我们在进行大数据开发过程中,会遇到各种问题,本文将定期收集整理一些在使用阿里云数加 MaxCompute SQL 过程中遇到的常见问题,供大家参考~
Q. 用 between …… and……报错,如图所示:
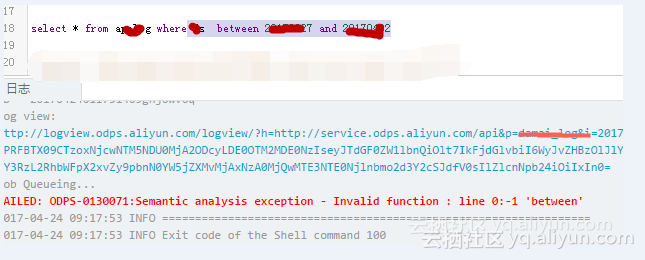
A. MaxCompute SQL 的 where 子句不支持 between 条件查询 。
更多的 SQL 语法可参见:https://help.aliyun.com/document_detail/48950.html 。
Q. 一个 sql 里 join 一个百万的小表 6 次,这个小表的数据会在内存里做缓存吗?还是会被全表扫描 6 次?
A. 当一个大表和一个或多个小表做 join 时,可以使用 mapjoin ,在小数据量情况下,SQL 会将用户指定的小表全部加载到执行 join 操作的程序的内存中,从而加快 join 的执行速度 。详情请参见 SELECT 操作 中的 mapjoin 部分的内容 。
Q. 通过 SQL 语句创建 MaxCompute 表时,怎么设置“中文名”?如下图所示:
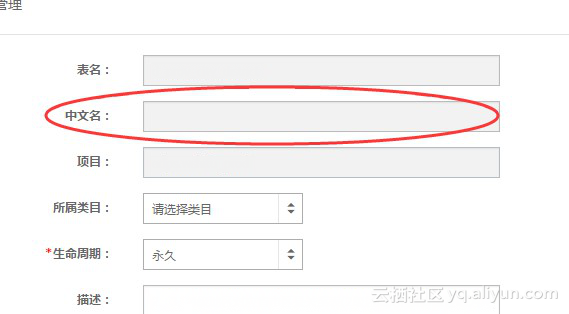
A. 这里的中文名是在数据管理模块中为了方便管理而设置的,MaxCompute 表本身没有这个属性, 包括所属类目等,都是在数据治理中用到 。
Q. MaxCompute 存储过程中支持类似于 oracle 的 EXECUTE IMMEDIATE + sql 语句 这样的语法吗?也就是说可以自己拼凑一个动态的 sql,然后让它执行吗?
A. 不支持 。
时间: 2024-09-15 18:39:29