1.2 R语言引论
本节将开始使用基础的R编程知识来做数据管理和数据处理,其中也会讲到一些编程技巧。R可以从https://www.r-project.org/ 下载。用户可以基于自己的操作系统下载和安装R二进制文件。R编程语言作为S语言的扩展,是一个统计计算平台。它提供高级预测建模、机器学习算法实施和更好的图表可视化。R还提供了适用于其他平台的插件,比如R.Net、rJava、SparkR和RHadoop,这提高了它在大数据场景下的可用性。用户可以将R脚本移植到其他编程环境中。关于R的详细信息,读者请参考:
1.2.1 快速入门
启动R时的信息如下图所示。所有输入R控制台的都是对象,在一个激活的R会话中创建的对象都有各自不同的属性,而一个对象附有的一个共同属性称作它的类。在R中执行面向对象编程有两种比较普遍的方法,即S3类和S4类。S3和S4的主要区别在于前者更加灵活,后者是更结构化的面向对象编程语言。S3和S4方法都将符号、字符和数字当作R会话中的一个对象,并提供了可使对象用于进一步计算的功能。
1.2.2 数据类型、向量、数组与矩阵
数据集可分为两大类型:原子向量和复合向量。在R语言中,原子向量可以分为5种类型,即数值或数字型、字符或字符串型、因子型、逻辑型以及复数型;复合向量分为4种类型,即数据框、列表、数组以及矩阵。R中最基本的数据对象是向量,即使将单数位数字赋给一个字母,也会被视为一个单元素向量。所有数据对象都包含模式和长度属性,其中模式定义了在这个对象里存放的数据类型,长度则定义了对象中包含的元素个数。R语言中的c()函数用于将多种元素连接成一个向量。
让我们来看R中不同数据类型的一些示例:

在上述代码中,向量x1是一个数值型向量,元素个数是5。class()和mode()返回相同的结果,因此都是在确定向量的类型:

在上述代码中,向量x2是由5个元素组成的一个逻辑型向量。逻辑型向量的元素或值可以写成T/F或者TRUE/FALSE。

在上述代码中,向量x3代表了一个长度为25的字符型向量。该向量中的所有元素都可以用双引号(" ")或单引号(' ')调用。

因子是数据的另一种格式,因子型向量中列出了多种分类(也称“水平”)。在上述代码中向量a是一个字符型向量,它的两个水平/分类以一定频率重复。as.factor()命令用于将字符型向量转换成因子数据类型。使用该命令后,我们可以看到它有5个水平:Analytics、DataMining、MachineLearning、Projects和Statistics。table()命令可用于显示因子变量频数表的计算结果:

数据框是R中另一种常见的数据格式,它可以包含所有不同的数据类型。数据框是一个列表,其中包含了多个等长的向量和不同类型的数据。如果只是从电子表格导入数据集,那么该数据类型将默认为数据框。之后,每个变量的数据类型均可更改。因此,数据框可定义为由包含不同类型的变量列组成的一个矩阵。在前面的代码中,数据框x包含了三种数据类型:数值型、逻辑型和字符型。大多数真实数据集会包含不同的数据类型,比如,零售商店里存储在数据库中的客户信息就包括客户ID、购买日期、购买数量、是否参与了会员计划等。
关于向量的一个要点:向量中的所有元素必须是同类型的。如果不是,R会进行强行转换。例如,在一个数值型向量中,如果有一个元素是字符型,该向量的类型会从数值型转换成字符型。代码如下所示:

R是区分大小写的,比如,“cat”与“Cat”,它们是不同的。所以,用户在给向量分配对象名字时必须格外注意。
有时,要记住所有对象名字不总是那么容易,示例如下:


若想知道当前R会话中的所有活动对象,可使用ls()命令。list命令也会输出当前R会话中的所有活动对象。下面我们来看看什么是列表、如何从列表中提取元素以及如何使用list函数。
1.2.3 列表管理、因子与序列
列表是一个可包含抽象对象的有序对象集合。列表中的元素可以通过双重中括号获取。不要求所包含的对象是同一类型,示例如下:

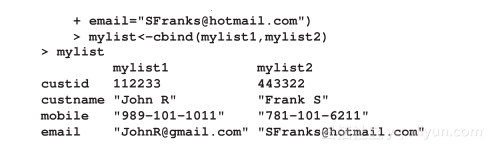
在上面的例子中,客户ID及其手机号是数值型变量,而客户名字及其电子邮箱地址是字符型变量。上面的列表中共有4个元素。如果要从列表中提取元素,则可使用双重中括号;如果只需从中提取子列表,则使用中括号即可,示例如下:

关于列表,接下来的操作是如何合并一个以上的列表。多个列表可以通过cbind()函数合并,即列合并函数,示例如下:

因子可定义为在分类或名义变量中以一定频率出现的水平。换句话说,在分类变量中重复出现的水平就被称为因子。在下面给出的样例脚本中,一个字符型向量“域”包含了很多个水平,使用factor命令可以估算每个水平的出现频率。
序列是重复的迭代个数,无论是数值、分类值还是名义值,都可以组成一个序列数据集。数值序列可利用一个冒号运算符生成。如果要用因子变量生成序列,可以使用gl()函数。在计算分位数和画图函数时,这个函数特别有用。gl()函数也可应用于其他一些场景,示例如下:

代码的第一行生成升序的序列,第二行生成降序的序列,最后一行生成因子数据类型序列。
1.2.4 数据的导入与导出
如果设定了Windows目录路径,那么要导入一个文件到R系统,就并不需要输入文件所在的全路径。如果Windows目录路径设定的是系统的其他路径,而你仍然要读取那个文件,则需要给出文件所在的全路径:

文档中的所有文件都可以不指定详细路径就能读取得到。所以建议读者将目录设定成文件所在目录。
文件格式有很多种,其中CSV或者TXT格式最适合R语言平台,示例如下。不过,我们也可以导入其他格式的文件。

如果使用的是read.csv命令,不需要将header(表头)设置成True,也不需要将separator(分隔符)设置成comma(逗号)。但如果使用的是read.table命令,那就必须这样设置,否则R会从表头开始读取数据。

在输入提取文件路径时,使用“/”或者“\”都可以。在实际项目中,典型的数据是以Excel格式存储的。而如何从Excel表读取数据是一个挑战。如果先将数据存成CSV格式再导入R并不总是那么方便。下面的脚本将展示如何在R中导入Excel文件。我们需要调用两个外部的库来导入像Excel这样的关系数据库管理系统(RDBMS)文件。这两个库将在脚本中提及,其中还给出了一部分样例数据:

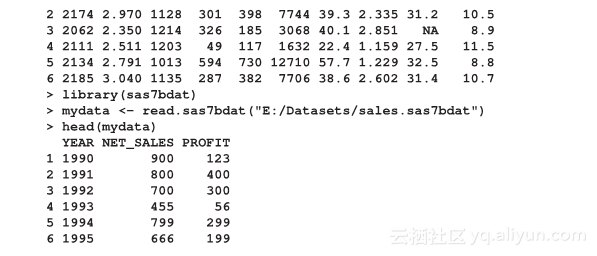
导入SPSS文件的方法如下所示。传统企业级软件系统产生的数据要么是SPSS格式,要么是SAS格式。导入SPSS和SAS文件的语法需要额外的包或者库。导入SPSS文件需要使用Hmisc包,导入SAS文件则需要使用sas7bdat库:

若要从R中导出一个数据集到任何一个外部地址,可以把read命令改成write命令,再把目录路径改为导出文件的路径。