性能优化
1、线程映射
所谓线程映射是指某个线程访问哪一部分数据,其实就是线程id和访问数据之间的对应关系。
合适的线程映射可以充分利用硬件特性,从而提高程序的性能,反之,则会降低性能。
请参考Static Memory Access Pattern Analysis on a Massively Parallel GPU这篇paper,文中讲述线程如何在算法中充分利用线程映射。这是我在google中搜索到的下载地址:http://www.ece.neu.edu/~bjang/patternAnalysis.pdf
使用不同的线程映射,同一个线程可能访问不同位置的数据。下面是几个线程映射的例子:

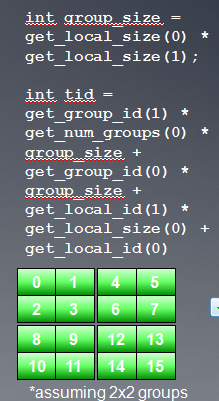
我们考虑一个简单的串行矩阵乘法:这个算法比较适合输出数据降维操作,通过创建N*M个线程,我们移去两层外循环,这样每个线程执行P个加法乘法操作。现在需要我们考虑的问题是,线程索引空间究竟应该是M*N还是N*M?
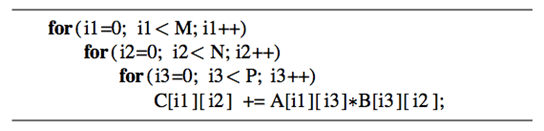
当我们使用M*N线程索引空间时候,Kernel如下图所示:

而使用N*M线程索引空间时候,Kernel如下图所示:![]()
使用两种映射关系,程序执行结果是一样的。下面是在nv的卡GeForce 285 and 8800 GPUs上的执行结果。可以看到映射2(及N*M线程索引空间),程序的performance更高。
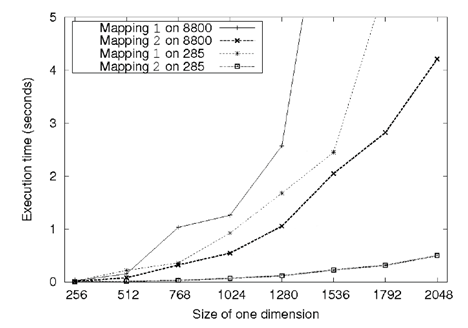
性能差异主要是因为在两种映射方式下,对global memory访问的方式有所不同。在行主序的buffer中,数据都是按行逐个存储,为了保证合并访问,我们应该把一个wave中连续的线程映射到矩阵的列(第二维),这样在A*B=C的情况下,会把矩阵B和C的内存读写实现合并访问,而两种映射方式对A没有影响(A由i3决定顺序)。
完整的源代码请从:http://code.google.com/p/imagefilter-opencl/downloads/detail?name=amduniCourseCode4.zip&can=2&q=#makechanges下载,程序中我实现了两种方式的比较。结果确实第二种方式要快一些。
下面我们再看一个矩阵转置的例子,在例子中,通过改变映射方式,提高了global memory访问的效率。
矩阵转置的公式是:Out(x,y) = In(y,x)
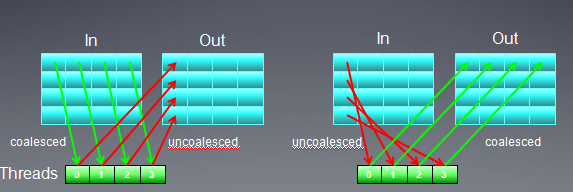
从上图可以看出,无论采取那种映射方式,总有一个buffer是非合并访问方式(注:在矩阵转置时,必须要把输入矩阵的某个元素拷贝到临时位置,比如寄存器,然后才能拷贝到输出矩阵)。我们可以改变线程映射方式,用local memory作为中间元素,从而实现输入,输出矩阵都是global memory合并访问。
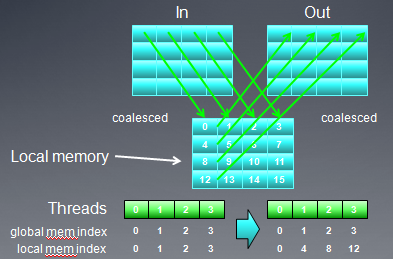
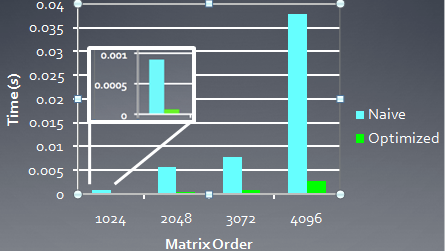
下面是AMD 5870显卡上,两种线程映射方式实现的矩阵转置性能比较:
2、Occupancy
前面的教程中,我们提到过Occupancy的概念,它主要用来描述CU中资源的利用率。
OpenCL中workgroup被映射到硬件的CU中执行,在一个workgroup中的所有线程执行完之后,这个workgroup才算执行结束。对一个特定的cu来说,它的资源(比如寄存器数量,local memory大小,最大线程数量等)是固定的,这些资源都会限制cu中同时处于调度状态的workgroup数量。如果cu中的资源数量足够的的话,映射到同一个cu的多个workgroup能同时处于调度状态,其中一个workgroup的wave处于执行状态,当处于执行状态的workgroup所有wave因为等待资源而切换到等待状态的话,不同workgroup能够从就绪状态切换到ALU执行,这样隐藏memory访问时延。这有点类似操作系统中进程之间的调度状态。我简单画个图,以供参考:

- 对于一个比较长的kernel,寄存器是主要的资源瓶颈。假设kernel需要的最大寄存器数目为35,则workgroup中的所有线程都会使用35个寄存器,而一个CU(假设为5870)的最大寄存器数目为16384,则cu中最多可有16384/35=468线程,此时,一个workgroup中的线程数目(workitem)不可能超过468,
- 考虑另一个问题,一个cu共16384个寄存器,而workgroup固定为256个线程,则使用的寄存器数量可达到64个。
每个CU的local memory也是有限的,对于AMD HD 5XXX显卡,local memory是32K,NV的显卡local memory是32-48K(具体看型号)。和使用寄存器的情况相似,如果kernel使用过多的local memory,则workgroup中的线程数目也会有限制。
GPU硬件还有一个CU内的最大线程数目限制:AMD显卡256,nv显卡512。
NV的显卡对于每个CU内的激活线程有数量限制,每个cu 8个或16个warp,768或者1024个线程。
AMD显卡对每个CU内的wave数量有限制,对于5870,最多496个wave。
这些限制都是因为有限的资源竞争引起的,在nv cuda中,可以通过可视化的方式查看资源的限制情况。
3、向量化
向量化允许一个线程同时执行多个操作。我们可以在kernel代码中,使用向量数据类型,比如float4来获得加速。向量化在AMD的GPU上效果更为明显,这是因为AMD的显卡的stream core是(x,y,z,w)这样的向量运算单元。
> 下图是在简单的向量赋值运算中,使用float和float4的性能比较。

kernel代码为:
