这一期做一下数据科学系列。第一篇美国首席数据科学家谈数据产品实践,如何做到数据驱动,打磨产品,精益创业。
“当你在深夜遇到系统挂了和数据损坏,有什么办法可以避免那些痛苦和头痛?”
这是DJ·Patil
在最近的CTO峰会提到的。他是RelateIQ前任产品副总裁,和美国现任首席数据科学家,Patil总结所有产生变革的经验教训和失误。他与
Ruslan Belkin,目前Salesforce工程副总裁,分享有关打造数据产品中最重要,最突出的失误和经验。
常见的错误是认为所谓“数据产品”仅指像Twitter或LinkedIn,社交图谱是一切。其实越来越多的产品都归入此类,包括硬件,可穿戴和其他任何收集和对用户有意义的数据。Belkin和Patil的所提供的建议也适用于创业公司的生态系统。
“当你想到数据产品更广泛,开始意识到即使公司的报表也算数据产品的话,你的视野就打开了。你可以开始创建流程,去了解,制造和规模化,“ 那么为什么这么少的公司谈论或强调搭建有用的数据产品?回答这个,Patil引用杜克大学著名经济学教授丹·艾瑞里的话:

诚然,这归结于搭建大规模的数据产品真的很难。在这Belkin和Patil提供了一些有见地的战术,让大家更容易并可以大胆创造新产品。这将改变我们所看到的连接世界的方式。
数据产品需要进行不同的搭建
用原型来做数据产品跟其他一样开始很容易。但上了规模,就会碰到一堆独特的挑战。你必须计划每一个地方。他们从来没有一次性或独立的产品。所以你不能像以前一样只是构建,测试,回滚和上线。
你必须一开始有非常基本的想法:数据是超级乱的,数据清理将永远是承担80%的工作。换句话说,数据是问题所在。
“如果你像LinkedIn在创业初期,他们曾对IBM 有4000种说法 – IBM,IBM研究中心,软件工程师,所有的缩写等”
我保证如果你不思考如何让数据从一开始清理,你就完蛋了。
“试图及时清理,因为以后需要几个月的时间去做它。”
面对这种困境,你应该先建立简单的产品 – 超级简单的东西,计数练习,像协同过滤器,只是零和一。所有这些事情将在大规模下执行更难。
“如果你试图建立一个像机器学习那样野心勃勃的东西,它会在你面前失败。形成管道(pipe)和保证其他的东西正确,在此基础之上一步步来。“
以一个强大的方式召回数据
其中的最好的例子也来自于LinkedIn。谁最近浏览你的个人资料。这是一种将流量导回到你网站的信息。
“这里的常见错误是,让数据导回是不错,你就想”让我们给更多些吧!但是,将数据添加到页面实际上跟得到的点击数是成反比的,你必须要找到用户的合适平衡点。“
当你添加更多的数据,你把用户放入瘫痪境地。他们不知道该怎么做。
决定什么数据暴露给人们不只是多少 – 这是关于它说什么了。Patil想到把工作推荐给人 ,比如“嘿,你应该申请这份工作,因为它符合你的技能!”很快意识到这种做法是危险的。
“我们很有可能一不小心推荐一个高级职务的人去申请实习,或加州居民应该搬到爱达荷州工作机会。当这样的东西发生了,人们就很生气,它可以很快搞砸你的品牌,你得想想那种特定功能实际上是当用户看到它的样子。这就是你要聪明
– 当它涉及到的数据产品,聪明要比傻瓜智能强很多“。
在这种情况下,聪明的解决方案是换个角度去推荐工作。如果“Bill”是他们想推荐的用户,不是直接发送推荐工作机会给Bill,而是通过他的社交关系发送短信:推荐Bill这项工作。它使用了完全相同的算法,有一点扭曲,但它处理了强硬相关性的问题。

“如果Bill从他的一个朋友听到,认为他应该接受一份工作,他仍然可以说,’这是一个垃圾”但是这是罕见的,并且该网站永远不会被指责,除此之外,我们去收集所有允许使用的数据,弄清楚这个功能怎么回事,使其变的更好。”
我们没有时间去把它做对,但我们有时间去重做
这是Belkin的最喜欢的名言,强调把事情先做,再尝试,当你有更多知识去迭代。
像LinkedIn有个人才匹配的产品。当时的想法是,一个公司发布一个职位空缺,最佳适合工作描述的人得到推荐。它已开始很棒直到他们试图去规模化和各种复杂度的出现。
“最后我们不得不复查所有的系统,直到我们能够理解功能正确结合和合理评估框架。直到我们把所有东西做对,我们才知道如何大规模搭建它“
大量的数据产品需要时间去成熟,并产生你需要的信息让他们变的更好。
“这可能很辛苦,即使苹果这样的公司有时不得不为顾客处理有争议劣质产品的数据而道歉和推荐竞争对手的应用程序”这个问题会影响公司规模和技术水平。
在LinkedIn中,“你可能认识的人”功能开始于一个工程师的电脑中python脚本。直到2008年该功能推出两年后,它才开始在平台上推动流量有效增长。
同样的事情也发生在Twitter的搜索。这是首次推出为Twitter用户的实用工具。但直到2013年中期,大家才发现这是流量增长的主驱动力。
千万不要按固定的时间表去推出一个复杂的数据产品。
从哪里开始
很多人选择通过建模开始。有些从功能的发现或工程中开始。还有人通过搭建基础设施去做规模化服务开始。但Belkin认为数据产品只有一个正确的答案和出发点:理解如何评估性能和搭建评估工具。
“迄今每一个公司聊到了最后都没有一个例外, 数据质量差,尤其是监控数据,”他说,“要不就是不完整的数据,缺失监控数据,或者重复监控数据”。
为了解决这个问题,必须投入大量的时间和精力监测数据质量。你需要监控网站的响应时间。你需要把数据质量的bug放在第一优先级。不要害怕因为发现数据质量问题失败一个部署。但有一件事你不能做:
“如果你有数据质量问题,不要提交到苹果应用商店”他说。 “你必须确保你有完全正确的工具,你所有正在跟踪的事件,以及通过模式注册就可以集成到开发过程中。”
为了加强这些经验教训,Belkin快速报表查看来开始他的工作会议。他亲自一天看20多次,发现它用来讨论表面问题和潜力问题要积极快速得多。在成为灾难前得到更快的解决。
产品上线前检查清单
在你推出的数据产品给用户前,你应该通过这个清单来检验:
1 .产品要能跑通
早年Belkin曾在网景,并记住CEO Jim Barksdale – “你看,如果你每天弄错运送包裹的1%,在100天内,很大的客户群就不爽了”的说法,你需要考虑的用户看到坏的结果的可能性?
把它放到高科技消费产品方面:“如果把黄色信息显示在他们的新闻源是否能接受,每三个月?半年?九个月?你必须搞清楚什么是可以接受的水平。”
如何应对尴尬的内容和推荐?这是一个需要你注意的问题。不管他们做什么,总有弄砸的时刻。你会做什么?是回滚该版本?你会更改线上数据库去尝试正确的东西?唬弄东西修改索引?在系统运行时提升一个等级?所有这一切通常是一个坏主意。你应该提前预料到这种可能性,并制定解决方案就可以立即部署。“
2. 它必须为用户服务
你必须把用户参考的东西显示在他面前。他们需要理解所看到的东西是具体的信息 – 或者是因为他们关注一定的用户,或采取了一定的行为,甚至可能是因为他们没有采取行动。
重要的是,你不能把跟用户之前无关经验的品牌和产品展现出来。没有人愿意看到随机出现的东西。乱入将失去用户。
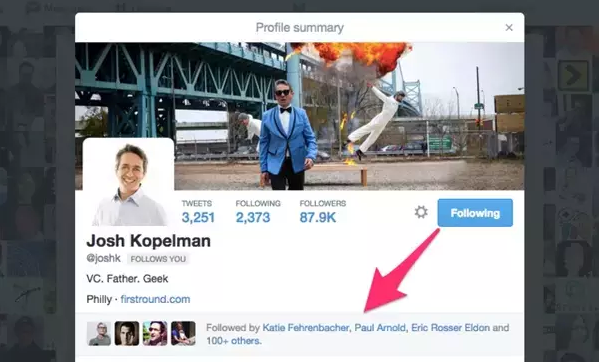
例如,一个Twitter的个人资料放在谁关注的人,在你已经知道的情况下会更可能关注他们。这就说到下一个。
3.让用户感到安全
“这就是我所说的泰迪熊原则,问问自己,用户会认为你的产品是很烂的或有害的吗?它不是必须要那样,但这些不好用户体验可引起长期损坏你的平台“。
首先,你必须确保不会个人身份信息泄漏。这可不是闹着玩的,总是有一定的风险,这可能因产品设计或实现一个缺陷而发生。你可能被黑客攻击,某些数据没有被加密,这是非常严重的。你要力所能及不仅防止这种情况发生,而且传达良好的设计,不让这种事情发生的良好用户体验。用户会用最小的蛛丝马迹以确定他们是否应该信任一个产品。
4.用户可以自己掌控
这就是你当前用户设置 – 特别是当它们涉及到隐私 – 是非常重要的。你需要思考要做到不强势的最好办法,让他们去清楚选择,使得用户有权决定与谁以及何时分享。这通常决定用户是否能回来访问。
5.有在美国以外的用户
很多人没有意识到大部分用户生活在美国外。 “根据经验,多达35种语言跟你公司相关。通常,数据在不同的语言中选择更有限。许多用户是多语种。如果你没有额外努力和计划,你可能无法提供同等质量的服务“
即使你在一个小的创业公司目前缺少资源去思考国际化,你也需要打下基础去解决这些问题。你不能想象有一个完全英语的庞大产品,然后突然决定推广到在35+语言。如果你有全球抱负,你必须在成熟之前就要考虑开始分层。
如何组织你的团队
经常被问这个问题:当你想建立和迭代多个产品的时候,如何组织你的产品和工程团队?什么是团队的合理结构?
“这带来一个很老的争论:你应该去垂直或水平扩张?哪个是正确的?
“没有一个通用的标准答案,但有对于你在公司阶段的正确答案,它矩阵的形式下图所示”。
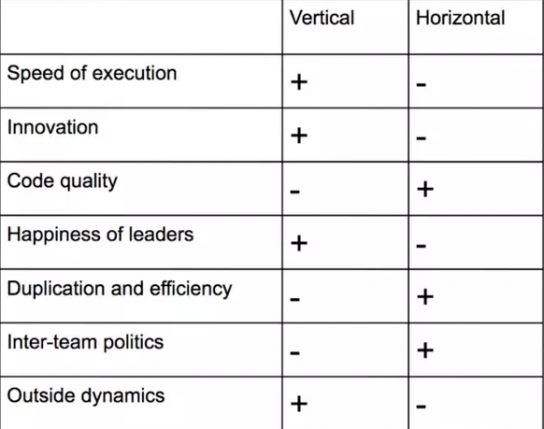
“评估需要在一些指标中做什么 – 执行,创新,代码质量,用户体验的重要性?跨团队工作需要什么去平衡构建和扩展的速度?”
一般来说,垂直整合的团队,当涉及到执行或创新时以速度取胜。大家与外部关系更融洽因为团队跟业务目标保持一致。
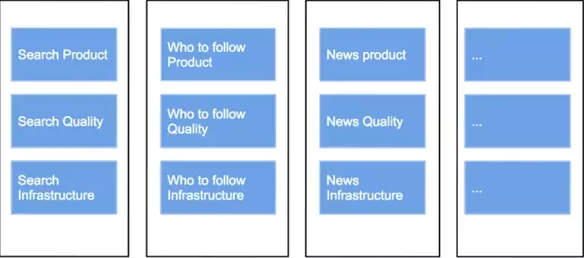
水平团队队通常有更高质量的产出。他们更高效,在内部动态控制上比较上更好。
真正核心是要保持实验和迭代,不只是产品,而且是你如何打造他们。不会一下子解决所有的问题,而新的数据可以引导你后面的过程。不要指望指哪打哪 – 尤其是不要指望你的用户和公司能在同样轻松的水平上一起成长。
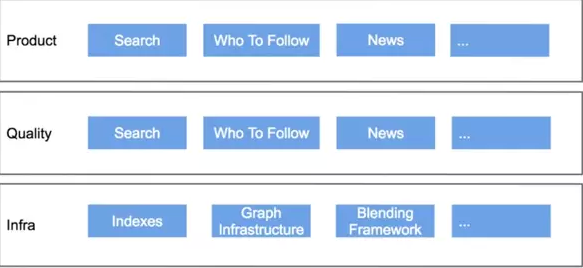
“有个搭建数据产品的比喻,这像爬山。许多人在你的前面,很多人在你后面。还有一些路径没有走过,但如果你保持你的眼睛看着顶峰并采取小的步调,你一定能到达那里!“
作者:董飞
来源:51CTO