远程过程调用(RPC)
(使用Java客户端)
在指南的第二部分,我们学习了如何使用工作队列将耗时的任务分布到多个工作者中。
但是假如我们需要调用远端计算机的函数,等待结果呢?好吧,这又是另一个故事了。这模式通常被称为远程过程调用或RPC。
在这部分,我们将会使用RabbitMQ构建一个RPC系统:一个客户端和一个可扩展的RPC服务器。由于我们还没有值得分散的耗时任务,我们将会创建一个虚拟的RPC服务,用来返回Fibonacci(斐波纳契数列)。
用户接口
为了说明RPC服务如何使用,我们将会创建一个简单德客户端类。它会暴露一个叫call的方法,用来发送一个RPC请求,在响应回复之前都会一直阻塞:
FibonacciRpcClient fibonacciRpc = new FibonacciRpcClient();
String result = fibonacciRpc.call("4");
System.out.println( "fib(4) is " + result);
RPC方面的注意
虽然RPC在电脑运算方面是一个十分普通的模式,但是它依旧常常受批判的。
如果一个程序员没有意识到函数call是本地的还是一个迟钝的RPC。这结果是不可预知的很让你困惑的,并且会增加不必要的复杂调试。与简化软件相反,误用RPC会导致不可维护的意大利面条代码(译者注:原文是spaghetti code可能形容代码很长很乱)。
思想中煎熬,考虑下接下来的建议:
确保明显区分哪个是函数call是本地调用的,哪个是远端调用的。
给你的系统加上文档,让组件之间的依赖项清晰可见的。
处理错误事件。当RPC服务器很久没有响应了,客户端应该如何响应?
当关于RPC的所有疑问消除,在你可以的情况下,你应该使用一个异步的管道,代替RPC中阻塞,结果会异步的放入接下来的计算平台。
回收队列
一般来说在RabbitMQ上做RPC是容易的。一个客户端发送一个请求消息,一个服务器返回响应消息。为了接受到响应,我们需要再请求中带上一个callback队列的地址。我们可以使用默认队列(那个在Java客户端上市独占的)。让我们试一下:
callbackQueueName = channel.queueDeclare().getQueue();
BasicProperties props = new BasicProperties
.Builder()
.replyTo(callbackQueueName)
.build();
channel.basicPublish("", "rpc_queue", props, message.getBytes());
// ... then code to read a response message from the callback_queue ...
消息属性
这AMQP协议预先确定了消息中的14个属性。他们大多数属性很少使用,除了下面这些例外:deliveryMode:将一个消息标记为持久化(值为2)或者瞬态的(其他值)。你可能从第二部分中记起这个属性。contentType:用来描述媒体类型的编码。例如常常使用的JSON编码,这是一个好的惯例,设置这个属性为:application/json。replyTo:通常来命名回收队列的名字。correlationId:对RPC加速响应请求是很有用的。
我们需要这个新的引用:
import com.rabbitmq.client.AMQP.BasicProperties;
相关性ID (原:Correlation Id)
在当前方法中我们建议为每一个RPC请求创建一个回收队列。这个效率十分低下的,但幸运的是有一个更好的方式- 让我们为每一个客户端创建一个单一的回收队列。
这样又出现了新的问题,没有清晰的判断队列中的响应是属于哪个请求的。这个时候coorrelationId属性发挥了作用。我们将每个请求的这个属性设置为唯一值。以后当我们在回收队列中接收消息时,我们将会查看这个属性,依据这个属性值,我们是能将每个响应匹配的对应的请求上。如果我们遇见个未知的correlationId值,我们可以安全的丢弃这个消息-因为它不属于任何一个我们的请求。
你可能会问,为什么我们要忽略哪些在回收队列中未知的消息,而不是以一个错误结束?因为在服务器竟态条件下,这种情况是可能的。RPC服务器发送给
我们答应之后,在发送一个确认消息之前,就死掉了,虽然这种可能性不大,但是它依旧存在可能。如果这事情发生了,RPC服务器重启之后,将会再一次处理请
求。这就是为什么我们要温和地处理重复的响应,这RPC理想情况下是幂等的。
摘要
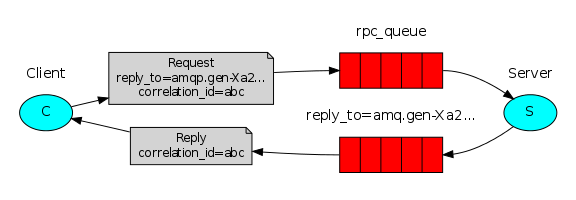
我们的RPC将会像这样工作:
当客户端启动,它会创建一个匿名的独占的回收队列。
对于一个RPC请求,客户端会发送一个消息中有两个属性:replyTo,要发送的的回收队列和correlationId,对于每一个请求都是唯一值。
这请求发送到rpc_queue队列中。
这RPC工作者(亦称:服务器)等候队列中的请求。当请求出现,它处理这工作并发送携带结果的信息到客户端,使用的队列是消息属性replTo中的那个。
客户端等待回收队列中的数据。当一个消息出现,它会检查correlationId属性。如果它符合请求中的值,它会返回这响应给应用程序。
把所有的放在一起
斐波那契任务:
private static int fib(int n) throws Exception {
if (n == 0) return 0;
if (n == 1) return 1;
return fib(n-1) + fib(n-2);
}
我们声明我们的斐波那契函数。它假定一个合法的正整数做为输入参数。(不要期望这个可以处理大量数字,它可能是最慢的递归实现了)。
我们的RPC服务器RPCServer.java的代码:
private static final String RPC_QUEUE_NAME = "rpc_queue";
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.queueDeclare(RPC_QUEUE_NAME, false, false, false, null);
channel.basicQos(1);
QueueingConsumer consumer = new QueueingConsumer(channel);
channel.basicConsume(RPC_QUEUE_NAME, false, consumer);
System.out.println(" [x] Awaiting RPC requests");
while (true) {
QueueingConsumer.Delivery delivery = consumer.nextDelivery();
BasicProperties props = delivery.getProperties();
BasicProperties replyProps = new BasicProperties
.Builder()
.correlationId(props.getCorrelationId())
.build();
String message = new String(delivery.getBody());
int n = Integer.parseInt(message);
System.out.println(" [.] fib(" + message + ")");
String response = "" + fib(n);
channel.basicPublish( "", props.getReplyTo(), replyProps, response.getBytes());
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
}
这服务器代码是相当简单明了的:
如往常一样,我们开始建立连接,通道和声明队列。
我们可能想运行不止一个服务器进程。为了均衡的负载到多个服务器上,我们需要设置channel.basicQos中的prefetchCount属性。
我们使用basicConsume访问队列。然后进入while循环,我们等待请求消息,处理工作,发送响应。
我们RPC客户端RPCClient.java的代码:
private Connection connection;
private Channel channel;
private String requestQueueName = "rpc_queue";
private String replyQueueName;
private QueueingConsumer consumer;
public RPCClient() throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
connection = factory.newConnection();
channel = connection.createChannel();
replyQueueName = channel.queueDeclare().getQueue();
consumer = new QueueingConsumer(channel);
channel.basicConsume(replyQueueName, true, consumer);
}
public String call(String message) throws Exception {
String response = null;
String corrId = java.util.UUID.randomUUID().toString();
BasicProperties props = new BasicProperties
.Builder()
.correlationId(corrId)
.replyTo(replyQueueName)
.build();
channel.basicPublish("", requestQueueName, props, message.getBytes());
while (true) {
QueueingConsumer.Delivery delivery =consumer.nextDelivery();
if (delivery.getProperties().getCorrelationId().equals(corrId)) {
response = new String(delivery.getBody());
break;
}
}
return response;
}
public void close() throws Exception {
connection.close();
}
The client code is slightly more involved:
这客户端代码是更加清晰:
我们建立一个连接和通道并且声明一个独占的callback队列用来等待答复。
我们订阅这个callback队列,以便于我们可以接收到RPC响应。
我们的call方法做这真正的RPC请求。
接着,我们首次生成一个唯一的correlationId数字并且保存它,在循环中使用这个值找到合适的响应。
接下来,我们发布请求消息,带着两个属性:replyTo和correlationId。
这时候,我们可以坐下来,等着合适的响应抵达。
这循环中做了个简单德工作,检查每一个响应消息中correlationId值,是否是它要寻找的。如果是,它会保存这响应。
最终,我们把响应返回给用户。
制造客户端请求:
RPCClient fibonacciRpc = new RPCClient();
System.out.println(" [x] Requesting fib(30)");
String response = fibonacciRpc.call("30");
System.out.println(" [.] Got '" + response + "'");
fibonacciRpc.close();
现在是时候让我们回顾下我们RPCClient.java和RPCServer.java中的全部例子的源码(包含基本的异常处理)。
编译和如往常一样建立类路径(看指南的第一部分)
$ javac -cp rabbitmq-client.jar RPCClient.java RPCServer.java
我们的RPC服务现在准备好了,我们启动着服务器:
$ java -cp $CP RPCServer
[x] Awaiting RPC requests
为了请求一个斐波那契数字,运行客户端:
$ java -cp $CP RPCClient
[x] Requesting fib(30)
现在的设计不仅仅可以实现一个RPC服务,并且它还有几项重要的优势:
如果RPC服务器反应太迟缓,你可以通过运行另一个程序来扩展。试着通过一个新的控制平台来运行第二个RPC服务器。在客户端这边,RPC要求仅发送和接收一个消息。像queueDeclare非同步调用是被要求的。因此,RPC客户端仅仅需要一个网络循环的单一RPC请求。
我们的代码一直是十分简单的,不能试着解决更复杂(但是重要)的问题,比如:
如果没有服务器运行,客户端如何响应?
客户端是否对RPC的超时有处理?
如果服务器发生故障,抛出一个异常,是否应该传递到客户端?
在处理之前把进入来的非法消息隔离掉(检查界限,类型)。