背景介绍
Elasticsearch 是开源搜索平台的新成员,实时数据分析的神器,发展迅猛,基于 Lucene、RESTful、分布式、面向云计算设计、实时搜索、全文搜索、稳定、高可靠、可扩展、安装+使用方便。
PostgreSQL 是起源自伯克利大学的开源数据库,历史悠久,内核扩展性极强,用户横跨各个行业。
关于PostgreSQL的内核扩展指南请参考
传统数据库与搜索引擎ES如何同步
例如用户需要将数据库中某些数据同步到ES建立索引,传统的方法需要应用来负责数据的同步。
这种方法会增加一定的开发成本,时效也不是非常的实时。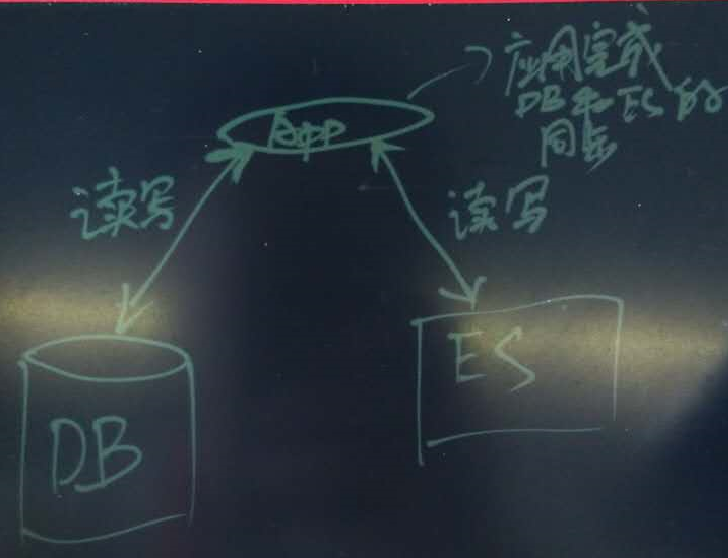
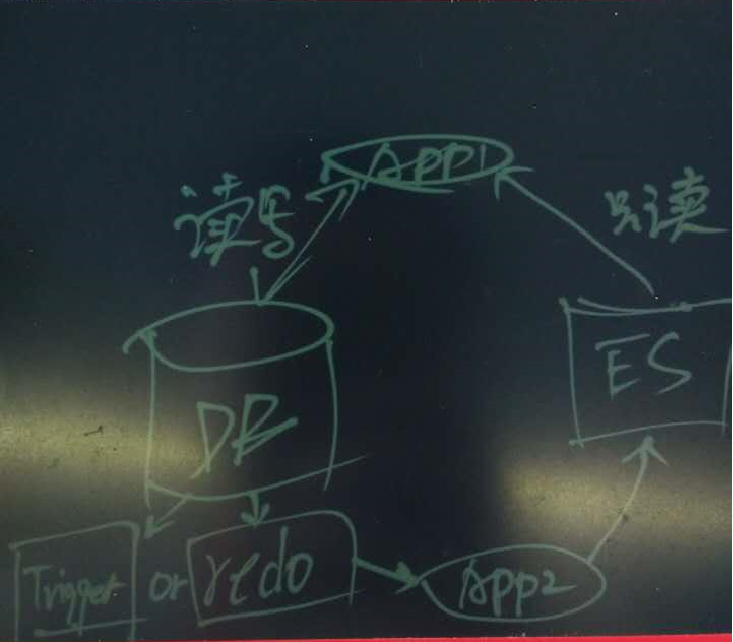
PostgreSQL与ES结合有什么好处
PostgreSQL的扩展插件pg-es-fdw,使用PostgreSQL的foreign data wrap,允许直接在数据库中读写ES,方便用户实时的在ES建立索引。
这种方法不需要额外的程序支持,时效也能得到保障。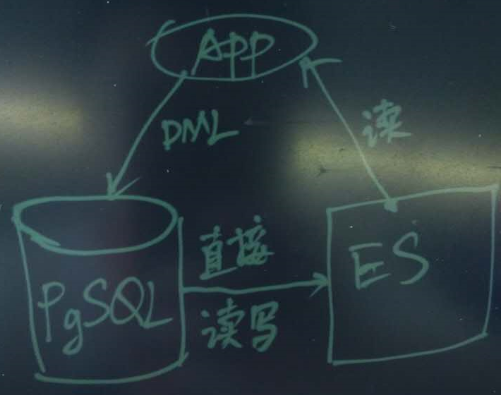
case
安装PostgreSQL 9.5
略,需要包含 --with-python
安装 ES on CentOS 7
# yum install -y java-1.7.0-openjdk
# rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
# vi /etc/yum.repos.d/es.repo
[elasticsearch-2.x]
name=Elasticsearch repository for 2.x packages
baseurl=https://packages.elastic.co/elasticsearch/2.x/centos
gpgcheck=1
gpgkey=https://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1
# yum install -y elasticsearch
# /bin/systemctl daemon-reload
# /bin/systemctl enable elasticsearch.service
# /bin/systemctl start elasticsearch.service
# python --version
Python 2.7.5
# curl -X GET 'http://localhost:9200'
{
"name" : "Red Wolf",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "2.3.3",
"build_hash" : "218bdf10790eef486ff2c41a3df5cfa32dadcfde",
"build_timestamp" : "2016-05-17T15:40:04Z",
"build_snapshot" : false,
"lucene_version" : "5.5.0"
},
"tagline" : "You Know, for Search"
}
python client
# easy_install pip
# pip install elasticsearch
PostgreSQL 插件 multicorn
# wget http://api.pgxn.org/dist/multicorn/1.3.2/multicorn-1.3.2.zip
# unzip multicorn-1.3.2.zip
# cd multicorn-1.3.2
# export PATH=/home/digoal/pgsql9.5/bin:$PATH
# make && make install
# su - digoal
$ psql
postgres=# create extension multicorn ;
CREATE EXTENSION
PostgreSQL 插件 pg-es-fdw (foreign server基于multicorn)
# git clone https://github.com/Mikulas/pg-es-fdw /tmp/pg-es-fdw
# cd /tmp/pg-es-fdw
# export PATH=/home/digoal/pgsql9.5/bin:$PATH
# python setup.py install
# su - digoal
$ psql
使用例子
基于multicorn创建es foreign server
CREATE SERVER multicorn_es FOREIGN DATA WRAPPER multicorn
OPTIONS (
wrapper 'dite.ElasticsearchFDW'
);
创建测试表
CREATE TABLE articles (
id serial PRIMARY KEY,
title text NOT NULL,
content text NOT NULL,
created_at timestamp
);
创建外部表
CREATE FOREIGN TABLE articles_es (
id bigint,
title text,
content text
) SERVER multicorn_es OPTIONS (host '127.0.0.1', port '9200', node 'test', index 'articles');
创建触发器
对实体表,创建触发器函数,在用户对实体表插入,删除,更新时,通过触发器函数自动将数据同步到对应ES的外部表。
同步过程调用FDW的接口,对ES进行索引的建立,更新,删除。
CREATE OR REPLACE FUNCTION index_article() RETURNS trigger AS $def$
BEGIN
INSERT INTO articles_es (id, title, content) VALUES
(NEW.id, NEW.title, NEW.content);
RETURN NEW;
END;
$def$ LANGUAGE plpgsql;
CREATE OR REPLACE FUNCTION reindex_article() RETURNS trigger AS $def$
BEGIN
UPDATE articles_es SET
title = NEW.title,
content = NEW.content
WHERE id = NEW.id;
RETURN NEW;
END;
$def$ LANGUAGE plpgsql;
CREATE OR REPLACE FUNCTION delete_article() RETURNS trigger AS $def$
BEGIN
DELETE FROM articles_es a WHERE a.id = OLD.id;
RETURN OLD;
END;
$def$ LANGUAGE plpgsql;
CREATE TRIGGER es_insert_article
AFTER INSERT ON articles
FOR EACH ROW EXECUTE PROCEDURE index_article();
CREATE TRIGGER es_update_article
AFTER UPDATE OF title, content ON articles
FOR EACH ROW
WHEN (OLD. IS DISTINCT FROM NEW.)
EXECUTE PROCEDURE reindex_article();
CREATE TRIGGER es_delete_article
BEFORE DELETE ON articles
FOR EACH ROW EXECUTE PROCEDURE delete_article();
测试
curl 'localhost:9200/test/articles/_search?q=:&pretty'
psql -c 'SELECT * FROM articles'
写入实体表,自动同步到ES
psql -c "INSERT INTO articles (title, content, created_at) VALUES ('foo', 'spike', Now());"
psql -c 'SELECT * FROM articles'
查询ES,检查数据是否已同步
curl 'localhost:9200/test/articles/_search?q=:&pretty'
更新实体表,数据自动同步到ES
psql -c "UPDATE articles SET content='yeay it updates\!' WHERE title='foo'"
查询ES数据是否更新
curl 'localhost:9200/test/articles/_search?q=:&pretty'
参考
https://www.elastic.co/guide/en/elasticsearch/reference/current/setup-repositories.html
http://www.vpsee.com/2014/05/install-and-play-with-elasticsearch/
https://github.com/Mikulas/pg-es-fdw
https://wiki.postgresql.org/wiki/Fdw
http://multicorn.org/
http://pgxn.org/dist/multicorn/
http://multicorn.readthedocs.io/en/latest/index.html
小结
- PostgreSQL提供的FDW接口,允许用户在数据库中直接操纵外部的数据源,所以支持ES只是一个例子,还可以支持更多的数据源。
这是已经支持的,几乎涵盖了所有的数据源。
https://wiki.postgresql.org/wiki/Fdw - multicorn在FDW接口的上层再抽象了一层,支持使用python写FDW接口,方便快速试错,如果对性能要求不是那么高,直接用multicore就可以了。
- 开发人员如何编写FDW? 可以参考一下如下:
http://multicorn.readthedocs.io/en/latest/index.html
https://www.postgresql.org/docs/9.6/static/fdwhandler.html
附录
###
### Author: Mikulas Dite
### Time-stamp: <2015-06-09 21:54:14 dwa>
from multicorn import ForeignDataWrapper
from multicorn.utils import log_to_postgres as log2pg
from functools import partial
import httplib
import json
import logging
class ElasticsearchFDW (ForeignDataWrapper):
def __init__(self, options, columns):
super(ElasticsearchFDW, self).__init__(options, columns)
self.host = options.get('host', 'localhost')
self.port = int(options.get('port', '9200'))
self.node = options.get('node', '')
self.index = options.get('index', '')
self.columns = columns
def get_rel_size(self, quals, columns):
"""Helps the planner by returning costs.
Returns a tuple of the form (nb_row, avg width)
"""
conn = httplib.HTTPConnection(self.host, self.port)
conn.request("GET", "/%s/%s/_count" % (self.node, self.index))
resp = conn.getresponse()
if not 200 == resp.status:
return (0, 0)
raw = resp.read()
data = json.loads(raw)
# log2pg('MARK RESPONSE: >>%d<<' % data['count'], logging.DEBUG)
return (data['count'], len(columns) * 100)
def execute(self, quals, columns):
conn = httplib.HTTPConnection(self.host, self.port)
conn.request("GET", "/%s/%s/_search&size=10000" % (self.node, self.index))
resp = conn.getresponse()
if not 200 == resp.status:
yield {0, 0}
raw = resp.read()
data = json.loads(raw)
for hit in data['hits']['hits']:
row = {}
for col in columns:
if col == 'id':
row[col] = hit['_id']
elif col in hit['_source']:
row[col] = hit['_source'][col]
yield row
@property
def rowid_column(self):
"""Returns a column name which will act as a rowid column,
for delete/update operations. This can be either an existing column
name, or a made-up one.
This column name should be subsequently present in every
returned resultset.
"""
return 'id';
def es_index(self, id, values):
content = json.dumps(values)
conn = httplib.HTTPConnection(self.host, self.port)
conn.request("PUT", "/%s/%s/%s" % (self.node, self.index, id), content)
resp = conn.getresponse()
if not 200 == resp.status:
return
raw = resp.read()
data = json.loads(raw)
return data
def insert(self, new_values):
log2pg('MARK Insert Request - new values: %s' % new_values, logging.DEBUG)
if not 'id' in new_values:
log2pg('INSERT requires "id" column. Missing in: %s' % new_values, logging.ERROR)
id = new_values['id']
new_values.pop('id', None)
return self.es_index(id, new_values)
def update(self, id, new_values):
new_values.pop('id', None)
return self.es_index(id, new_values)
def delete(self, id):
conn = httplib.HTTPConnection(self.host, self.port)
conn.request("DELETE", "/%s/%s/%s" % (self.node, self.index, id))
resp = conn.getresponse()
if not 200 == resp.status:
log2pg('Failed to delete: %s' % resp.read(), logging.ERROR)
return
raw = resp.read()
return json.loads(raw)
## Local Variables: ***
## mode:python ***
## coding: utf-8 ***
## End: ***