2.6 小结
OpenACC是一种描述型并行编程模型。在本章中,通过一个测试函数的应用,使用了OpenACC的多种特性来描述并行度和数据操控,并针对特定平台对代码进行了优化。尽管使用的是PGI编译器和PGProf性能调试器,但类似的优化流程也是适用于任何支持OpenACC工具包的应用的。
1.获得应用程序的性能分析结果,辨识和挖掘代码中的可并行之处。
2.逐步向编译器描述代码中可挖掘出的并行性。如果主机端和设备端使用各自的存储器,这一步骤后获得的代码很可能会减速。
3.描述应用程序的数据移动。编译器通常关注于数据移动等细节并确保正确性,但开发者具有更广的视野并真正了解哪些数据是在多个包含OpenACC区域的子函数中共享的。数据和数据移动的描述完毕后,在分离式存储架构的加速器上会获得极大的性能提升。
4.最后,利用读者对应用程序和目标加速器架构的深入了解对循环进行优化。积少成多的不断优化和不懈努力可能会使得编译器对循环达到更为深入的解析,获取更大的性能提升。
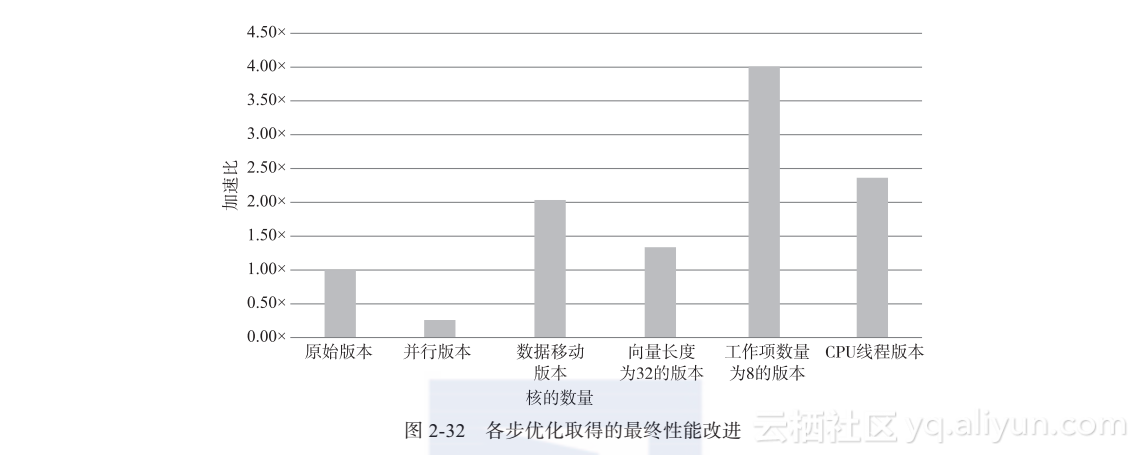
图2-32展示了最终的并行程序性能,这是针对每一步优化产生的结果,与原始串行程序相比,注意到最终代码获得了4倍的加速效果,多核版本获得了接近2.5倍的加速效果。尽管在优化过程中,代码可能会减速,从中可以明显看到为什么某些优化反而导致了性能衰减,以及经过进一步改进后获得的性能提升。最终成果是一套代码,可用于各种类型的设备,还对一个特定架构的设备进行了针对性优化,且不会对其架构的代码产生不良影响。一言以蔽之,这便是OpenACC编程,即向编译器提供充足信息,以使代码能够有效地运行于任意现代处理机上。
时间: 2024-07-30 03:12:07