3.6 运行Hadoop的HDFS
没有分布式存储的分布式框架是不完整的。HDFS是其中的一种分布式存储。即使Spark在本地模式下运行,它仍然可以在后台使用分布式文件系统。与Spark将计算任务分解成子任务一样,HDFS也会将文件分成块,并将它们存储在集群上。为了实现高可用性(High Availability,HA),HDFS会为每个块存储多个副本,副本数称为复制级别,默认为三个(见图3-5)。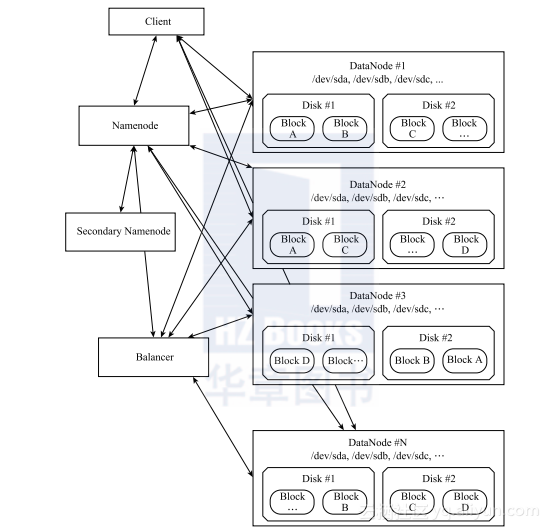
图3-5 HDFS架构。每个块存储在三个(复制级别)单独的位置
Namenode通过记录块位置以及其他元数据(例如所有者、文件权限和块大小)来管理特定文件的HDFS存储。辅助Namenode是一个轻微的misnomer:它的功能是将元数据的修改和编辑合并到fsimage中,或作为元数据的数据库文件。合并是需要的,因为更实用的方式是将fsimage的修改写入单独的文件,而不是把每个修改直接保存到fsimage的磁盘映像中(除非是保存内存中相应的改变)。辅助Namenode不能作为Namenode的第二个副本。可通过平衡器来移动块,使整个服务器上维持大致相等的磁盘使用率。如果有足够的可用空间并且客户端不在集群上运行,则按随机的方式来分配节点的初始块。最后,为了获取元数据和块位置,可在客户端与Namenode之间进行通信,但在此之后,直接会从节点的副本读取或写入数据。客户端是唯一可在HDFS集群外运行的组件,但它需要与集群中所有节点的网络连接。
如果任何节点死机或断开与网络的连接,Namenode会通知这种变化,因为它一直通过心跳来保持与节点之间的联系。如果节点在10分钟(默认情况)内没有重新连接到Namenode,为了得到节点上丢失块所需的复制级别,它会复制块。Namenode中有一个单独的块扫描器线程,它通过扫描块来得到可能的位旋转(每个块维护的校验和),并将删除损坏和孤立的块:
1.要在计算机上启动HDFS(复制级别为1),可先从http://hadoop.apache.org下载Hadoop的发行版本。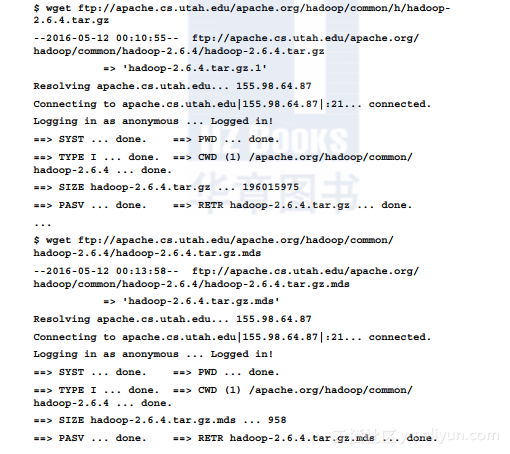

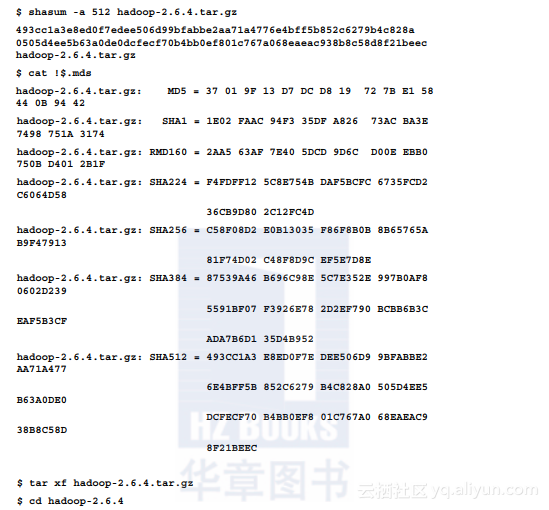
2.要获取最小的HDFS配置,请按如下方式修改core-site.xml和hdfs-site.xml文件:

这将会把Hadoop HDFS元数据和数据目录放在/tmp/hadoop- $ USER目录。为了能更永久保存,可添加dfs.namenode.name.dir、dfs.namenode.edits.dir和dfs.datanode.data.dir参数,但这里暂时不介绍这些内容。为了得到定制的发行版,可从http://archive.cloudera.com/cdh下载一个Cloudera版本。
3.首先需要格式化一个空的元数据: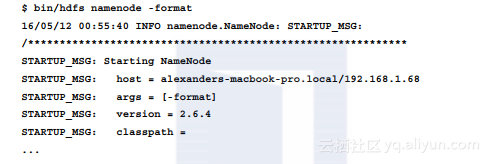
4.然后启动与namenode、secondarynamenode和datanode相关的Java进程(通常打开三个不同的命令行窗口来查看日志,但在生产环境中,它们通常是守护进程):
5.下面将创建一个HDFS文件: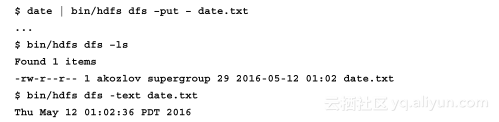
6.当然,在这种特殊情况下,文件只存储在一个节点上,这个节点与运行在本地主机上的datanode是同一个节点。在作者的机器上会有如下结果:
7.可通过http://localhost:50070来访问Namenode UI,并且会显示主机的信息,包括HDFS的使用情况和DataNode的列表,以及HDFS主节点的从节点,具体信息如下图所示: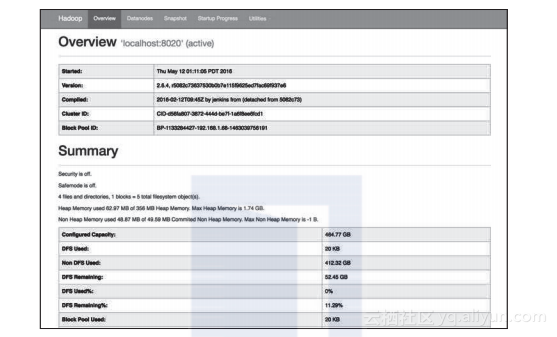
图3-6 HDFS NameNode UI的截图
上图显示了单节点部署中HDFS Namenode的HTTP UI(通常可通过http://: 50070来访问)。通过Utilities菜单中的Browse可浏览和下载HDFS文件。增加节点的方法为:在不同节点上启动DataNode,并将参数fs.defaultFS = : 8020指向Namenode。辅助Namenode HTTP UI通常位于http:: 50090。
Scala/Spark默认使用本地文件系统。但是,如果core-site/xml文件在类路径上或放在$ SPARK_HOME/conf目录中,Spark将使用HDFS作为默认值。