1.5 网络编程
既然是做爬虫开发,必然需要了解Python网络编程方面的知识。计算机网络是把各个计算机连接到一起,让网络中的计算机可以互相通信。网络编程就是如何在程序中实现两台计算机的通信。例如当你使用浏览器访问谷歌网站时,你的计算机就和谷歌的某台服务器通过互联网建立起了连接,然后谷歌服务器会把把网页内容作为数据通过互联网传输到你的电脑上。
网络编程对所有开发语言都是一样的,Python也不例外。使用Python进行网络编程时,实际上是在Python程序本身这个进程内,连接到指定服务器进程的通信端口进行通信,所以网络通信也可以看做两个进程间的通信。
提到网络编程,必须提到的一个概念是Socket。Socket(套接字)是网络编程的一个抽象概念,通常我们用一个Socket表示“打开了一个网络链接”,而打开一个Socket需要知道目标计算机的IP地址和端口号,再指定协议类型即可。Python提供了两个基本的Socket模块:
- Socket,提供了标准的BSD Sockets API。
- SocketServer,提供了服务器中心类,可以简化网络服务器的开发。
下面讲一下Socket模块功能。
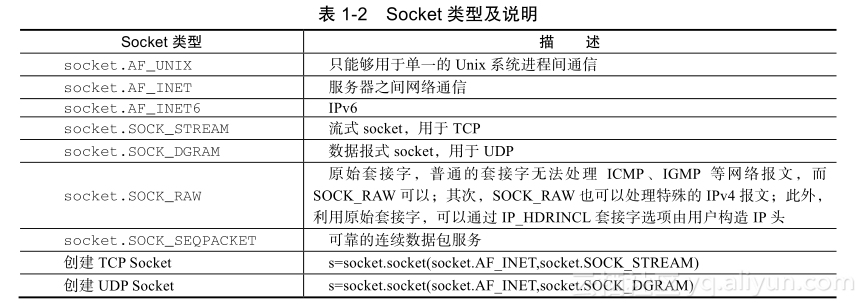
1.?Socket类型
套接字格式为:socket(family,type[,protocal]),使用给定的地址族、套接字类型(如表1-2所示)、协议编号(默认为0)来创建套接字。

2.?Socket函数
表1-3列举了Python网络编程常用的函数,其中包括了TCP和UDP。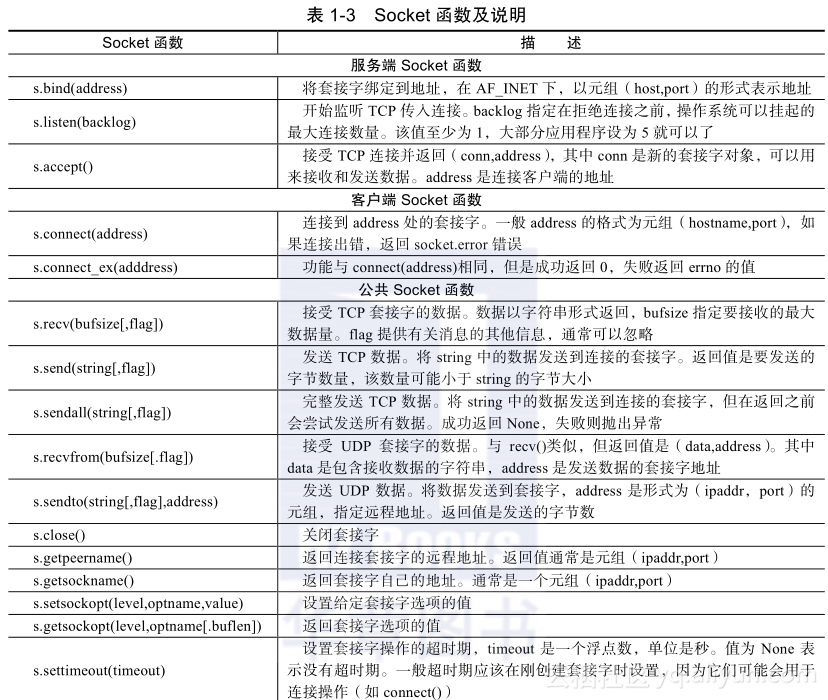

本节接下来主要介绍Python中TCP和UDP两种网络类型的编程流程。
1.5.1 TCP编程
网络编程一般包括两部分:服务端和客户端。TCP是一种面向连接的通信方式,主动发起连接的叫客户端,被动响应连接的叫服务端。首先说一下服务端,创建和运行TCP服务端一般需要五个步骤:
1)创建Socket,绑定Socket到本地IP与端口。
2)开始监听连接。
3)进入循环,不断接收客户端的连接请求。
4)接收传来的数据,并发送给对方数据。
5)传输完毕后,关闭Socket。
下面通过一个例子演示创建TCP服务端的过程,程序如下:
接着编写客户端,与服务端进行交互,TCP客户端的创建和运行需要三个步骤:
1)创建Socket,连接远端地址。
2)连接后发送数据和接收数据。
3)传输完毕后,关闭Socket。
程序如下:
# coding:utf-8
import socket
# 初始化Socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 连接目标的IP和端口
s.connect(('127.0.0.1', 9999))
# 接收消息
print('-->>'+s.recv(1024).decode('utf-8'))
# 发送消息
s.send(b'Hello,I am a client')
print('-->>'+s.recv(1024).decode('utf-8'))
s.send(b'exit')
# 关闭Socket
s.close()
最后看一下运行结果,先启动服务端,再启动客户端。服务端打印的信息如下:
Waiting for connection...
Accept new connection from 127.0.0.1:20164...
-->>Hello,I am a client!
Connection from 127.0.0.1:20164 closed.
客户端输出信息如下:
-->>Hello,I am server!
-->>Loop_Msg: Hello,I am a client!
以上完成了TCP客户端与服务端的交互流程,用TCP协议进行Socket编程在Python中十分简单。对于客户端,要主动连接服务器的IP和指定端口;对于服务器,要首先监听指定端口,然后,对每一个新的连接,创建一个线程或进程来处理。通常,服务器程序会无限运行下去。
1.5.2 UDP编程
TCP通信需要一个建立可靠连接的过程,而且通信双方以流的形式发送数据。相对于TCP,UDP则是面向无连接的协议。使用UDP协议时,不需要建立连接,只需要知道对方的IP地址和端口号,就可以直接发数据包,但是不关心是否能到达目的端。虽然用UDP传输数据不可靠,但是由于它没有建立连接的过程,速度比TCP快得多,对于不要求可靠到达的数据,就可以使用UDP协议。
使用UDP协议,和TCP一样,也有服务端和客户端之分。UDP编程相对于TCP编程比较简单,服务端创建和运行只需要三个步骤:
1)创建Socket,绑定指定的IP和端口。
2)直接发送数据和接收数据。
3)关闭Socket。
示例程序如下:
# coding:utf-8
import socket
# 创建Socket,绑定指定的IP和端口
# SOCK_DGRAM指定了这个Socket的类型是UDP,绑定端口和TCP示例一样。
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
s.bind(('127.0.0.1', 9999))
print('Bind UDP on 9999...')
while True:
# 直接发送数据和接收数据
data, addr = s.recvfrom(1024)
print('Received from %s:%s.' % addr)
s.sendto(b'Hello, %s!' % data, addr)
客户端的创建和运行更加简单,创建Socket,直接可以与服务端进行数据交换,示例如下:
# coding:utf-8
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
for data in [b'Hello', b'World']:
# 发送数据:
s.sendto(data, ('127.0.0.1', 9999))
# 接收数据:
print(s.recv(1024).decode('utf-8'))
s.close()
以上就是UDP服务端和客户端数据交互的流程,UDP的使用与TCP类似,但是不需要建立连接。此外,服务器绑定UDP端口和TCP端口互不冲突,即UDP的9999端口与TCP的9999端口可以各自绑定。