1. 背景
一年半以前,AlphaGo完胜李世乭的围棋赛让深度学习(Deep Learning)这个名词家喻户晓,再度掀起人工智能的新一波热潮。其实深度学习背后的神经网络基础理论早在上世纪50年代就已提出,经过几起几落的发展,到了21世纪初,多层神经网络算法也日趋成熟。深度学习理论早在十多年以前就有重要突破,为何直到近年才出现爆发。这不得不提到2012年的一场竞赛。
2012年,Geoffrey E. Hinton(与Yann LeCun 和Yoshua Bengio并称为深度学习三驾马车)的弟子Alex Krizhevsky在ILSVRC-2012的图像分类比赛中使用2块Nvidia GTX 580 GPU训练的多层神经网络(后来被称为AlexNet)以15.3%的top-5测试错误率摘得冠军,而使用传统方法的第二名的成绩是26.2%,整整提高了10多个百分点。这也成为了深度学习发展史上的里程碑事件,从此深度神经网络一炮走红,此后ILSVRC的优胜者一直被深度神经网络霸占。
可以说深度学习爆发有两个主要原因,一个是像ImageNet这样的大规模数据集的出现,而另一个重要原因就是计算能力的提高,而这主要得益于GPU用于深度学习的加速,尤其是深度学习训练的加速。
Alex当时使用的数据集包含120万张高清图片,受限于单块GTX 580 GPU 3GB的内存,他们使用了2块GPU来训练他们包含6000万参数和65万神经节点的网络,当时花了5~6天的时间。可以想象,没有GPU的加速,要完成如此大规模的数据集的多层神经网络训练要花费多长的时间。
随着深度网络层数的增加,训练集动辄以T为单位计算,现在深度学习的训练已经离不开GPU了,而GPU的计算能力也在不断的提升,以满足深度学习训练的计算需求。
2. 实测
下面是我们使用主流的几个开源深度学习框架在NVIDIA GPU上做的一些深度学习的测试。其中P100和P4的数据均来自于阿里云GPU云服务器新GPU实例的内部测试数据,仅供参考,实际数据请以线上正式环境为准。
2.1 NVCaffe
NVCaffe是NVIDIA基于BVLC-Caffe针对NVIDIA GPU尤其是多GPU加速优化的开源深度学习框架。
我们使用NVCaffe对AlexNet、GoogLeNet、ResNet50三种经典卷积神经网络在单机8卡P100服务器上做了训练测试。测试使用ImageNet ILSVRC2012数据集,,其中训练图片1281167张, 验证测试图片 5万张,LMDB格式train set 240GB ,val set 9.4GB,数据单位是Images/Second(每秒处理的图像张数),OOM表示Batch Size太大导致GPU显存不够。
下面是给出物理机上GoogLeNet的数据:
从测试数据我们看到,相同GPU数量,随着Batch Size的增大,训练性能会有明显的提升,相同Batch Size,在GPU Memory基本用满的情况下,随着GPU数量的增加,训练性能也会有明显的提升,GPU加速可以接近线性加速。高密GPU服务器可以接近线性加速,对于大数据集的训练提速非常明显。
我们还对比了不同卷积神经网络模型的多GPU加速比,结果如下: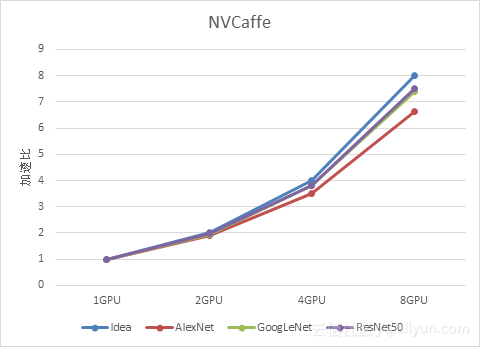
可以看到,不同神经网络模型的GPU加速也是有差别的,AlexNet的多GPU加速效果就不如GoogLeNet和ResNet50好。
2.2 MXNet
相比Caffe,MXNet是一个更加简洁灵活效率高的开源深度学习框架,它配置简单,依赖少,尤其是具有很好的多GPU加速扩展性。
我们使用Benchmark模式测试ImageNet训练,使用网络Inception-v3(GoogLeNet的升级版)在单机8卡P100服务器上进行测试,物理机加速比如下: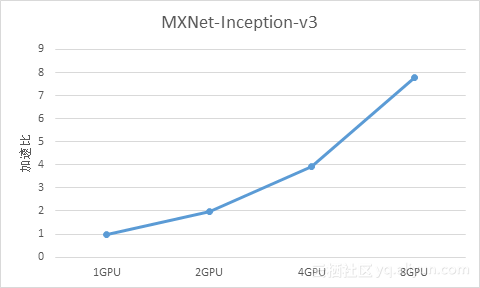
可以看到,MXNet也具有非常好的GPU线性加速扩展能力。
下面是P100虚拟机与AWS P2.16xlarge实例的对比,单位是samples/sec,越大性能越好: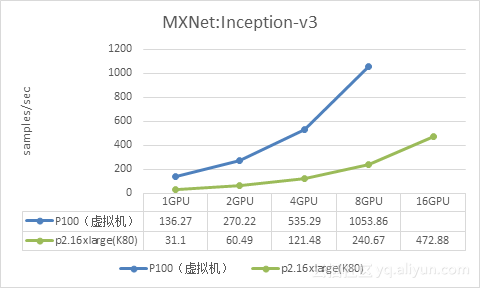
2.3 TensorFlow
TensorFlow得益于背后Google的支持,是活跃度最高的开源深度学习框架。
我们使用CIFAR-10数据集在P100上做了多GPU加速训练测试,物理机加速比如下: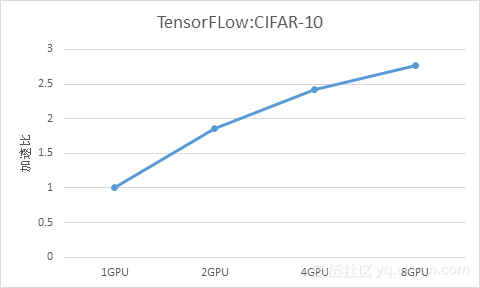
可以看到,TensorFlow的单机多卡加速能力是非常差的,尤其是超过2卡以后,跟NVCaffe和MXNet有较大的差距。
此外,我们使用AlexNet Benchmark模式对不同架构单GPU 做了Forward和Forward-backward性能测试作为比较参考,包括新的Pascal架构的Tesla P100、P4和老的Kepler架构的K80(其中K80数据来源于AWS P2.16xlarge实例,对比的P100也是虚拟机的数据),数据单位sec/ batch,值越小性能越好: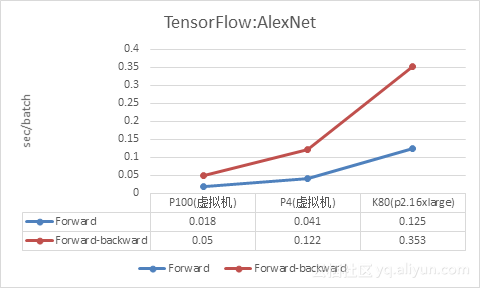
通过K80与P100、P4的对比,可以看到Pascal架构的GPU(P100、P4)比Kepler架构的GPU(K80)有非常明显的性能提升。其中特别一提的是P4因为较低的TDP(75W),具备非常好的性能功耗比,非常适合作为推理的加速。
3. 总结
1) 为了缩短训练时间,尽可能选择新架构的GPU,比如Pascal架构的P100,并利用GPU适合并行计算的特点使用多GPU来加速训练。但是注意,并不是所有的深度学习框架都有好的单机多卡加速,比如开源的TensorFlow就不好,我们建议用户使用比如MXNet或者NVCaffe这样的学习框架用于单机多卡加速。
2) Batch Size的增大对于训练的性能有明显的提升,因此应尽可能选择GPU Memory大的GPU,比如P100的GPU Memory可以达到16GB。
3) 不同深度神经网络的实现差异,会导致多GPU加速比的差异,在设计或者优化神经网络模型的时候,需要注意如何更好的利用GPU的并行计算能力,比如减小GPU之间的通信开销以提高GPU并行计算的效率。
GPU加速深度学习
时间: 2025-01-01 13:14:48
GPU加速深度学习的相关文章
浪潮胡雷钧: KNL+FPGA是加速深度学习的黄金搭档
8月17日,在美国旧金山举行的英特尔信息技术峰会(Intel Developer Forum,简称IDF)上,浪潮首席科学家胡雷钧进行了先进技术报告演讲,他结合当前深度学习应用特点和先进计算技术架构进行分析,认为KNL+FPGA是加速深度学习的黄金搭档. 深度学习在人脸识别.语音识别.精准医疗以及无人驾驶等领域被广泛的应用,近年来在高性能计算技术的支持下,其发展十分迅速.然而,深度学习的发展也面临着众多困境,如深度学习软件扩展性不够高.计算性能不够高.深度学习线上识别能耗大等问题. 在多年的
微软发布升级版认知工具包,加速深度学习研发
微软正式发布了 2.0 版本的认知工具包(Microsoft Cognitive Toolkit,曾用名为 CNTK),该工具包曾在微软内部被广泛使用,帮助实现了人工智能领域多个突破. 该升级版本增加了对神经网络库 Keras 的支持,为 Keras 编写的代码现在可以直接利用认知工具包所提供的性能和速度,而无需对代码本身进行任何更改.此外还支持 NVIDIA 最新版本的深度学习 SDK 以及高级图形处理单元(GPU)架构(例如NVIDIA Volta),可以加速训练进程.以及用于模型评估的 J
NVIDIA令深度学习训练性能翻一番
NVIDIA发布了其 GPU 加速深度学习软件的更新版本,这些软件将令深度学习训练的性能翻一番. 新软件将让数据科学家和研究人员能够通过更快的模型训练和更复杂的模型设计来创造更准确的神经网络,从而加速其深度学习项目和产品的开发工作. NVIDIA DIGITS 深度学习 GPU 训练系统第 2 版 (DIGITS 2) 和 NVIDIA CUDA 深度神经网络库第 3 版 (cuDNN 3) 可提供大幅提升的性能和全新的功能. 对数据科学家来说,DIGITS 2 现在能够在多颗高性能 GPU
玩深度学习选哪块英伟达 GPU?有性价比排名还不够!
与"传统" AI 算法相比,深度学习(DL)的计算性能要求,可以说完全在另一个量级上. 而 GPU 的选择,会在根本上决定你的深度学习体验.那么,对于一名 DL 开发者,应该怎么选择合适的 GPU 呢?这篇文章将深入讨论这个问题,聊聊有无必要入手英特尔协处理器 Xeon Phi,并将各主流显卡的性能.性价比制成一目了然的对比图,供大家参考. 先来谈谈选择 GPU 对研究深度学习的意义.更快的 GPU,能帮助新人更快地积累实践经验.更快地掌握技术要领,并把这些应用于新的任务.没有快速的反
阿里云异构计算平台——加速AI深度学习创新
云栖TechDay第36期,阿里云高级产品专家霁荣带来"阿里云异构计算平台--加速AI深度学习创新"的演讲.本文主要从深度学习催生强大计算力需求开始谈起,包括GPU的适用场景,进而引出了弹性GPU服务--EGS(Elastic GPU Service),重点讲解了EGS的优势.EGS监控以及EGS产品家族,最后对EGS支撑AI智能创新进行了总结.以下是精彩内容整理: 基于大数据的深度学习催生强大计算力需求 怎样加速AI深度学习支撑,帮助大家搭建模型,支撑大家业务运营等等. 如图,深
NVIDIA GPU 为 Facebook 的新型深度学习机器提供处理动力
NVIDIA 近日宣布,Facebook 将在其下一代计算系统中采用 NVIDIA Tesla加速计算平台,从而使该系统能够运行各种各样的机器学习应用. 即便在最快的计算机上,训练复杂的深度神经网络以进行机器学习也需要花费数日或数周的时间,然而 Tesla 平台可将这一耗时缩短 10-20 倍.如此一来,开发者便能够更快地进行创新和训练更复杂的网络,从而为消费者提供更完善的功能. Facebook 是首家利用 NVIDIA Tesla M40 GPU 加速器来训练深度神经网络的企业,该加速器已于
深度学习训练,选择P100就对了
1.背景 去年4月,NVIDIA推出了Tesla P100加速卡,速度是NVIDIA之前高端系统的12倍.同年9月的GTC China 2016大会,NVIDIA又发布了Tesla P4.P40两款深度学习芯片.Tesla P100主攻学习和训练任务,而Tesla P4&P40主要负责图像.文字和语音识别. 同为Pascal架构且运算能力接近的P100和P40常常被拿来对比,单看Spec上运算能力,似乎P40比P100的深度学习性能更好,但实际上呢?本文就通过使用NVCaffe.MXNet.Te
手把手教你安装深度学习软件环境(附代码)
为了进行强化学习研究,我最近购置了一台基于 Ubuntu 和英伟达 GPU 的深度学习机器.尽管目前在网络中能找到一些环境部署指南,但目前仍然没有全面的安装说明.另外,我也不得不阅读了很多文档来试图理解安装细节--其中的一些并不完整,甚至包含语法错误.因此,本文试图解决这个问题,提供一个详尽的软件环境安装指南. 本文将指导你安装 操作系统(Ubuntu) 4 种驱动和库(GPU 驱动.CUDA.cuDNN 和 pip) 5 种 Python 深度学习库(TensorFlow.Theano.CNT
30个深度学习库:按Python和C++等10种语言分类
本文介绍了包括 Python.Java.Haskell等在内的一系列编程语言的深度学习库. 一.Python 1.Theano 是一种用于使用数列来定义和评估数学表达的 Python 库.它可以让 Python 中深度学习算法的编写更为简单.很多其他的库是以 Theano 为基础开发的: Keras 是类似 Torch 的一个精简的,高度模块化的神经网络库.Theano 在底层帮助其优化 CPU 和 GPU 运行中的张量操作. Pylearn2 是一个引用大量如随机梯度(Stochastic G