1 系列目录
2 SPI扩展机制
站在一个框架作者的角度来说,定义一个接口,自己默认给出几个接口的实现类,同时允许框架的使用者也能够自定义接口的实现。现在一个简单的问题就是:如何优雅的根据一个接口来获取该接口的所有实现类呢?
这就需要引出java的SPI机制了
2.1 SPI介绍与demo
这些内容就不再多说了,网上搜一下,一大堆,具体可以参考这篇博客Java SPI机制简介;
我这里给出一个简单的demo:
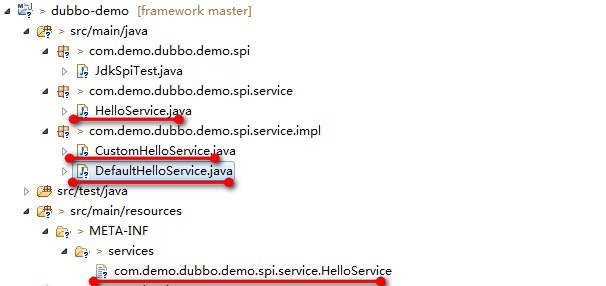
定义一个接口:com.demo.dubbo.demo.spi.service.HelloService
接口的实现类:
com.demo.dubbo.demo.spi.service.impl.DefaultHelloService
com.demo.dubbo.demo.spi.service.impl.CustomHelloService
然后在类路径下,创建META-INF/services/com.demo.dubbo.demo.spi.service.HelloService文件,内容如下:
com.demo.dubbo.demo.spi.service.impl.DefaultHelloService
com.demo.dubbo.demo.spi.service.impl.CustomHelloService
整体结构如下图所示:
使用方式如下:
ServiceLoader<HelloService> helloServiceLoader=ServiceLoader.load(HelloService.class);
for(HelloService item:helloServiceLoader){
item.hello();
}
2.2 ServiceLoader的源码分析
从上面可以看到,先根据ServiceLoader的load静态方法根据目标接口加载出一个ServiceLoader实例,然后可以遍历这个实例(实现了Iterable接口),获取到接口的所有实现类
来看下ServiceLoader的几个重要属性:
要加载的接口
private Class<S> service;
// The class loader used to locate, load, and instantiate providers
private ClassLoader loader;
// 用于缓存已经加载的接口实现类,其中key为实现类的完整类名
private LinkedHashMap<String,S> providers = new LinkedHashMap<>();
// 用于延迟加载接口的实现类
private LazyIterator lookupIterator;
首先第一步:获取一个ServiceLoader<HelloService> helloServiceLoader实例,此时还没有进行任何接口实现类的加载操作,属于延迟加载类型的。只是创建了LazyIterator lookupIterator对象而已。
第二步:ServiceLoader实现了Iterable接口,即实现了该接口的iterator()方法,实现内容如下:
public Iterator<S> iterator() {
return new Iterator<S>() {
Iterator<Map.Entry<String,S>> knownProviders
= providers.entrySet().iterator();
public boolean hasNext() {
if (knownProviders.hasNext())
return true;
return lookupIterator.hasNext();
}
public S next() {
if (knownProviders.hasNext())
return knownProviders.next().getValue();
return lookupIterator.next();
}
public void remove() {
throw new UnsupportedOperationException();
}
};
}
for循环遍历ServiceLoader的过程其实就是调用上述hasNext()和next()方法的过程
第一次循环遍历会使用lookupIterator去查找,之后就缓存到providers中。LazyIterator会去加载类路径下/META-INF/services/接口全称 文件的url地址,使用如下代码来加载:
String fullName = "META-INF/services/" + service.getName();
loader.getResources(fullName)
文件加载并解析完成之后,得到一系列的接口实现类的完整类名,调用next()方法时才回去真正执行接口实现类的加载操作,并根据无参构造器创建出一个实例,存到providers中;
之后再次遍历ServiceLoader,就直接遍历providers中的数据
2.3 ServiceLoader缺点分析
- 虽然ServiceLoader也算是使用的延迟加载,但是基本只能通过遍历全部获取,也就是接口的实现类全部加载并实例化一遍。如果你并不想用某些实现类,它也被加载并实例化了,这就造成了浪费。
- 获取某个实现类的方式不够灵活,只能通过Iterator形式获取,不能根据某个参数来获取对应的实现类
3 dubbo的扩展机制
3.1 简单功能介绍
dubbo的扩展机制和java的SPI机制非常相似,但是又增加了如下功能:
- 1 可以方便的获取某一个想要的扩展实现,java的SPI机制就没有提供这样的功能
- 2 对于扩展实现IOC依赖注入功能:
举例来说:接口A,实现者A1、A2。接口B,实现者B1、B2。
现在实现者A1含有setB()方法,会自动注入一个接口B的实现者,此时注入B1还是B2呢?都不是,而是注入一个动态生成的接口B的实现者B$Adpative,该实现者能够根据参数的不同,自动引用B1或者B2来完成相应的功能
- 3 对扩展采用装饰器模式进行功能增强,类似AOP实现的功能
还是以上面的例子,接口A的另一个实现者AWrapper1。大体内容如下:
private A a; AWrapper1(A a){
this.a=a;}
因此,我们在获取某一个接口A的实现者A1的时候,已经自动被AWrapper1包装了。
3.2 dubbo的ExtensionLoader解析扩展过程
以下面的例子为例来分析下:
ExtensionLoader<Protocol> protocolLoader=ExtensionLoader.getExtensionLoader(Protocol.class);
Protocol protocol=protocolLoader.getAdaptiveExtension();
其中Protocol接口定义如下:
@Extension("dubbo")
public interface Protocol {
int getDefaultPort();
@Adaptive
<T> Exporter<T> export(Invoker<T> invoker) throws RpcException;
@Adaptive
<T> Invoker<T> refer(Class<T> type, URL url) throws RpcException;
void destroy();
}
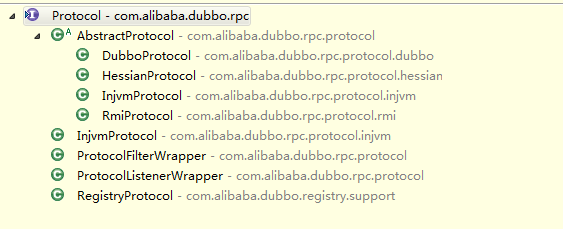
对应的实现者如下:
第一步:根据要加载的接口创建出一个ExtensionLoader实例
ExtensionLoader中含有一个静态属性:
ConcurrentMap<Class<?>, ExtensionLoader<?>> EXTENSION_LOADERS = new ConcurrentHashMap<Class<?>, ExtensionLoader<?>>();
用于缓存所有的扩展加载实例,这里加载Protocol.class,就以Protocol.class为key,创建的ExtensionLoader为value存储到上述EXTENSION_LOADERS中
这里没有进行任何的加载操作。
我们先来看下,ExtensionLoader实例是如何来加载Protocol的实现类的:
- 1 先解析Protocol上的Extension注解的name,存至String cachedDefaultName属性中,作为默认的实现
- 2 到类路径下的加载 META-INF/services/com.alibaba.dubbo.rpc.Protocol文件

该文件的内容如下:
com.alibaba.dubbo.registry.support.RegistryProtocol com.alibaba.dubbo.rpc.protocol.ProtocolFilterWrapper com.alibaba.dubbo.rpc.protocol.ProtocolListenerWrapper com.alibaba.dubbo.rpc.protocol.dubbo.DubboProtocol com.alibaba.dubbo.rpc.protocol.injvm.InjvmProtocol com.alibaba.dubbo.rpc.protocol.rmi.RmiProtocol com.alibaba.dubbo.rpc.protocol.hessian.HessianProtocol
然后就是读取每一行内容,加载对应的class。
- 3 对于上述class分成三种情况来处理
对于一个接口的实现者,ExtensionLoader分三种情况来分别存储对应的实现者,属性分别如下:
Class<?> cachedAdaptiveClass; Set<Class<?>> cachedWrapperClasses; Reference<Map<String, Class<?>>> cachedClasses;
情况1: 如果这个class含有Adaptive注解,则将这个class设置为Class<?> cachedAdaptiveClass。
情况2: 尝试获取带对应接口参数的构造器,如果能够获取到,则说明这个class是一个装饰类即,需要存到Set<Class<?>> cachedWrapperClasses中
情况3: 如果没有上述构造器。则获取class上的Extension注解,根据该注解的定义的name作为key,存至Reference<Map<String, Class<?>>> cachedClasses结构中
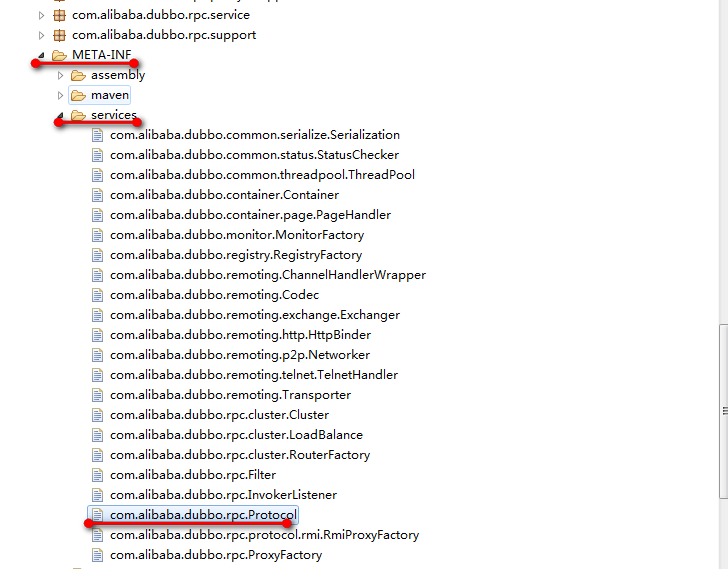
至此,解析文件过程结束。
以Protocol为例来详细介绍下整个过程:
- 1 解析Protocol上的Extension注解的name
@Extension("dubbo") public interface Protocol{
//略}
所以cachedDefaultName值为dubbo。
- 2 解析类路径下的加载 META-INF/services/com.alibaba.dubbo.rpc.Protocol文件
如DubboProtocol:
@Extension(DubboProtocol.NAME) public class DubboProtocol extends AbstractProtocol {
//略}
没有Adaptive注解,同时只有无参构造器,所以只能存放到Reference<Map<String, Class<?>>> cachedClasses中,key就是上述DubboProtocol.NAME即dubbo。
如ProtocolFilterWrapper:
public class ProtocolFilterWrapper implements Protocol {
private final Protocol protocol; public ProtocolFilterWrapper(Protocol protocol){ if (protocol == null) { throw new IllegalArgumentException("protocol == null"); } this.protocol = protocol; }}
含有Protocol参数的构造器,作为一个装饰类,存放至Set<Class<?>> cachedWrapperClasses中
同理ProtocolListenerWrapper:
public class ProtocolListenerWrapper implements Protocol {
private final Protocol protocol; public ProtocolListenerWrapper(Protocol protocol){ if (protocol == null) { throw new IllegalArgumentException("protocol == null"); } this.protocol = protocol; }}
含有Protocol参数的构造器,作为一个装饰类,存放至Set<Class<?>> cachedWrapperClasses中。
3.3 dubbo的ExtensionLoader获取扩展的过程
以获取DubboProtocol为例
ExtensionLoader<Protocol> protocolLoader=ExtensionLoader.getExtensionLoader(Protocol.class);
Protocol dubboProtocol=protocolLoader.getExtension(DubboProtocol.NAME);
获取过程如下:
private T createExtension(String name) {
Class<?> clazz = getExtensionClasses().get(name);
if (clazz == null) {
throw findException(name);
}
try {
T instance = injectExtension((T) clazz.newInstance());
Set<Class<?>> wrapperClasses = cachedWrapperClasses;
if (wrapperClasses != null && wrapperClasses.size() > 0) {
for (Class<?> wrapperClass : wrapperClasses) {
instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance));
}
}
return instance;
} catch (Throwable t) {
throw new IllegalStateException("Extension instance(name: " + name + ", class: " +
type + ") could not be instantiated: " + t.getMessage(), t);
}
}
大致分成4步:
- 1 根据name获取对应的class
首先获取ExtensionLoader<Protocol>对象的Reference<Map<String, Class<?>>> cachedClasses属性,如果为空则表示还没有进行解析,则开始进行上面的解析。解析完成之后,根据name获取对应的class,这里便获取到了DubboProtocol.class
- 2 根据获取到的class创建一个实例
- 3 对获取到的实例,进行依赖注入
- 4 对于上述经过依赖注入的实例,再次进行包装。即遍历Set<Class<?>> cachedWrapperClasses中每一个包装类,分别调用带Protocol参数的构造函数创建出实例,然后同样进行依赖注入
以Protocol为例,cachedWrapperClasses中存着上述提到过的ProtocolFilterWrapper、ProtocolListenerWrapper。分别会对DubboProtocol实例进行包装,这个比较好理解的
下面对于这个依赖注入的过程就要详细的说明下,来看下这个过程:
private T injectExtension(T instance) {
try {
for (Method method : instance.getClass().getMethods()) {
if (method.getName().startsWith("set")
&& method.getParameterTypes().length == 1
&& Modifier.isPublic(method.getModifiers())) {
Class<?> pt = method.getParameterTypes()[0];
if (pt.isInterface() && getExtensionLoader(pt).getSupportedExtensions().size() > 0) {
try {
Object adaptive = getExtensionLoader(pt).getAdaptiveExtension();
method.invoke(instance, adaptive);
} catch (Exception e) {
logger.error("fail to inject via method " + method.getName()
+ " of interface " + type.getName() + ": " + e.getMessage(), e);
}
}
}
}
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
return instance;
}
从上面可以看到,进行注入的条件如下:
- set开头的方法
- 方法的参数只有一个
- 方法必须是public
- 方法的参数必须是接口,并且是ExtensionLoader能够获取其扩展类
我们知道一个接口的实现者可能有多个,此时到底注入哪一个呢?
此时采取的策略是,并不去注入一个具体的实现者,而是注入一个动态生成的实现者,这个动态生成的实现者的逻辑是确定的,能够根据不同的参数来使用不同的实现者实现相应的方法。这个动态生成的实现者的class就是ExtensionLoader的Class<?> cachedAdaptiveClass
以Protocol为例,动态生成的Protocol实现者大概如下:
class Protocol$Adpative implements Protocol{
public com.alibaba.dubbo.rpc.Exporter export(com.alibaba.dubbo.rpc.Invoker arg0) throws com.alibaba.dubbo.rpc.RpcException{
if (arg0 == null) {
throw new IllegalArgumentException("com.alibaba.dubbo.rpc.Invoker argument == null");
}
if (arg0.getUrl() == null) {
throw new IllegalArgumentException("com.alibaba.dubbo.rpc.Invoker argument getUrl() == null");
}
com.alibaba.dubbo.common.URL url = arg0.getUrl();
String extName = ( url.getProtocol() == null ? "dubbo" : url.getProtocol() );
if(extName == null) {
throw new IllegalStateException("Fail to get extension(com.alibaba.dubbo.rpc.Protocol) name from url(" + url.toString() + ") use keys([protocol])");
}
com.alibaba.dubbo.rpc.Protocol extension = (com.alibaba.dubbo.rpc.Protocol)com.alibaba.dubbo.common.ExtensionLoader.getExtensionLoader(com.alibaba.dubbo.rpc.Protocol.class).getExtension(extName);
return extension.export(arg0);
}
public com.alibaba.dubbo.rpc.Invoker refer(java.lang.Class arg0,com.alibaba.dubbo.common.URL arg1) throws com.alibaba.dubbo.rpc.RpcException{
if (arg1 == null) {
throw new IllegalArgumentException("url == null");
}
com.alibaba.dubbo.common.URL url = arg1;
String extName = ( url.getProtocol() == null ? "dubbo" : url.getProtocol() );
if(extName == null) {
throw new IllegalStateException("Fail to get extension(com.alibaba.dubbo.rpc.Protocol) name from url(" + url.toString() + ") use keys([protocol])");
}
com.alibaba.dubbo.rpc.Protocol extension = (com.alibaba.dubbo.rpc.Protocol)com.alibaba.dubbo.common.ExtensionLoader.getExtensionLoader(com.alibaba.dubbo.rpc.Protocol.class).getExtension(extName);
return extension.refer(arg0, arg1);
}
public void destroy(){
throw new UnsupportedOperationException("method public abstract void com.alibaba.dubbo.rpc.Protocol.destroy() of interface com.alibaba.dubbo.rpc.Protocol is not adaptive method!");
}
}
从上面的代码中可以看到,Protocol$Adpative是根据URL参数中protocol属性的值来选择具体的实现类的。
如值为dubbo,则从ExtensionLoader<Protocol>中获取dubbo对应的实例,即DubboProtocol实例
如值为hessian,则从ExtensionLoader<Protocol>中获取hessian对应的实例,即HessianProtocol实例
也就是说Protocol$Adpative能够根据url中的protocol属性值动态的采用对应的实现。
对于上述获取动态实现者即Protocol$Adpative的过程还需要补充一些细节内容:
- 1 要求对应的接口中的某些方法必须含有Adaptive注解,没有Adaptive注解,则表示不需要生成动态类
- 2 对于接口的方法中不含Adaptive注解的,全部是不可调用的,如上述的destroy()方法
- 3 含有Adaptive注解的方法必须含有URL类型的参数,或者能够获取到URL,分别如上述的refer方法和export方法
- 4 从URL中根据什么参数来获取实现者信息呢?以Protocol为例,参数就为"protocol",默认是接口简单名称首字母小写或者接口中指定的默认实现,对于别的接口,我们从url的哪个参数中获取对应的实现者呢?这就可以从Adpative注解中给出,下面给出一个Transporter例子
Transporter接口内容如下:
@Extension("netty")
public interface Transporter {
@Adaptive({Constants.SERVER_KEY, Constants.TRANSPORTER_KEY})
Server bind(URL url, ChannelHandler handler) throws RemotingException;
@Adaptive({Constants.CLIENT_KEY, Constants.TRANSPORTER_KEY})
Client connect(URL url, ChannelHandler handler) throws RemotingException;
}
接口Transporter指定的默认实现是"netty",同时@Adaptive注解中又给出了"client"和"transporter"。
所以获取实现的过程如下:
public com.alibaba.dubbo.remoting.Client connect(com.alibaba.dubbo.common.URL arg0,com.alibaba.dubbo.remoting.ChannelHandler arg1) throws com.alibaba.dubbo.remoting.RemotingException{
if (arg0 == null) {
throw new IllegalArgumentException("url == null");
}
com.alibaba.dubbo.common.URL url = arg0;
String extName = url.getParameter("client", url.getParameter("transporter", "netty"));
if(extName == null) {
throw new IllegalStateException("Fail to get extension(com.alibaba.dubbo.remoting.Transporter) name from url(" + url.toString() + ") use keys([client, transporter])");
}
com.alibaba.dubbo.remoting.Transporter extension = (com.alibaba.dubbo.remoting.Transporter)com.alibaba.dubbo.common.ExtensionLoader.getExtensionLoader(com.alibaba.dubbo.remoting.Transporter.class).getExtension(extName);
return extension.connect(arg0, arg1);
}
String extName = url.getParameter("client", url.getParameter("transporter", "netty"));
先根据client来获取,如果获取不到再根据transporter来获取,如果还获取不到,则直接使用Transporter默认指定的netty。
至此,dubbo的ExtensionLoader的内容大概就说完了。
4 结束语
下一篇文章就开始介绍下,服务器端暴漏服务和向注册中心注册服务的过程