![]()
前言
这篇文章本来不打算写的,实话说楼主对前端模板的认识还处在非常初级的阶段,但是为了整个 源码解读系列 的完整性,在深入 Underscore
_.template
方法源码后,觉得还是有必要记下此文,为了自己备忘也好,为了还没用上前端模板引擎的同学的入门也好。(熟悉模板引擎的可以帮楼主看看文中有没有
BUG ..)
后端 MVC
说起模板渲染,楼主首先接触的其实并不是前端模板引擎,而是后端。后端 MVC 模式中,一般从 Model 层中读取数据,然后将数据传到
View 层渲染(渲染成 HTML 文件),而 View 层,一般都会用到模板引擎,比如楼主项目中用到的 PHP 的 smarty
模板引擎。随便上段代码感受一下。
- <div>
- <ul class="well nav nav-list" style="height:95%;">
- {{foreach from=$pageArray.result item=leftMenu key=key name=leftMenu}}
- <li class="nav-header">{{$key}}</li>
- {{foreach from=$leftMenu key=key2 item=item2}}
- <li><a target="main" href='{{$item2}}'>{{$key2}}</a></li>
- {{/foreach}}
- {{/foreach}}
- </ul>
- </div>
传入 View 层的其实就是个叫做 $pageArray 的 JSON 数据。而 MVC 模式也是非常容易理解,推荐看下阮一峰老师的 谈谈MVC模式,然后再看看下面这张图。
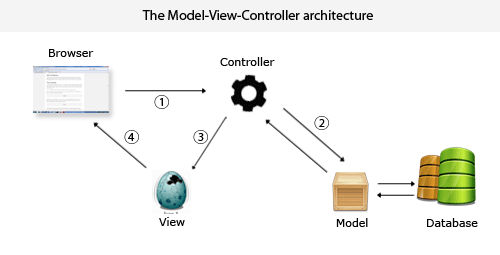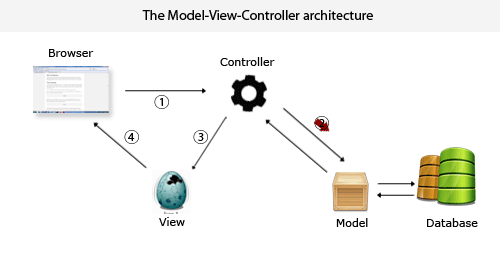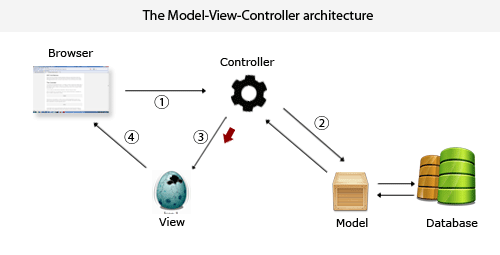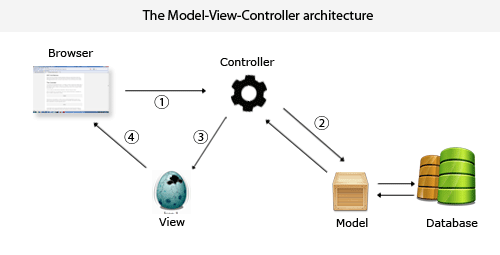
以前的 WEB 项目大多会采用这种后台 MVC 模式,这样做有利于 SEO,并且与前端请求接口的方式相比,少了个 HTTP
请求,理论上加载速度可能会稍微快些。但是缺点也非常明显,前端写完静态页面,要让后台去「套模板」,每次前端稍有改动,后台对应的模板页面同时也需要改动,非常麻烦。页面中如果有复杂的
JS,前端写还是后端写?前端写的话,没有大量的数据,调试不方便,后端写的话... 所以楼主看到的 PHPer 通常都会 JS。
前端模板
AJAX 的出现使得前后端分离成为可能。后端专注于业务逻辑,给前端提供接口,而前端通过 AJAX 的方式向后端请求数据,然后动态渲染页面。
我们假设接口数据如下:
- [{name: "apple"}, {name: "orange"}, {name: "peach"}]
假设渲染后的页面如下:
- <div>
- <ul class="list">
- <li>apple</li>
- <li>orange</li>
- <li class="last-item">peach</li>
- </ul>
- </div>
前端模板引擎出现之前,我们一般会这么做:
- <div></div>
- <script>
- // 假设接口数据
- var data = [{name: "apple"}, {name: "orange"}, {name: "peach"}];
- var str = "";
- str += '<ul class="list">';
- for (var i = 0, len = data.length; i < len; i++) {
- if (i !== len - 1)
- str += "<li>" + data[i].name + "</li>";
- else
- str += '<li class="last-item">' + data[i].name + "</li>";
- }
- str += "</ul>";
- document.querySelector("div").innerHTML = str;
- </script>
其实楼主个人也经常这么干,看上去简单方便,但是这样做显然有缺点,将 HTML 代码(View 层)和 JS 代码(Controller
层)混杂在了一起,UI 与逻辑代码混杂在一起,阅读起来会非常吃力。一旦业务复杂起来,或者多人维护的情况下,几乎会失控。而且如果需要拼接的
HTML 代码里有很多引号的话(比如有大量的 href 属性,src 属性),那么就非常容易出错了(这样干过的应该深有体会)。
这个时候,前端模板引擎出现了,Underscore 的 _.template 可能是最简单的前端模板引擎了(可能还上升不到引擎的高度,或者说就是个前端模板函数)。我们先不谈 _.template 的实现,将以上的代码用其改写。
- <div></div>
- <script src="//cdn.bootcss.com/underscore.js/1.8.3/underscore.js"></script>
- <script type="text/template" id="tpl">
- <ul class="list">
- <%_.each(obj, function(e, i, a){%>
- <% if (i === a.length - 1) %>
- <li class="last-item"><%=e.name%></li>
- <% else %>
- <li><%=e.name%></li>
- <%})%>
- </ul>
- </script>
- <script>
- // 模拟数据
- var data = [{name: "apple"}, {name: "orange"}, {name: "peach"}];
- var compiled = _.template(document.getElementById("tpl").innerHTML);
- var str = compiled(data);
- document.querySelector("div").innerHTML = str;
- </script>
这样一来,如果前端需要改 HTML 代码,只需要改模板即可。这样做的优点很明显,前端 UI 和逻辑代码不再混杂,阅读体验良好,改动起来也方便了许多。
前后端分离最大的缺点可能就是 SEO 无力了,毕竟爬虫只会抓取 HTML 代码,不会去渲染 JS。(PS:现在的 Google 爬虫已经可以抓取 AJAX 了 Making AJAX applications crawlable,具体效果未知)
Node 中间层
单纯的后端模板引擎(后端 MVC)以及前端模板引擎方式都有一定的局限性,Node 的出现让我们有了第三种选择,让 Node 作为中间层。
具体如何操作?简单地说就是让一门后台语言(比如 Java?PHP?)单纯提供渲染页面所需要的接口,Node
中间层用模板引擎来渲染页面,使得页面直出。这样一来,后台提供的接口,不仅 Web 端可以使用,APP,浏览器也可以调用,同时页面 Node
直出也不会影响 SEO,并且前后端也分离,不失为一种比较完美的方案。
总结
本文简单介绍了模板引擎在前后端的使用,下文我们回到 Underscore,重点分析下 _.template 的使用方式以及源码原理。
作者:韩子迟
来源:51CTO