自从有了网络便有了网络故障,网络故障的最大体现是丢包。如何对丢包进行诊断一直是一个令工程师头疼的问题,可关注丢包原因分析的人却非常的少。
现实
目前对于网络中出现丢包的传统处理步骤如下:
- 首先,确定丢包的设备。
- 然后,确定报文在该设备的处理流程。
- 最后,一一核对对应处理流程的转发表项(从软件表项到硬件表项)。
也许你会觉得一一核对转发流程表项太慢太麻烦,熟悉芯片的处理流程和功能之后你会找到如下一种处理方式:
- 首先,还是要确定丢包的设备。
- 然后,利用芯片提供的一些diagnosis功能进行确认,例如Broadcom的Flexible Counter,Mediatek的drop statitics等。
- 最后,根据硬件的丢包原因去确认丢包的真实原因。
虽然看起来步骤很明确,但是执行这些步骤需要对其中的流程以及机制了解的非常清楚,才能准确的诊断出丢包的原因。目前各个厂商对于丢包的诊断没有更进一步的手段和方案。
为什么会这样
是什么导致了网络诊断的手段在长时间都没有什么实质性的发展呢?主要是因为以下几个方面:
NOS本身的封闭性
- NOS厂商不愿暴露更多的细节给客户
- NOS以前都是一些专用的系统,无法提供像服务器上一些便捷的手段如tcpdump
- NOS架构通常都是mips/ppc架构,其计算能力无法与x86相比
芯片厂商提供的diagnosis具有相当的局限性。
- Flexible counter提供一个基于丢包原因的统计,可以基于端口统计多个丢包原因的报文个数。但是如果你想知道具体的丢包原因需要调整reason bitmap,需要对照手册进行调整bitmap。
- Drop statics提供了端口丢包的统计,同时提供了丢包的reason status bitmap(即发生的丢包原因)。但是可惜的这个reason status bitmap是全局的,不是基于端口的,存在一定的干扰性。
理想
想象一下当你发现网络不通的时候,你打开一个应用程序,这个程序告诉你,你的某个报文在网络中的某一台设备的某个口上因为某种原因丢弃了,然后你核对对应配置,发现配置被人修改了,然后修改配置后就通了。前后用不上几分钟就能解决问题。相比传统的两种方式,是不是要简便的多了?
为什么这么做
看到这里人们不禁要问了,为什么传统的网络厂商都没有这么做,应该是没有办法做到这样的吧?
而今是一个开放网络操作系统盛行的时代,随之一起而来的是白盒交换机,白盒交换机的控制面CPU不再是局限在传统的mips/ppc的架构,支持x86、ARM的有,而交换机服务器化的趋势也在酝酿,可以预计将来x86的交换机将会大行其道。
总的来看这个时代有两个重要的趋势:
- 开放性,用户将会越来越注重系统的开发以及开发性。
- x86释放了强大的计算能力,如何利用?
诊断与分析的难度和开放网络的趋势使得开发便利的诊断分析成为了一种必要,同时这也是一个机会。
怎么做
理想是一步步实现的,要实现这个理想需按如下几步走:
- 能够在控制台上通过show命令看到最近一段时间内的丢包的基本信息,并能够将这些基本信息导出。
- 在控制台上通过show命令看到最近一段时间内丢包的详细信息,并支持导出的基本信息的解析(wireshark插件)。
- 部署应用程序收集并按照规则统计丢包的信息。
一小步
对于丢包我们首先想到的是用户关注是哪个端口在发生丢包,其丢包原因是什么,因此对show命令的内容进行了如下的定义。

在设备上缓存这些丢包的case,并更新其最后发现的时间。
接下来就是如何获取这些丢包的信息,针对数据中心场景下20多种丢包原因进行分析,首先将其分为两类:
- 情况一:丢包,cpu可以获取原始报文的
- 情况二:丢包,cpu无法获取原始报文的
情况一
通常转发流水线中的大部分的丢包都可以获取到其丢弃的原始报文,对应的有:
- 报文携带的VLAN未创建
- 端口不在对应的VLAN中
- 路由查找失败
- l3 mtu检查失败
- stp 状态
- 其他等
对于这些的丢包情况,可以从芯片获取其原始的报文进行分析然后归类统计。
情况二
在整个转发流水线中也存在部分的丢包是无法提供原始报文的,对应的有:
- 超过buffer水线丢包
- 解析错误丢包
- 包校验错误丢包
- ingress mtu丢包(看mtu检查实现的方式而定)
对于这些丢包情况,可以从芯片的状态信息中获取对应的状态,然后进行归类统计。
同时为了支持将信息导出以为后续的分析提供支持,定义了agent导出丢包信息的格式,如下:
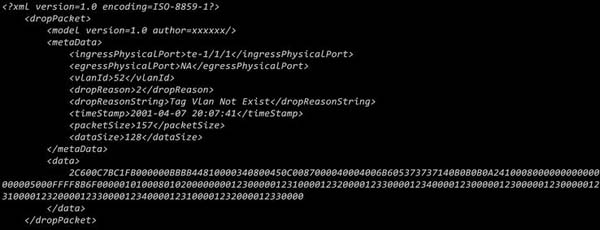
上述结构中包含了截断的前128字节的报文(如果能有原始报文),这里主要是提供给应用程序分析使用。
进一步
完成第一步之后,对于部分场景依然只能得到一个模糊的丢包的原因,只能对应上直接原因,对于找到根本原因还差一步,例如l3 lookup miss,如果无法知道报文的目的口ip,那么就无法继续分析下去,因此,用户查看对应的报文的详细信息的需要在此时变的非常重要。
同样我们需要分析报文信息哪些在这种场景下对用户是必要的,分析的结果如下:
- 二层头信息,smac、dmac、etype、length。
- 802.1q tag信息,tpid、VLAN id。
- 三层头信息,sip、dip、tos、ip length、ttl、ip protocol。
- arp头信息,smac、tmac、sip、tip、op_code。
- 四层头信息,source port、dest port。
于是在设备的缓存的丢包case中不仅保存了丢包的metadata信息,还保存了该case对应最近一个丢包的报文的解析结果。在cli上就可以通过命令将对应的信息以以下格式展示出来。

以上给出了三个示例,其中两个是可以获取到原始的丢弃的报文信息的,另一个是无法获取的。
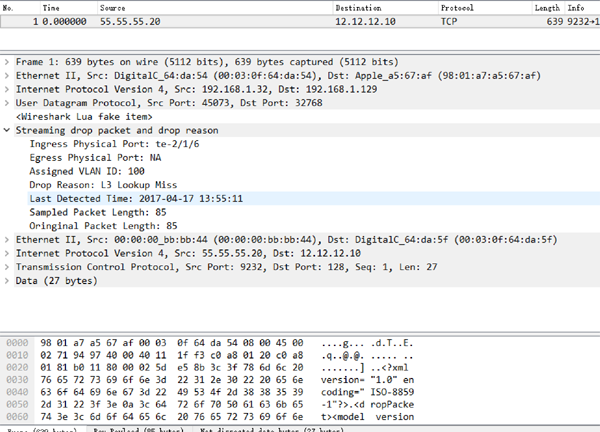
同样对于导出的信息,也需要支持解析,通过wireshark的lua插件进行展示,展示的结果如下所示。
一大步
将全网的丢包信息全部汇集到一个collector上进行统计分析,然后提供以下方式的统计显示,并可尽量还原其对应的流量大小。
- 基于物理设备统计。
- 基于源目的ip的统计。
- 基于源目的端口的统计。
- 基于丢包原因的统计。
通过这些统计的方式可以发现网络中存在的危险和配置问题(like kill all possible warning in coding),整个网络尽在掌握。
拥有了这个网络诊断分析功能之后,我们只需要简单的两步就可以确定丢包的原因:
- show sdrop查看丢包的基本信息。
- 如果第一步还是没有提供足够的信息,那么show sdrop detail中的包含的报文的相关信息将会准确提示其原因。
云启科技的ConnetOS已经完成了前面的两阶段,第三阶段正在规划中,wireshark插件已经开放到github,可前往了解更多。
作者:陈虎
来源:51CTO