12.33 众包知识库补全方法概览
本章介绍众包知识库补全的方法概览,如图 1所示。其基本思想包含两个部分,其一,利用多种数据源,如现有的多个知识库、Web 结构化数据等,提取知识数据,并将不同数据源的知识数据融合起来,以此补全知识库;其二,在融合的过程中有效地利用众包,通过众包模型细化出具体可供众包完成的任务,利用众包优化算法进行质量和成本的控制,以选择出最优的任务发布到众包平台,如美国亚马逊公司的 Mechanical Turk ( 简称 MTurk) 1 。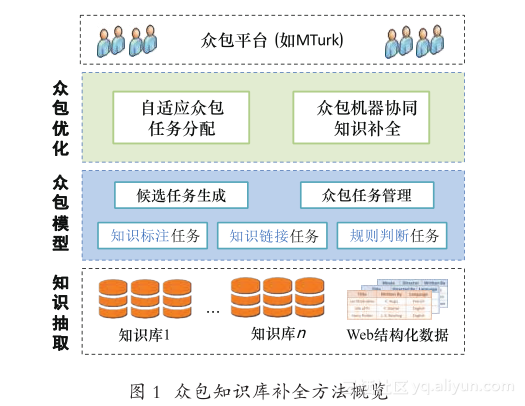
知识抽取:提出利用多类数据源进行抽取,其优势在于使不同源的知识数据互相进行补充,为知识库补全提供数据基础。具体考虑以下数据源:① 多 个 现 有 知 识 库, 如 YAGO [1] 、DBpedia [3] 和Freebase [5] 等,这些知识库构造的方法不尽相同,数据间存在互补;② Web 结构化数据,如 HTML表格[33] ,这些数据规模巨大且具有一定的结构特征,如微软在 2012 年报告存在近 6 亿的 HTML 表格。在此基础上,提取知识元组(主语 - 谓词 - 宾语)。注:由于提出方法的重点在利用众包,因此在知识抽取方面使用了现有的抽取技术。
众包模型:构建利用众包进行知识库补全的基本模型,即将知识库补全这一复杂工作分解成细粒度的众包任务,以分发给大量众包工人进行求解。在此过程中,需要进行候选任务的生成和众包任务的管理工作。具体来讲,提出以下三类基本众包任务。
● 知识标注任务:这类任务要求众包工人直接对知识元组的正确性进行判断,即给定抽取的知识元组 (s, p, o)(符号 s、p 和 o 分别表示主语、谓词和宾语,是一般表示知识的形式),希望众包工人返回 1(表示元组正确)或是 0(表示元组不正确)。
● 知识链接任务:这类任务利用众包对不同数据源的知识元组进行链接。具体而言,给定抽取自不同知识源的两个元组 (s 1 , p 1 , o 1 ) 和 (s 2 , p 2 , o 2 ),这类任务支持以下两种链接:① 实体链接:即判断充当主语或宾语的实体间尽管表示不同,但实际指代同一真实实体,可以链接起来;② 关系链接,即判断关系 p 1 和 p 2 指代的是同一种关系。
● 规则判断任务:这类任务使用众包对知识推理的规则进行判断。知识库中的其他元组对判断某一元组是否存在具有推理作用。具体而言,如要判断元组 (s, p, o) 是否成立,可以参考将主语 s 和宾语 o 关联起来的其他元组,如 (s, p 1 , e) 和 (e, p 2 , o)。这类任务就是判断 (s, p 1 , e) 和 (e, p 2 , o) 如果存在,是否能够推断出 (s, p, o) 就很可能存在。
例如,考虑判断姚明国籍(为了示例,我们假设知识库中姚明的国籍信息缺失)。知识标注任务是让众包直接判断 ( 姚明 , 国籍 , 中国 ) 元组是否正确;知识链接任务是将姚明与某篮球队员 HTML 表格上的姚链接,将关系国籍与如所属国家链接,以此将该表格上的中国填充到国籍的宾语中。规则判断任务是让众包判断 ( 姚明 , 出生地 , 上海 )、( 上海 ,所属国 , 中国 ) 这两个元组是否对判断国籍有帮助。
众包优化:如前所述,众包知识库补全面临着两大挑战:① 质量控制:与传统简单的众包工作(如图片标注、实体识别)不同,知识库补全更为复杂,需要众包工人具有一定的领域背景知识,如做上述判断国籍的题目需要对篮球队员有所了解。为此,本文提出自适应众包任务分配技术,详见第 3 章;② 成本控制:众包并不免费。由于知识库体量巨大,如不能有效地控制成本,众包知识库补全会引入难以承受的金钱开销。为此,本文提出众包机器协同的补全技术,详见第 4 章。