2.10 案例研究:BGP内存的使用评估
BGP设计与实现
本案例研究的目的是为了演示不同组件之间的相互依赖性,这些组件都使用了BGP内存,这里特别关心BGP Router进程。本案例研究也建立了一个简单的方法,即基于一定数量的前缀和路径来评估所需要的BGP内存。这里使用了实验手段,来确定BGP组件与它们的内存耗费之间的种种关系。BGP消耗的总体内存是BGP网络(前缀)、BGP路径、BGP路径属性、IP NDB、IP RDB,以及IP CEF所使用的内存总和。最后将提供一份Cisco的Internet路由器上BGP内存使用的合理评估。
2.10.1 方法
为了模拟BGP内存的使用,将使用Cisco 12012路由器和4个网络仿真工具。GSR是被测试的设备,它运行Cisco IOS版本12.0(15)S1。网络仿真工具能够模拟出BGP和OSPF会话。图2-7显示了测试拓扑图。
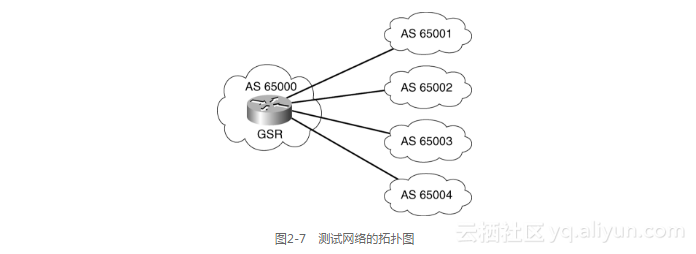
GSR运行了OSPF和BGP。它的GRP处理板有128MB的DRAM内存,例2-13和例2-14显示了它的版本和相关的配置。
例2-13 命令show version的输出

例2-14 GSR的运行配置
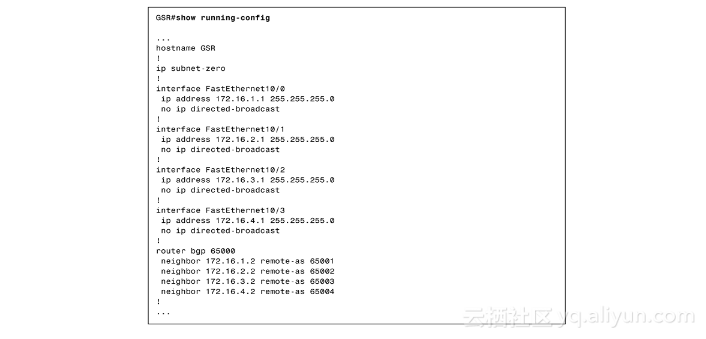
每个测试工具被分配了不同的AS号,从65001到65004。所有被通告的前缀都有24位的掩码(/24),并含2~6个C类网络。所有其他的BGP配置都用默认设置。
注意:
在这个例子中,没有考虑路由映射、过滤列表、团体,以及路由反射等参数。例如,如果使用了入站温和重配置功能,那么就会消耗更多的内存。
为了在测试结果中提供内存使用的合理分布与前缀数量,模拟了11对BGP网络和路径组合,这显示在表2-4中。
表2-4 测试网络和路径的组合

对于每一个网络/路径对,这里收集了对BGP RIB、IP RIB和IP CEF结构的内存分配,也收集了反映BGP Router进程、IP CEF表、BGP表和IP表中的内存使用情况。对于BGP RIB来说,这些数据反映了BGP网络、BGP路径和路径属性的内存使用情况。对于IP RIB而言,这些数据是有关NDB和RDB的数据。IP CEF的内存数据既包括了FIB结构,也包括了用来存储BGP网络的mtrie。
对于每一个组件,根据相关性,我们对照BGP网络或路径来标出内存使用情况。这里运用了线性回归来获得那个组件的评估模型。线性模型可以表示成下面的形式:
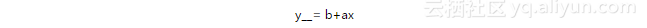
其中,y表示被评估的某种组件的内存使用量,x表示网络表项的数量或路径表项的数量,b表示直线的截距(当x为0时y的值),或者说是本案例中的评估偏差,a表示这条线的斜率,它标志了内存消耗对前缀和路径变化的敏感性。对于每一个线性模型来说,回归计算的结果就是a和b的值。
每个回归相对于实际数据的精确度可以通过R2,即判定系数(coefficient of determination)来表示。从数学上讲,R2是平方和的比率,因为回归是在所有平方的总和之上的。它也被称为相关系数(correlation coefficient)的平方。R2的值在0~1之间,0表示最差的相关性或没有相关性,而1表示最好的相关性或者完美符合。
2.10.2 评估公式
根据前面章节讲述的方法,可以做出多个评估公式。下面的章节将从BGP被启用前内存的使用开始讲述。
1.在BGP被启用前的空余内存
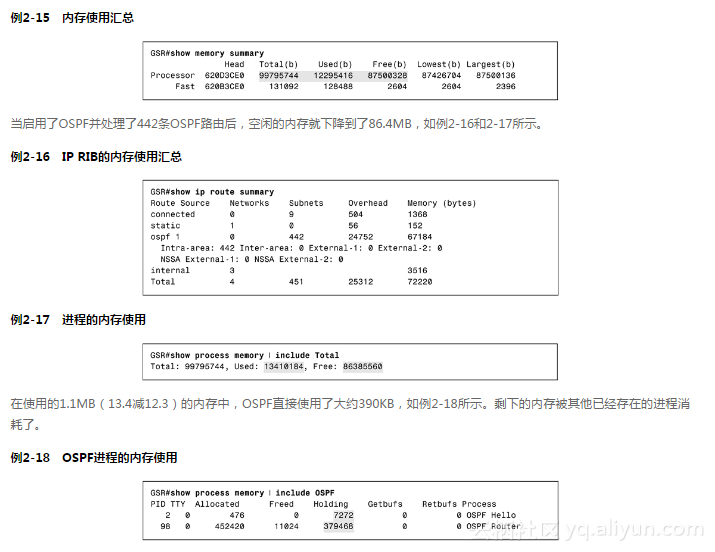
在系统启动后但还没有配置任何路由选择协议前,GRP处理板上128MB的DRAM内存里可自由分配的内存是99.8MB,如例2-15所示。这时的内存主要是由IOS映像文件扩展到DRAM内存中所消耗的。这时,其他的进程使用了12.3MB,而剩下87.5MB的空余内存。
2.BGP网络的内存使用
图2-8显示了在BGP RIB中,用来存储所有BGP网络表项的内存的使用情况。这里根据网络表项(以Actual显示的)的数量绘制了内存使用情况,这些是实际的测量值。通过图中呈现的一条回归线可以直观地比较实际使用的内存量和模型计算出的内存量。这里的回归线就是:
内存(以字节计)= 214196.9 + 114.9网络表项
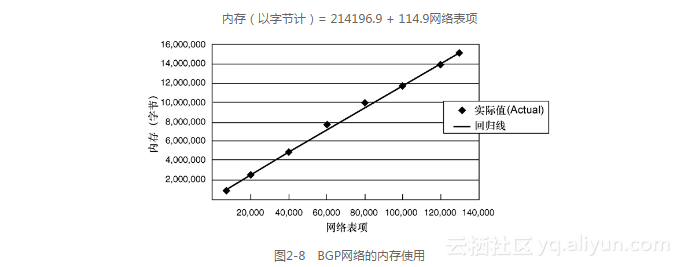
其中,R2为0.996。在这个例子中,网络表项与路径表项之间的内存使用的相关性是可忽略的(没有显示这个数据;从现在开始,仅仅提及比较重要的回归)。
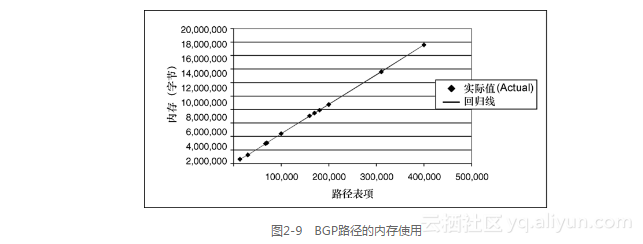
3.BGP路径的内存使用
图2-9显示了在BGP RIB中,用来存储所有BGP路径属性的内存的使用情况。它的回归线是:
内存(以字节计)= −20726.5+44.0路径表项
其中,R2为1.000。
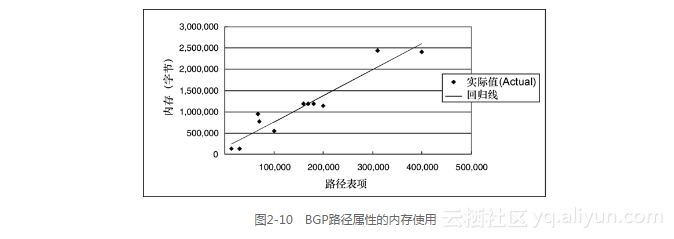
4.BGP路径属性的内存使用
图2-10显示了在BGP RIB中,用来存储所有BGP路径属性的内存的使用情况。它的回归线是:
内存(以字节计)= 146792.2+6.1路径表项
其中,R2为0.908。
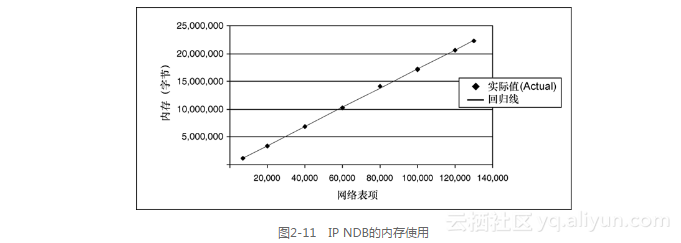
5.IP NDB的内存使用
图2-11显示了NDB使用的内存情况。它的回归线是:
内存(以字节计)= 47765.9+172.5网络表项
其中,R2为1.000。
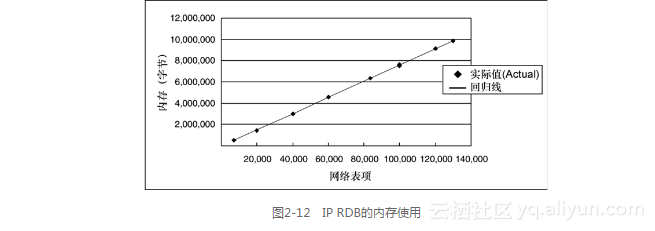
6.IP RDB的内存使用
图2-12显示了RDB使用的内存情况。它的回归线是:
内存(以字节计)=21148.5+76.1网络表项
其中,R2为0.996。
7.IP CEF的内存使用
图2-13显示了IP CEF使用的内存情况。它的回归线是:
内存(以字节计)= 32469.1+151.9网络表项
其中,R2为0.999。
8.BGP的内存使用总计
BGP Router进程使用的内存总量是所有组件使用的内存总和。利用前面讲述的方程式,你可以评估出每一个组件使用的内存。把所有6个组件使用的内存加在一起,你就可以获得一份总体内存的使用评估。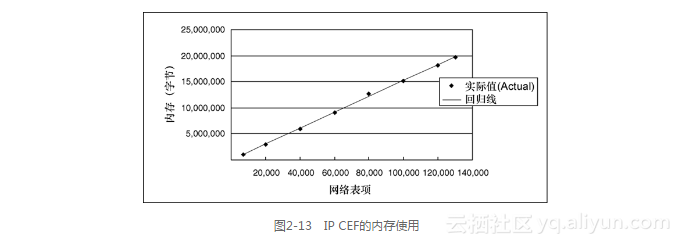
举一个例子,假设BGP RIB有103 213条网络表项和561 072条路径表项。那么,表2-5就显示了对每一个组件内存使用的估算。因而,BGP Router进程总计使用的内存就是所有这些内存使用估算的总和——81.5MB。
2.10.3 分析
Cisco IOS软件保持了对3种与BGP有关的结构的跟踪:BGP RIB、IP RIB和IP CEF。BGP RIB用来保存通过BGP接收到的前缀,以及与这些前缀相关联的属性,例如团体属性、AS_PATH属性等等。一个BGP宣告者可以有多个BGP会话,这些会话按照iBGP和eBGP对等体来分,因此每条前缀有可能存在多条路径。每一条惟一的前缀被保存在BGP的网络表中,而同一条前缀的所有路径被作为BGP路径表项而保存。每一条前缀(或网络)和路径表项消耗的内存数量根据IOS版本的不同而不同。
命令show ip bgp summary的输出可以提供某个BGP组件的内存使用情况。在Cisco IOS软件版本12.0(15)S1中,每一条惟一的前缀使用129个字节的内存,而每增加一条路径将再消耗36个字节的内存。例如,如果BGP RIB包含100条前缀和200条路径,那么这些表项总计消耗的内存是(100 × 129)+(100 × 36)= 16,500字节。
命令的输出也包含了路径属性、团体属性、缓存等的内存使用情况,这依赖于BGP的配置和从对等体接收到的前缀。注意,这些数量少于所估算的数量(如表2-6所示)。这是因为命令show ip bgp summary输出的内存数量不包含杂项开销。本案例研究的结果是直接从命令show memory中得出的,它包括了所有的内存使用。
如果在路由器本地启用了BGP入站温和重配置功能,那么所有被拒绝的路由依然会被当作仅仅接收(receive-only)的路由而保留,这将导致BGP RIB使用更多的内存。由于仅仅接收的路由被排除在最佳路径选择之外,因而它们不会影响IP RIB和IP CEF的内存使用。从IOS软件版本12.0开始,路由刷新特性就可用了,当入站策略发生变化时,路由器能够动态地更新它的对等体,因此,不再需要入站温和重配置功能了。路由刷新特性在所支持的软件版本中是自动生效的,为了验证是否支持这个特性,可以执行show ip bgp neighbor命令。
这个测试没有考虑缓存路由映射和过滤列表所使用的内存。对于一个典型的拥有10万条路由和6条不同的BGP路径的Internet路由器来说,这部分内存的使用大约接近2MB,而BGP总计使用大约80MB的内存。BGP Scanner、BGP I/O以及BGP Router进程的维护所需要的内存总共大约在50KB以下。
在这个案例研究中,只为BGP估算了静态的内存使用。这里的静态内存指当BGP处于稳定状态时所使用的内存——也就是说,前缀在网络已经收敛后的情形。然后,BGP在收敛期间可能会使用额外的内存。这种类型的内存称为瞬时内存使用(transient memory use)。瞬时内存的大小难以跟踪,而且它会根据一些因素而变化,例如发送和接收更新的方式,BGP Router进程所处的状态以及IOS版本等。比如,对等体组允许复制一份从对等体组引导路由器(peer group leader)来的路由更新,并把它发送给该组的其他成员,因此维持这些消息只需要较少的内存。更新打包(update packing)是另一个减少发送给对等体更新数据包数量的方法。这些方法和其他一些性能调整技巧将在第3章中详细阐述。
根据IOS软件的版本、BGP和路由器状态,BGP Router进程处于以下3种状态之一,越是后面的状态,功能越强,使用的内存越多:
只读(read-only)——BGP从对等体那儿仅仅接受更新。它不计算最佳路径,也不把这些路由安装到路由选择表中。这就减少了瞬时内存的使用。在路由器初始化的启动阶段,BGP典型地就处于这种模式。
计算最佳路径(calculating the best path)——BGP接受更新并运行路径选择进程,这个过程通常会和一些结构的缓存处理相关,因此,会增加瞬时内存的使用。这是典型的过渡模式。
读和写(read and write)——BGP接受更新,计算最佳路径,安装这些路由到IP路由选择表中,并生成更新以发送给它的对等体。这种状态将需要更多的瞬时内存。这种状态是BGP的常规模式。
在规划容量时,最佳实践(best-practice)的指导原则是:为瞬时内存和其他因素而考虑另外增加20%的静态内存使用。需要密切观察的第二个数字是系统中可用的最大DRAM块的最小值。如果这个数字是20MB或更小,那么就需要增加更多的资源。
BGP RIB中所有的最佳网络/路径表项都会被安装到IP RIB表中,由此引起了NDB和RDB结构对内存的使用。如果一个主网络以固定长度或可变长度被划分了子网,那么在IP RIB中就会为这个主网络创建额外的表项。根据IOS版本的不同,每条表项使用1172字节的内存。子网化表项的内存使用在命令show ip route summary中被显示为internal。这个数值是命令show ip route中的表项的总数,这是在前缀被划分了子网或可变子网的情况下。在这个测试中,由于只使用了2~6个主网络,所以在IP RIB中,子网化表项的内存使用小于7KB。
另一个对IP RIB和IP CEF中BGP内存使用有重要影响的因素是BGP负载分担,这个测试中没有考虑它。默认条件下,BGP只会安装一条最佳路径到IP RIB中。如果使用了BGP多径特性,那么每条BGP前缀的多个表项就可能被安装到IP路由选择表中,从而增加了IP RIB和IP CEF的内存使用。
被安装到IP RIB中的BGP前缀还会被安装到FIB表中。给IP CEF分配的内存通常与命令show ip cef summary报告的内存使用是一致的。对于运行dCEF的线卡来说,这只是BGP使用的内存,因为线卡不维护BGP RIB或IP RIB。除了与前缀数量有关外,CEF的内存使用还与前缀长度有关。例如,如果前缀是/16,这条前缀使用的内存就是1KB,紧接着mtrie的根也使用1KB内存。如果前缀是/24,将会再使用另外的1KB。如果前缀长度大于/24,那么再使用1KB。Internet上前缀的分布通常显示9%的前缀长度为/16或更短,83%的前缀长度在/17~/24之间,还有8%的前缀长度大于/24。为了建立一个简单而不失精确性的方法,这个测试所使用的前缀的长度都是/24。