摘要
本篇文章主要会详细聊一下表格存储的查询操作,以及如何根据业务的需求来设计表结构以支持特定条件的查询。
在理解查询操作之前,会简单描述一下表格存储的数据模型,以加深对查询操作的理解。
数据模型
表格存储(TableStore)的数据模型可以简化为使用下面这个数据结构来表示:
表格存储数据模型: SortedMap<PrimaryKey, List<Column>>
逻辑上理解表格存储的数据模型,就是一个SortedMap,只不过这是一个非常巨大的SortedMap,可承载的数据量可达到上亿、上百亿甚至更多条,数据量上限完全可以随着集群的规模水平扩展。
要支撑这么多数据的存储和查询,必须通过分布式的解决方案。逻辑上的数据模型,映射到实际的物理架构图如下:
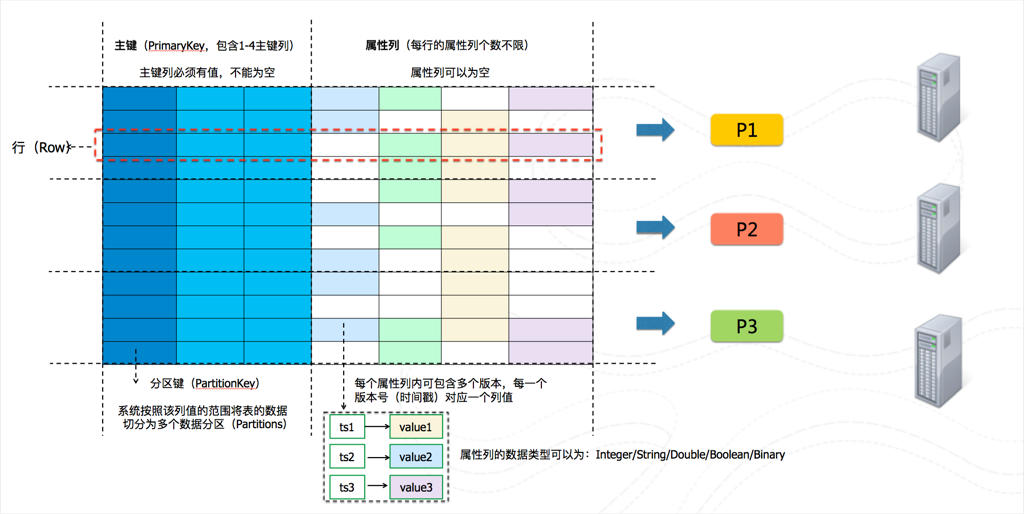
数据模型的几个基础概念可以参考产品文档。
在表格存储内部,一个表在创建的时候需要定义主键,主键会由多列组成,我们会选择主键的第一列作为分片键。当表的大小逐渐增大后,表会分裂,由原来的一个分区自动分裂成多个分区。触发分裂的因素会有很多,其中一个很关键的因素就是数据量。分裂后,每个分区会负责某个独立的分片键范围,每个分区管理的分片键范围都是无重合的,且范围是连续的。在后端会根据写入数据行的分片键的范围,来定位到是哪个分片。
查询操作
表格存储提供的查询API包括:
- GetRow: 给定行的主键,查询某一行。
- GetRange:给定行的主键范围,查询该范围内的所有行。
- BatchGetRow:给定多行的主键,查询多行。
从本质上来说,表格存储只提供两种类型的查询:单行查询和范围查询,BatchGetRow只是批量的单行查询。上面也提到了表格存储的数据模型其实是逻辑上的一个巨大的SortedMap,那查询操作也能完全映射到SortedMap提供的相应接口(以Java举例):
| 操作类型 | SortedMap接口 | 接口说明 |
|---|---|---|
| 单行查询 | V get(Object key)); | Returns the value to which the specified key is mapped. |
| 范围查询 | SortedMap subMap(K fromKey, K toKey); | Returns a view of the portion of this map whose keys range from fromKey, inclusive, to toKey, exclusive. |
主键的比较
主键由多列组成,大小比较的规则是:会按TableMeta定义的主键顺序,依次比较各个主键列,若当前比较的主键列值相等,则比较下一列;若当前比较的主键列不相等,则该主键列的大小决定主键的大小;当所有主键列都相等时,才代表主键相等。
不同类型的主键的比较规则:
| 类型 | 比较规则 | 代码 |
|---|---|---|
| 整型(Integer) | 有符号长整型比较 | Long.compareTo(Long other) |
| 布尔型(Boolean) | 布尔型比较 | Boolean.compareTo(Boolean other) |
| 字符串型(String) | 字典序比较 | String.compareTo(String other) |
| 字节型(Binary) | 字典序比较 | 可参考: UnsignedBytes.lexicographicalComparator |
举个简单的例子,假设一个表有3列主键列,分别是:整型、字符串型和整型:
- (10, 'abc', 10) == (10, 'abc', 10) 所有主键列均相等
- (10, 'abc', 10) < (11, 'abc', 10) 第一列主键列比较出大小
- (10, 'abc', 0) > (10, 'bbc', 10) 第一列主键列相等,第二列主键列比较出大小,即使第三列主键列也不同。
单行查询
单行查询必须指定行的主键,根据上一章描述的比较规则,在表格存储内部查找到相同主键的行,并根据指定的查询条件,返回整行或者部分列。
范围查询
范围查询必须指定两个主键,一个作为范围的起始(包含),一个作为范围的终止(不包含)。在表格存储内部,会根据上面章节提到的主键的比较规则,返回大于等于起始主键且小于终止主键的所有的行。
范围查询误区
这里必须注重提到的一点,很多用户对范围查询有一个误解,认为范围查询等于条件查询,举个例子:
假设表有三个主键: [PK1(INTEGER), PK2(STRING), PK3(INTEGER)]
给定的查询范围为:
起始主键:[PK1 = 10, PK2 = 'h', PK3 = 5]
终止主键:[PK1 = 15, PK2 = 'z', PK3 = 9]
很多用户会将这个查询条件误解为:
10 <= PK1 < 15 and 'h' <= PK2 < 'z' and 5 <= PK3 < 9
而正确的理解应该是:
起始主键 <= 行主键 < 终止主键
为更好的理解以上的误解,我们拿实际的数据来解释这个问题,假设一张表的数据如下:
| 行号 | PK1 | PK2 | PK3 |
|---|---|---|---|
| 1 | 10 | 'a' | 0 |
| 2 | 11 | 'a' | 0 |
| 3 | 11 | 'b' | 0 |
| 4 | 12 | 'a' | 0 |
| 5 | 12 | 'c' | 0 |
| 6 | 15 | 'z' | 10 |
| 7 | 16 | 'a' | 0 |
| 8 | 16 | 'a' | 1 |
如果理解为10 <= PK1 < 15 and 'h' <= PK2 < 'z' and 5 <= PK3 < 9这个查询条件,我们应该查不出任何数据出来,因为表中的数据没有一行是满足条件的。
但是实际的情况却是会返回行:2、3、4和5。
这是为什么呢?看下表就明白了。
| 行号 | PK1 | PK2 | PK3 |
|---|---|---|---|
| 1 | 10 | 'a' | 0 |
起始主键 |
10 |
'h' |
5 |
| 2 | 11 | 'a' | 0 |
| 3 | 11 | 'b' | 0 |
| 4 | 12 | 'a' | 0 |
| 5 | 12 | 'c' | 0 |
终止主键 |
15 |
'z' |
9 |
| 6 | 15 | 'z' | 10 |
| 7 | 16 | 'a' | 0 |
| 8 | 16 | 'a' | 1 |
在表格存储内部,会把范围查询给定的起始主键和终止主键根据比较规则定位到行,在这个例子中,起始主键处于第一行和第二行中间,而终止主键位于第五行和第六行中间。范围查询会返回这个范围内的所有行,而这个范围内的行就包括2、3、4和5行。
高级查询
通过上一章的讲述,我们知道表格存储只提供单行查询和范围查询这两个简单的查询功能,也明白了范围查询不等于条件查询。而在很多业务场景下,简单的单行和范围查询并不能满足业务的需求。
所以本章我会再讲述下表格存储如何支持一些复杂的查询场景。
条件过滤
我们提供的范围查询不等于条件查询,但是在电商、社交等业务场景,在场景上需要的是条件查询。
在我们提供条件过滤之前,一般的做法是先范围查询出所有可能满足条件的行,然后在业务服务端根据条件进行筛选。这种方法的坏处是,服务端会返回大量的无用数据,浪费了网络带宽。
针对这个问题,表格存储推出了Relation Filter,支持在服务端对读出的数据做过滤,只将过滤后的结果返回给客户端。
但是要注意的是,虽然范围查询加上条件过滤,客户端拿到的数据少了,但是服务端扫描的数据并没有少。这与传统关系型数据库有点不同,传统关系型数据库的条件查询可以用索引来优化,减少查询的数据量。由于表格存储没有提供索引,所以没法做这个优化。带来的缺点是,如果需要进行条件过滤的查询范围过大,则查询会非常慢,所以不建议通过条件过滤在一个很大的范围内查询数据,非常不高效以及不经济。
条件过滤适用于一些比较灵活的查询场景,例如根据某些动态属性列的条件来做过滤,且过滤的范围都是比较小的业务场景。
多维度查询
上面提到的条件过滤,能满足的场景也是受限的。例如如果查询的结果需要扫描整张表才能拿到,那显然这种做法就不可接受。
举个简单的例子,有一个业务场景,使用OTS存储『用户对文章的点赞』,表结构设计如下:
| PK1 | PK2 | PK2 |
|---|---|---|
| 用户ID | 时间戳 | 文章ID |
通过这张表,可以支持以下几种查询方式:
- 查询某个用户所有的点赞的文章
- 查询某个用户最近一段时间的点赞的文章
但是当我们有了一个新的需求,例如想要看某篇文章被哪些用户点过赞,基于这张表可以怎么实现呢?最土的方式就是,范围查询整张表,过滤出特定文章ID的所有行。这种方案有个非常大的问题,就是它必须扫全表,效率上是完全无法接受的。
针对此种场景,我们推荐的做法是,再建另外一张表,结构如下:
| PK1 | PK2 | PK2 |
|---|---|---|
| 文章ID | 时间戳 | 用户ID |
通过这张表,就能满足以下几种查询方式:
- 查询某个文章的所有点赞的用户
- 查询某个文章最近一段时间的点赞的用户
以上是最简单的基于表格存储做多维度查询的一个解决方案,当然也有其局限性:
- 查询方式必须预定义,根据查询条件来决定构建哪几张表,查询模式无法灵活变动
- 一笔数据需要同时写入多张表,多张表之间的数据一致性需要应用自己保证,所以只适用于接受最终一致或者允许不一致的业务场景
支持多维度查询,还可通过组合使用表格存储和其它服务来解决,例如表格存储加ElasticSearch,通过表格存储来保存数据主题,ElasticSearch来做索引。这又是另外一个话题了,不在这里赘述,感兴趣的可以留言交流。
总结
表格存储的数据模型非常简单,理解透之后,也就可以非常简单的理解表格存储当前提供的几种查询方式。
表结构设计是相对灵活的,需要根据不同的业务场景来设计,设计时需要考虑查询的效率。
表格存储无法支撑所有的查询场景,在使用时必须有一些取舍。
有任何表结构设计的咨询需求,欢迎一起交流!