225527 0.7633086
0.4667188 0.1883553 0.3741653
概率分布用以表述随机变量取值的概率规律。为了方便使用,根据随机变量所属类型的不同,概率分布取不同的表现形式。
离散型分布:两点分布、二项分布、泊松分布等
连续型分布:均匀分布、指数分布、正态分布、伽玛分布等
在1.4节中,将介绍连续型分布函数的R语言实现。
**1.3.2 随机变量的数字特征**
接下来,我们将介绍随机变量的数字特征,这些指标特征都是概率论中常用的概念。数学期望、方差、标准差、分位数(最大值、最小值、中位数、四分位数)、协方差、相关系数、矩(包括原点矩、中心矩、偏度、峰度)、协方差矩阵。
1.?数学期望
离散型随机变量的一切可能的取值xi与对应的概率pi之积的和称为该离散型随机变量的数学期望(mathematical expectation),记为E(X),如公式(1.1)所示。数学期望是最基本的数学特征之一,反映随机变量平均取值的大小。我们通常也把数学期望也叫做均值。
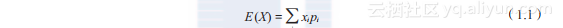
(1.1)
下面的R程序计算数据集(1,2,3,7,21)的数学期望。
> S<-c(1,2,3,7,21)
> mean(S) # 计算样本的数学期望
[1] 6.8
连续型随机变量:若随机变量X的分布函数F(x)可表示成一个非负可积函数f(x)的积分,则称X为连续型随机变量,f(x)称为X的概率密度函数,积分值为X的数学期望,记为E(X),如公式(1.2)所示。
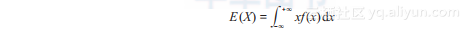
(1.2)
2.?方差
方差(variance)是各个数据与平均数之差的平方的平均数,用来度量随机变量与其数学期望之间的偏离程度。设X为随机变量,如果E{[X-E(X)]2}存在,则称E{[X-E(X)]2}为X的方差,记为Var(X),如公式(1.3)所示。
或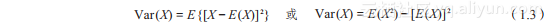
(1.3)
下面的R程序计算数据集(1,2,3,7,21)的方差。S<-c(1,2,3,7,21)
var(S) # 计算样本的方差
[1] 68.2
sum((S-mean(S))^2)/(length(S)-1) # 手动计算样本的方差
[1] 68.2
3.?标准差
标准差(standard deviation)是方差的算术平方根,反映一个数据集的离散程度。两个数据集的平均数相同,但标准差未必相同。下面的R程序计算数据集(1,2,3,7,21)的标准差。
> S<-c(1,2,3,7,21)
> sd(S) # 计算样本的标准差
[1] 8.258329
4.?分位数
众数(mode)是一组数据中出现次数最多的数值,有时众数在一组数中有好几个。下面的R程序计算数据集(1,2,3,3,3,7,7,7,7,9,10,21)的众数。
> S<-c(1,2,3,3,3,7,7,7,7,9,10,21)
> names(which.max(table(S))) # 计算众数
[1] "7"
最小值(minimum)是在给定情形下可以达到的最小数量或最小数值。下面的R程序计算数据集(2,3,3,3,7,7,7,7,9,10,21)的最小值。
> S<-c(2,3,3,3,7,7,7,7,9,10,21)
> min(S) # 最小值
[1] 2
> which.min(S) # 最小值的索引
[1] 1
最大值(maximum)是在给定情形下可以达到的最大数量或最大数值。下面的R程序计算数据集(2,3,3,3,7,7,7,7,9,10,21)的最大值。
> S<-c(2,3,3,3,7,7,7,7,9,10,21)
> max(S) # 最大值
[1] 21
> which.max(S) # 最大值的索引
[1] 11
中位数(median)是指将统计总体当中的各个变量值按大小顺序排列起来,形成一个数列,处于变量数列中间位置的变量值就称为中位数。下面的R程序计算数据集(1,2,3,4,5)的中位数。
> S<-c(1,2,3,4,5)
> median(S) # 中位数
[1] 3
四分位数(quartile)用于描述任何类型的数据,尤其是偏态数据的离散程度,即将全部数据从小到大排列,正好排列在上1/4位置叫上四分位数,下1/4位置上的数就叫做下四分位数。下面的R程序计算数据集(1,2,3,4,5,6,7,8,9)的四分位数。
> S<-c(1,2,3,4,5,6,7,8,9)
> quantile(S) # 四分位数
0% 25% 50% 75% 100%
1 3 5 7 9
> f?ivenum(S) # 5个分位值
[1] 1 3 5 7 9
R中也有通用的统计计算函数summary()。在R语言中,summary()函数对上面的几个常用统计量进行了封装,直接把数据集传入summary()函数,可以很方便地看到计算结果。下面的R程序计算数据集(1,2,3,4,5,6,7,8,9)的统计函数。
> S<-c(1,2,3,4,5,6,7,8,9)
> summary(S) # 统计函数
Min. 1st Qu. Median Mean 3rd Qu. Max.
1 3 5 5 7 9
5.?协方差
协方差(covariance)用于衡量两个变量的总体误差。而方差是协方差的一种特殊情况,即当两个变量是相同的情况。设X,Y为两个随机变量,称E{[X-E(X)][Y-E(Y)]}为X和Y的协方差,记为Cov(X,Y),如公式(1.4)所示。
(1.4)
下面的R程序计算X(1,2,3,4)和Y(5,6,7,8)的协方差。
> X<-c(1,2,3,4)
> Y<-c(5,6,7,8)
> cov(X,Y) # 协方差
[1] 1.666667
6.?相关系数
相关系数(correlation coeff?icient)是用来反映变量之间相关关系密切程度的统计指标。相关系数是按积差方法计算,同样以两变量与各自平均值的离差为基础,通过两个离差相乘来反映两变量之间的相关程度。当Var(X)>0, Var(Y)>0时,称为X与Y的相关系数,如公式(1.5)所示。
(1.5)
下面的R程序计算X(1,2,3,4)和Y(5,7,8,9)的相关系数。
> X<-c(1,2,3,4)
> Y<-c(5,7,8,9)
> cor(X,Y) # 相关系数
[1] 0.9827076
7.?矩
矩是广泛应用的一类数学特征,均值和方差分别就是一阶原点矩和二阶中心矩。
原点矩(moment about origin):对于正整数k,如果E(X?k)存在,称ak=E(X?k)为随机变量X的k阶原点矩。X的数学期望是X的一阶原点矩,即E(X),如公式(1.6)所示。
(1.6)
下面的R程序计算S(1,2,3,4,5)的一阶原点矩(均值)。
> S<-c(1,2,3,4,5)
> mean(S) # 一阶原点矩
[1] 3
中心矩(moment about centre):对于正整数k,如果E(X)存在,且E([X-E(X)]k)也存在,则称E[X-E(X)]k为随机变量X的k阶中心矩。X的方差是X的二阶中心矩,即E([X-E(X)]k),如公式(1.7)所示。
(1.7)
下面的R程序计算S(1,2,3,4,5)的二阶中心矩(方差)。
> S<-c(1,2,3,4,5)
> var(S) # 二阶中心矩
[1] 2.5
偏度(skewness)是统计数据分布偏斜方向和程度的度量,是统计数据分布非对称程度的数字特征。设分布函数F(x)有中心矩μ2=E(X-E(X))2, μ3=E(X-E(X))3,则Cs=μ3/μ2^(3/2)为偏度系数,如公式(1.8)所示。
(1.8)
当Cs>0时,概率分布偏向均值右侧;当Cs<0时,概率分布偏向均值左侧。
下面的R程序计算10?000个正态分布的数据集的偏度。
> library(PerformanceAnalytics) # 加载PerformanceAnalytics包
> S<-rnorm(10000) # 取10000个正态分布随机变量的样本点
> skewness(S) # 计算偏度
[1] -0.00178084
> hist(S,breaks=100) # 画出正态分布的柱状图,如图1-10所示
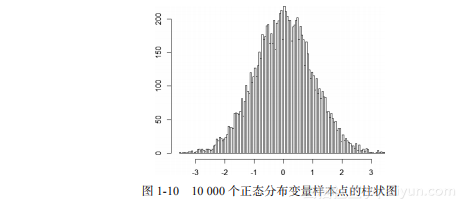
图1-10 10?000个正态分布变量样本点的柱状图
峰度(kurtosis)又称峰态系数,表征概率密度分布曲线在平均值处峰值高低的特征数。峰度刻划不同类型的分布的集中和分散程序。设分布函数F(x)有中心矩μ2=E(X-E(X))2, μ4=E(X-E(X))4,则Ck=μ4/μ22-3为峰度系数,如公式(1.9)所示。
(1.9)
R语言计算正态分布的一个大小为10?000的样本(同偏度的样本数据)的峰度:
> kurtosis(S) # 计算峰度
[1] -0.02443549
8.?协方差矩阵
协方差矩阵(covariance matrix)是一个矩阵,它的每个元素是各个向量元素之间的协方差,这是从一维随机变量到多维随机向量的自然推广。设X=(X1, X2, … ,Xn), Y=(Y1, Y2, …, Ym)为两个随机变量,则Cov(X,Y)为X,Y的协方差矩阵,如公式(1.10)所示。
(1.10)
R语言计算协方差矩阵如下。
> x=as.data.frame(matrix(rnorm(10),ncol=2))
> x
V1 V2
1 -2.11315384 -2.55189840
2 -0.96631271 -1.36148355
3 -0.02835058 -0.82328774
4 -1.86669567 -0.07201353
5 0.27324957 -2.23835218
> cov(x) # 协方差矩阵
V1 V2
V1 1.13470650 -0.09292042
V2 -0.09292042 1.03172261
1.3.3 极限定理
1.?大数定律
大数定律(law of large numbers)又称大数定理,是判断随机变量的算术平均值是否向常数收敛的定律,是概率论和数理统计学的基本定律之一。
设X1, X2, …, Xk是随机变量序列且E(Xk)存在(k=1, 2, 3, …), 令Yn=(X1+X2+…+Xk)/n,若对于任意给定的ε>0,有公式(1.11)成立,
或 (1.11)
则称随机变量序列{Xk}服从大数定律。
作为上述定理的特殊情况,利用Chebyshev不等式,设随机变量X具有数学期望E(X)=μ,方差Var(X)=σ2,则对于任意ε>0,如公式1.12所示。
(1.12)
假设投掷一枚硬币,得到正面的概率是0.5,投4次时,计算得到2次正面的概率?根据大数定律,如果投10?000次,计算得到5000次正面的概率?
计算2次正面的概率:
> choose(4,2)/2^4 # choose组合数的计算:从4中选择2个
[1] 0.375
计算5000次正面的概率:
> pbinom(5000, 10000, 0.5) # pbinom二向分布,5000为分位数,产生10000个随机数,每个概率0.5
[1] 0.5039893
2.?中心极限定理
中心极限定理(central limit theorem)是判断随机变量序列部分和的分布是否渐近于正态分布的一类定理。在自然界及生产科学实践中,一些现象受到许多相互独立的随机因素的影响,如果每个因素的影响都很小,那么总的影响可以看做是服从正态分布。中心极限定理正是从数学上论证了这一现象。设从均值为μ、方差为σ2(有限)的任意一个总体中抽取样本量为n的样本,则当n充分大时,样本均值的抽样分布近似服从均值为μ、方差为σ2/n的正态分布。两个最著名的中心极限定理是列维(Levy)定理和拉普拉斯(Laplace)定理。
列维定理即独立同分布随机变量序列的中心极限定理。它表明,独立同分布且数学期望和方差有限的随机变量序列的标准化和以标准正态分布为极限。
设随机变量X1, X2, …Xn, …相互独立,服从同一分布,且具有数学期望和方差:E(Xk)=μ,D(Xk)=σ2>0(k=1,2,…), 则随机变量之和的标准化变量的分布函数Fn(x)对于任意x满足Fn(x)=Φ(x),其中Φ(x)是标准正态分布的分布函数。
拉普拉斯定理即服从二项分布的随机变量序列的中心极限定理。它指出,参数为n, p的二项分布以np为均值、np(1-p)为方差的正态分布为极限。
R程序的中心极限定理动画模拟(从指数分布到正态分布)如图1-11所示。代码摘自animation包帮助文档。
> if (!require(animation)) install.packages("animation")
> library(animation)
> ani.options(interval = 0.1, nmax = 100)
> par(mar = c(4, 4, 1, 0.5))
> clt.ani()
掌握R语言,就可以方便地运用概率的知识进行各种概率计算,非常有利于帮助我们解决生活中遇到的问题。时间: 2024-09-30 01:43:19