在ATI Stream Computing Programming Guide中,例举了AMD 5系列显卡的参数信息。
我比较关注其中Peak bandwidths的计算,以便在opencl程序测试bandwidth利用率。
下面,我以5870为例,探讨一下如何计算得到这些结果:
L1 cache的 peak bandwidth(L1<=>ALU) = compute units* Wavefront Size/compute Unit *Engine clock = cu数量*每个cu的wave大小*显卡系统时钟频率
= 20 * 64 * 0.85 = 1088 GB/s
注:在AMD GPU中,每个wave包含64个thread.
L2 cache peak bandwidth(L1<=>L2) = Number of Channels * wavefrontSize * Engine clock = 内存通道数量*wave大小*显卡系统时钟频率
= 8 * 64 * 0.85 = 435.2 GB/s
注:在AMD 8XXX显卡中,每个mc通道对应一个64K的L2 cache。
Global memeory peak rate(L2<=>Memory) = Number of Channels * memory pin rate * bits per chanel/8 = 内存通道数量*memory pin rate*每个channel位宽/8
= 8 * 4.800 * 32/8 = 153.6 GB/s
注:在cypress中,用的GDDR5,mclk是1200MHZ, GDDR5的date rate 是4,所以memory pin rate = 1200 * 4 = 4800Mb/pin
除以8是转化为字节。
Const cache read peak rate = peak read bandwidth per stream core * pe number * engine clock = 每个pe 的读带宽*pe数量*系统时钟频率
= 16 * 320 * 0.85 = 4352 GB/s
注:5870中的hardware参数
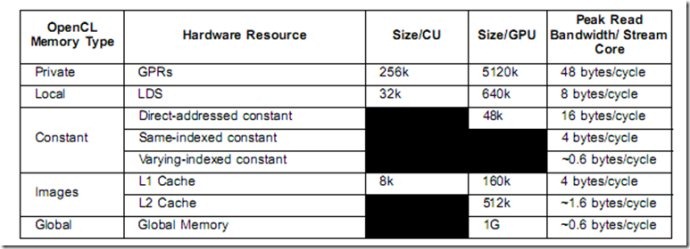
另外需要注意的对于consant buffer,只有直接地址访问时候,才能达到4352GB/s的峰值,如果通过索引方式,参考上表,用4或这0.6代替16.
LDS Read peak rate = peak read bandwidth per stream core * pe number * engine clock = 每个pe 的读带宽*pe数量*系统时钟频率
= 8 * 320 * 0.85 = 2176 Gb/s
注:LDS(对应cl中local memory)带宽计算方式和const buffer一样。
GPR read peak rate = peak read bandwidth per stream core * pe number * engine clock = 每个pe 的读带宽*pe数量*系统时钟频率
= 48 * 320 * 0.85 = 13056 GB/s
注:GPR(通用寄存器,对应cl中worktime 使用的private变量,对于kernel中局部变量,shade compiler一般都为其分配GPR)带宽计算方式和const buffer一样
下图为58xx的性能参数:
