
数周前,在伦敦 Heathrow 机场等飞机的空闲中,我顺便处理了一些工作上的事情。不经意间发现 Github 在性能方面的一些问题,颇为诧异。通过新 tab 打开的页面,其加载速度竟然比直接点击链接打开的页面要快。
点击链接的同时复制链接并在新的 tab 页中打开。可以看到,尽管先点击的是链接,但渲染更快的却是新 tab 中打开的页面。
有一说一
页面加载的时候,浏览器会接收网络数据流,并将其输出(pipe)给 HTML 解析器,HTML 解析器再将数据输出到文档。这意味着,页面是边加载边渲染的。对于一个 100k 的页面来说,浏览器很可能在接收到 20k 数据的时候就开始渲染出一些可用内容了。
这个伟大又古老的特性,常常被开发者们有意无意地忽略了。多数提高加载性能的建议都归结于一点,即“展示你所拿到的东西” —— 别怕,千万不要傻傻等待一切加载完成之后再去展示内容。
GitHub 当然是关注性能的,所以他们使用服务端渲染。但在同一个 tab 下浏览页面时,他们用 JavaScript 重新实现了导航(navigation)功能,类似下面这样:
- // …一堆重新实现浏览器导航功能代码…
- const response = await fetch('page-data.inc');
- const html = await response.text();
- document.querySelector('.content').innerHTML = html;
- // …加载更多重新实现导航功能的代码…
这违反了规则,因为在 page-data.inc 下载完成之前什么事情都没干。而服务端渲染版完全不会这样囤积内容,其内容是流式的,这样就要快得多了。就 Github 的客户端渲染来说,很多 JavaScript 代码完全减慢了渲染过程。
这里我仅仅只是拿 Github 举例子 —— 这种反模式在单页应用中比比皆是。
在页面之内切换内容可能确实有些好处,特别是存在大量脚本的情况下,无需重新执行全部脚本即可更新内容。但我们能否在不放弃流的情况下完成这样的工作呢?我曾经常说 JavaScript 没有办法对流进行解析,但其实还是有的……
<iframe> 和 document.write 大法
iframe 早已跻身圈内最臭黑科技之列。但下面这个办法就使用了 iframe 和 document.write(),这样我们就能将内容以流的形式添加到页面中了。示例如下:
- // 创建 iframe:
- const iframe = document.createElement('iframe');
- // 添加到 document 中 (记得隐藏起来):
- iframe.style.display = 'none';
- document.body.appendChild(iframe);
- // 等待 iframe 加载:
- iframe.onload = () => {
- // 忽略其他 onload 操作:
- iframe.onload = null;
- // 添加一个虚拟标签:
- iframe.contentDocument.write('<streaming-element>');
- // 引用该元素:
- const streamingElement = iframe.contentDocument.querySelector('streaming-element');
- // 将该元素从 iframe 中取出,并添加到文档中:
- document.body.appendChild(streamingElement);
- // 写入一些内容 —— 这里应该是异步的:
- iframe.contentDocument.write('<p>Hello!</p>');
- // 继续写入内容,直到完成:
- iframe.contentDocument.write('</streaming-element>');
- iframe.contentDocument.close();
- };
- // iframe 初始化
- iframe.src = '';
虽然 Hello! 是写到 iframe 中的,但它却出现在了父级的 document 中!这是因为解析器维护了一个 敞开元素栈(stack of open elements),新创建的元素会被压入栈中。就算我们把 <streaming-element/> 元素移出到 iframe 外面也不影响,就是这么任性。
此外,这种技术处理起 HTML 来,要比 innerHTML 更接近标准的页面加载解析器。尤其是脚本依然会被下载,并在父级文档的上下文中执行 —— 只是在 Firefox 中完全不会执行,但我认为这是个 bug更新: 其实脚本根本不应该执行(感谢 Simon Pieters 指出这一点),但 Edge、Safari、Chrome 都这么干。
接下来我们只需要从服务端获取 HTML 数据流,每当一个部分的数据到达的时候,就调用 iframe.contentDocument.write()。流式传输和 fetch() 搭配起来会更好,但为了支持 Safari,我们还是使用 XHR 来 hack 一下吧。
我已经写好了一个 demo,可以拿来和 Github 进行对比。下面是在 3G 网络下的测试结果:
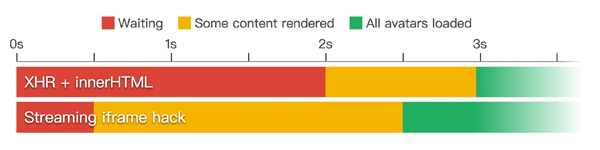
使用 iframe 进行流式渲染,页面加载速度提高了 1.5 s。头像也提前半秒钟加载完成 —— 流式渲染意味着浏览器可以更早发现它们,并与内容一起并行下载。
上面的方法对 Github 来说还是有效的,因为它的服务器返回的是 HTML。如果你使用的是框架,由框架自己管理 DOM 的展示,那可能就麻烦一些了。这种情况下可以看看下面这个次优选项:
换行符分隔的 JSON
许多网站使用 JSON 驱动动态内容。何其不幸,JSON 并不是一种对流友好的格式。尽管也有流式 JSON 解析器,可用起来却并不那么简单。
所以与其传输下面这样一大块 JSON 数据:
- {
- "Comments": [
- {"author": "Alex", "body": "…"},
- {"author": "Jake", "body": "…"}
- ]
- }
还不如像下面这样一行输出一个 JSON 对象:
- {"author": "Alex", "body": "…"}
- {"author": "Jake", "body": "…"}
这种被称为 “换行符分隔的 JSON” 是有标准的:ndjson。给上面的内容写一个解析器就要简单多了。到了 2017 年,我们也许可以使用一系列组合变换流(composable transform streams)来描述(译者注:本文写作于 2016 年 12 月):
- // 在 2017 年的某个时候可能会是这样:
- const response = await fetch('comments.ndjson');
- const comments = response.body
- // 从字节到文本:
- .pipeThrough(new TextDecoder())
- // 一直缓冲,直到遇到换行符:
- .pipeThrough(splitStream('\n'))
- // 将内容块解析为JSON:
- .pipeThrough(parseJSON());
- for await (const comment of comments) {
- // 处理每条评论,并将其添加到页面:
- // (不管你使用的是什么模板或虚拟 DOM)
- addCommentToPage(comment);
- }
在上面的代码中,splitStream 和 parseJSON 是 可复用变换流(reusable transform streams)。与此同时,为了实现最大程度的兼容,我们可以使用 XHR 进行 hack。
我再次新建了一个对比的 demo,下面是 3G 网络下的结果:
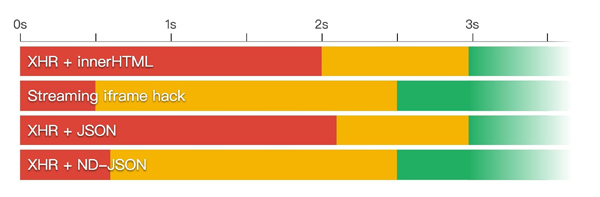
与常规 JSON 相比,ND-JSON 提前 1.5s 将内容渲染到页面上,尽管速度不如 iframe 方法那么快。在创建元素之前,必须等待完整的 JSON 对象出现。如果你的 JSON 文件体量巨大,可能会陷入对流的企盼之中。
单页应用?别着急
如前所述,Github 使用了大量的代码,然而却带来这样的性能问题。在客户端重新实现导航功能是困难的,如果你需要改变页面中的大块内容,这么做有可能并不值得。
可以拿我们的尝试与简单浏览器导航进行对比:
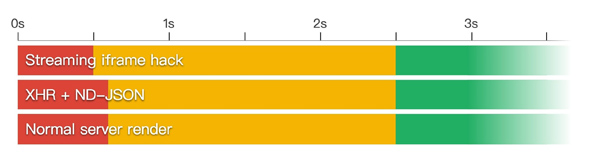
打开一个简单的没有使用 JavaScript 浏览器导航的服务端渲染页面的速度差不多是一样的。但除去评论列表,测试页面实在太过简单。如果在不同页面之间存在有大量重复的复杂内容(主要是指可怕的广告脚本),结果可能因实际情况而有差异,但一定要记得进行测试!很可能你编写了一大堆代码,然而只能带来少的可怜的提升,甚至还可能减慢速度。
原文发布时间为:2017-10-13
本文作者:Jake
本文来自合作伙伴“51CTO”,了解相关信息可以关注。