第1章
什么是数据分析
1.1 一眼就看到结论还需要数据分析吗
在我做数据分析培训和咨询的时候,时不时会有学员或者客户流露出这样的情绪:
我们的企业其实是不需要数据分析的。
我们公司的业务情况,我很清楚,分析不分析都那样,反正我都知道了。
公司的数据好简单啊,就那么几列,有啥好分析的。
公司里面的很多数据都是造假的,没有分析的价值。
在以上问题中,除了数据质量,其他问题都与企业数据的可分析度有关。数据质量确实是数据分析很难解决的问题,如果企业员工出于种种原因总是在编造各种假数据,这应该属于职业道德或者企业管理水平(企业应该通过严格严谨的管理流程使得员工无从造假)的范畴,这里暂且不讨论。那么,什么是数据的可分析度呢?
这个问题实际上包含如下两层意思:
1)这个企业的数据是比较复杂的,一眼是看不到结论的,需要使用一些工具、模型、方法进行分析。
2)关于数据的分析是有价值的,也就是说分析的过程和结论对于企业是有价值的,能够对企业的生产经营等带来促进和提高。
因此,在数据的可分析度方面,我们需要有一些判断的维度,以帮助我们辨识数据是否值得分析,这里所说的维度主要考虑企业数据量、数据复杂度、数据颗粒度这三个方面(如图1-1所示)。
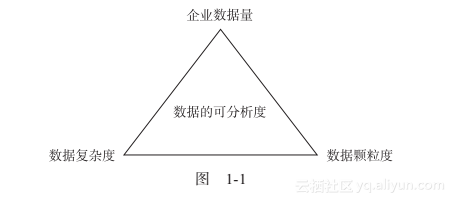
1.1.1 企业数据量
企业数据量是企业可分析度的第一要素,企业数据量的大小往往取决于两个因素:
一是企业的行业属性,二是企业的信息化程度。众所周知,互联网行业往往也是产生大量数据的行业,“BAT”不仅仅引领了各自行业的发展,同时也是数据行业发展的标杆。
一般情况下,企业的数据量跟企业的规模呈正相关关系,中等以上规模的企业数据量均比较大。但是也有例外,我曾经接触过一家从事智能手机操作系统推送业务的公司,该公司规模很小,只有40多人,但是由于合作方是国内诸多智能手机的生产企业,因此该企业的手机用户数量有3000多万,每天产生的业务数量高达几GB。
1.1.2 数据复杂度
如果说数据量相当于数据的行,那么数据复杂度就相当于数据的列。某公司营销部曾给我发来的数据样例,总共的列数加在一起是12列。该公司要求分析客户数据,但是涉及客户资料的数据基本上就是客户名称、客户行业(行业数据还是不全的)这两列,客户注册资本、销售收入、雇佣人数都没有,怎么分析?
做过数据分析的人肯定都知道“巧妇难为无米之炊”的苦楚!请想想,你提供的客户数据就是寥寥数列,那要怎么去分析?怎么做文章?
到目前为止,并没有什么明确的指标来度量数据量与数据复杂度,我们很难说每天的数据超过3万行就算数据量多,或者说数据超过30列就算数据复杂。特别是数据复杂度,这中间还有一个数据相关性的问题:以案例文件1.1为例,虽然其中的数据是3列,但是用EXCEL自带的“数据分析”模块中的“相关分析”进行分析(相关系数的函数,后面会详细讲解),我们发现第二列“销售数量”和第三列“销售额”之间的相关系数是1(完全相关),如图1-2所示。
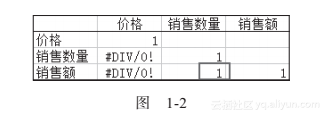
从数据分析的角度看,这里实际上是两列数据而不是3列,换句话说,第3列的销售额数据属于“衍生指标”,因为单价30是固定的,我们只需要用销售量这个数据就可以反映销售的状况。
因此通过数据的列数来衡量数据复杂度其实也未必准确,而是应该看剔除相关性之后的列数。
1.1.3 数据颗粒度
数据颗粒度指的是从不同的层次来看待数据。很难用语言来形容数据颗粒度的重要性,还是通过一个例子来说明一下。炒过股票、用过股票软件的人都知道各种周期的分析(如图1-3所示)。
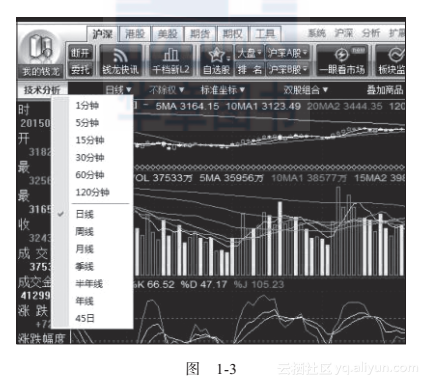
从图1-3可以看出,股票有1分钟、5分钟、15分钟、30分钟等多个观察周期,而各种周期之间存在着相互包含的关系,例如5分钟的周期线实际上是由5个1分钟的周期线组合而成的,而15分钟的周期线是由3个5分钟周期线组合而成,以此类推。因此,我们说股票数据的颗粒度是:1分钟、5分钟……
其他颗粒度的例子还有很多,例如在分析各地GDP的数据时,涉及全国、省、市、区(县)等颗粒度;考虑家电产品的维度时,也有家电、白色家电、冰箱、型号等颗粒度。
理解了颗粒度之后,就很容易理解如下道理:数据的颗粒度越细越好,因为有了细颗粒度的数据,就可以自行组合成颗粒度比较“粗”的数据。例如我们知道了全国各个区(县)的GDP数据,就可以推算出市、省、全国的数据,但是反向的操作无法实现,即知道了市的GDP数据,未必能够知道下辖区(县)的GDP数据。
综上所述,可以得到如下结论:企业数据量比较大的、复杂度比较高的、颗粒度比较细的数据,就有比较高的分析和利用价值。