最近两周时间里,一直都在学习监控软件的开发,虽然是简版的,可是在这个过程当中,对于要开发一个监控软件的大概框架和流程还真的学习了很多东西,而且也想,这些知识实在是很难通过看文章或者是书籍能学习得到,只有自己亲自去实践过,我想才可以慢慢体会到这中间的不易吧。而通过这样一个过程,发现自己在这方面的思想枷锁也慢慢地打开,也才慢慢体会到那种乐趣吧。这里,真的是非常感谢Alex老师非常精彩的讲解。
监控软件的大概流程如下:
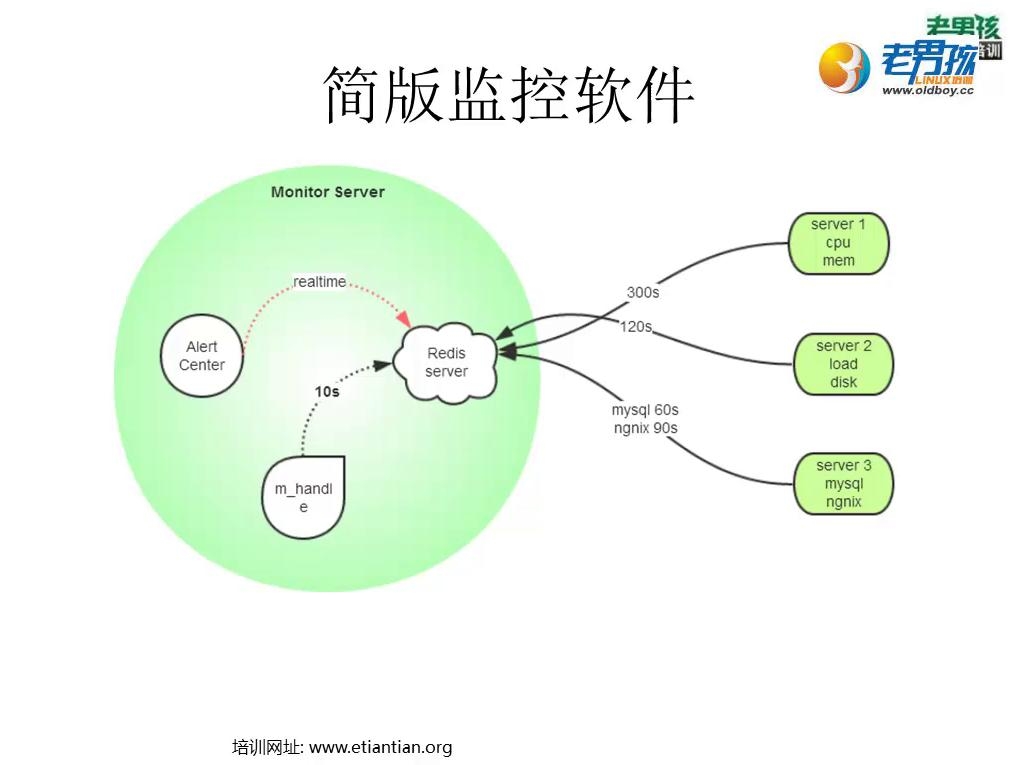 当然,实际中学习的过程中并没有去监控MySQL或者是ngnix,而只是监控Linux服务器的CPU、内存、load的各项相关指标,不过我觉得这倒没什么问题,因为思想和框架出来了,后面要监控什么,自然而然也就很轻松了,把插件写好,然后添加到监控项里面去就OK了。
当然,实际中学习的过程中并没有去监控MySQL或者是ngnix,而只是监控Linux服务器的CPU、内存、load的各项相关指标,不过我觉得这倒没什么问题,因为思想和框架出来了,后面要监控什么,自然而然也就很轻松了,把插件写好,然后添加到监控项里面去就OK了。
我刚开始看到上面的监控软件示意图时,感觉应该也不会太难的,但当我跟着一步一步去做时,才实现这中间要考虑和解决的问题实在是太多太多,总结起来,要解决的问题,或者说基本的实现流程与思想,简单的总结可以如下:
对于客户端:
1.如何获得需要监控的指标项目
例如如果我要监控的是CPU的情况,我该如何去获得CPU的相关指标信息,通过什么方式或者说什么命令,这一步实现之后,其实得到的就是一个监控CPU的插件,这个插件应该尽量独立,即不受其它程序的影响,与其它程序之间的耦合度要低,总之,这个插件的功能,就是可以得到我想要的监控指标信息。
2.如何处理获得的监控指标信息
主要是指客户端对这些监控指标信息数据的处理,这里应该涉及到的问题,获得监控的指标信息后,应该是基于一个监控项目来保存,还是要基于一台被监控的主机来保存指标信息。比如我监控了一台主机的CPU、内存、load后,我是应该把这三者分别保存为三个数据结构,还是把这三者直接保存为一个数据结构?这就要看需求了,而基于CPU、内存、load的监控频率可以调整,考虑到软件以后的扩展性,应该要把三者获得的数据分开保存,用Python开发时,就可以把这三者保存到三个不同的字典中去了。因此,从这一步来看,这里重要的是要知道监控的频率从何而来,继续看下面的内容。
3.监控项目的配置信息获取方式
比如我要监控CPU,具体我要监控CPU的什么信息,什么指标,如idle、nice等,我应该去哪里找这些配置信息?多长时间监控一次,即监控的频率是多少?有想法是可以直接在客户端上自己设置,但如果这样做的话,依然是考虑到软件的扩展问题,如果以后要监控的服务器主机很多,那不是要在每一台客户端主机上进行设置?既然是监控,那倒不如考虑在服务器端设置客户端的信息,即配置文件,然后可以由客户端直接从服务器端获取,这样当监控多台主机时,只要在服务器端进行相应的设置,客户端跑个客户端程序就可以了,集中、统一管理的思想由此而体现出来。但问题的关键是,这些配置信息,客户端怎么去服务器端取?
4.如何从服务器端获得监控项目的配置信息
如果用的是3中的方法策略,那么客户端如何从服务器端去取?这时就可以借助Redis数据库的订阅服务功能了,基于Redis数据库的特性,只要在服务器端和客户端都安装并运行了Redis数据库,问题就很好解决了。当然,这里需要获取的重要配置信息应该是:这台主机监控的项目是什么?监控频率是多少?
5.通过什么方式将获取的监控信息发送给服务器端
有了4的经验,那使用Redis的订阅服务那是最简单不过了。这时其实我们要采取的监控方式是被动监控方式,即服务器端不会主动向客户端获取监控信息,而是由客户端主动向服务器端发送监控信息,然后服务器端再根据已经设定好的监控策略来进行判断客户端主机是否出现异常,然后再实现报警功能。
对于服务器端:
服务器端要考虑的则更多了,在这里,面向对象的编程思想就显得犹为重要了,当然,监控数据的接收与整理、处理、报警也不容易。
1.用面向对象的编程思想实现不同主机监控项目的模板定制
客户端的监控配置信息都是从服务器端获得的,由于不同的客户端主机监控的项目、监控的频率都有可能不一样(这很正常,不同的服务器对于不同的性能指标要求都不一样),因此通过面向对象的编程思想,把每个监控项目的基本配置信息模板写好,基于这些模板,根据需要被监控的服务器主机的不同,定制不同的监控配置信息,然后保存到Redis数据库中,让客户端主机去取,这里对应客户端解决问题中的第3点。
2.监控数据如何接收与整理
前面其实已经说过,依然是通过Redis数据库的订阅服务功能来进行接收,如果这个方式要改变,那么在客户端主机中也应该进行相应的更改,这里对应客户端解决问题中的第5点。这里,可以单独写一个程序来跑一个进程,把接收到的数据,根据后面处理数据时的需求,再添加相关的信息来重新整合接收到的监控数据,再保存到Redis数据库中去,再由监控数据处理程序去进行处理,即handle程序,之所以要这样做,是为了要降低程序之间的耦合度,以方便以后对监控软件进行功能上的扩展。
3.监控数据如何处理
这里单独写一个程序跑一个进程,从Redis数据库中读取不同主机不同监控项目的监控信息,然后将这些监控信息与第1步定制的模板中的指标阀值进行比对(所以第一步写的内容信息不仅仅是监控项目配置信息模板,也应该还有不同指标和阀值的相关设定),如果发现有异常情况的,即将异常情况信息保存下来,写入到Redis数据库中,等待报警程序进行相关处理以实现报警功能,这样分开来做的目的依然是为了降低程序之间的耦合度。另外这里需要注意的是,监控数据的处理也应该是基于不同的监控项目的(对应客户端中的第2点),而不是基于不同的主机,因为不同的主机的不同监控项目的监控频率可以是不一样的。
4.如何进行报警
这里也应该单独写一个程序来进行报警功能的实现,从Redis数据库中读取报警信息后,如何将这些信息进行报警,是直接在屏幕输出?还是邮件?还是短信?还是电话?以及将这些信息发给哪个相关负责人?基于上面的这些不同需求,要构思的应该又不少了。
所以对于上面的一个流程的概述,可以更进一步总结如下:
客户端:读取监控配置信息-->开始监控-->获得监控数据-->发送给服务器端
服务器端:读取监控数据-->监控数据处理-->保存异常信息-->实施自动报警
知道监控软件的思想流程有何作用?
不管怎么说,监控软件的大致开发过程或者说是开发的流程与思想应该是跟上面说的类似的,只是基于不同的功能、不同的需求、不同的方式,在实际开发的过程当中又有太多细节的不一样,总的来说,流程看起来不会太难,但具体到每一个细节的实施,需要花费的精力,我想是非常非常多的,而这,应该是需要一定的经验的。但无论如何,因为知道了大概的开发流程,并且自己动手实践过,所以以后在自己需要开发相关监控软件时,根据自己的需求,再按照上面的思想流程去做,我想,从最基本的开始做起,是一定可以开发出一套适合实际生产环境的监控软件的。
为什么要学习Python自动化运维开发?
今年5月份,接手了学校600多台交换机的管理,发现对交换机的监控实在是太弱,600台交换机,上万的用户,竟只有一个只能通过屏幕界面来进行查看的监控平台,因此,更不用说自动报警功能了,迫于这种无奈,我上网找了很多相关的监控软件,要么都是收费的,要么是使用不了,要么就是操作起来非常非常复杂的,因此,很难下手。其实我的需求很简单,只是希望可以看到交换机有没有挂掉,然后如果挂掉了,可以给我打个信息或者打个电话,是这样一种轻量级的监控软件就好了。
到了今年9月,实在是无奈,只能自己去学开发,那种求人不如求己的感觉越来越强烈。
不管怎么说,在学习了这方面的知识后,发现其实要开发具有我上面所说功能的交换机功能的监控软件,在流程上面就要比前面说的那个要简单很多,所以我想,这是不难实现的。
继续Python开发的学习,在后面学习了Web开发相关的知识后,我是希望通过自己的能力可以开发一个较为完善的基于自己实际需要的交换机监控系统。
当然,以后要用Python做的事情,就真的是太多太多了。
不管如何,往后要学习的知识或者说技术,真的是太多太多,希望自己不要放弃,继续努力下去吧!