列数据库存储技术
这个slide:VLDB 2009 Tutorial on Column-Stores将列数据库相关的技术keyword都列举出来了:storage && compression、query execution engine、CPU、Memory。
本文就是对 compression 这个点的相关技术的收集:
行存储的数据库多采用稠密索引,如果数据库文件中的数据不是按照关键字的顺序排列(例如按照大小、时间前后),需要对为每一行数据基于此关键字创建一个索引项。会导致:
1 增加存储空间
2 增加数据更新时的代价。
因此基于行存储的RDBMS系统为表中的所有列创建索引是不现实的,所以如果一个查询sql的查询条件是基于一个没有索引的列,则数据库必须做全表扫描,数据量大的情况下响应效率不高。
列存储可以为所有列创建稀疏索引,每个列的值被压缩算法压缩之后顺序存储到数据块中,索引只需建立到数据块上,索引的存储空间小,而且更新维护的代码也小。也就说将行存储中的行级索引更新为列存储的数据块索引(列数据库主要面向OLAP场景,查询SQL多为聚合类型,每次查询的数据量很多,硬盘数据的访问加载都是block级别,不像OLTP查询只是少量的几条。这也可以理解为什么HiStore说大数据量下的查询效率高于MySQL,而单条查询却不会高于MySQL)。列存储下,查询语句通过索引定位到某一个数据块,然后使用某种查询算法访问数据块中的顺序数据,避免任何字段的查询导致全表扫描。
优点:
- 数据高压缩率,节省存储空间
- 减少磁盘IO数量,只取所需
- 适合大批量数据的aggregation queries
缺点:
- 空间换时间,数据还原、计算需要CPU资源
存储关键技术
列数据库的按照数据块为单位来存储数据,常见存储的压缩算法有如下几种:
- 游程长度压缩算法(Run-Length Encoding,RLE)
- 词典编码算法(Dictionary Encoding)
- 位向量算法(Bit-Vector Encoding)
游程长度压缩算法
RLE(介绍) 算法是一个无损压缩算法(无损数据压缩算法的历史),核心思想是将一个序列连续重复出现N此的元素(元素组)转化为一个三元组(元素值,序列中第一次出现的位置,出现次数)。例如AAAAABBC,RLE压缩之后是(A,1,5),(B,6,2),(C,8,1),so问题来了,如果是ABCABCABC类型的数据奈若何呢?AABCDEEF这种基数类型大的数据又如何呢?
这里有相应的解决方案介绍:算法系列之八:RLE行程长度压缩算法
更厉害的:
RLE是对连续重复的数据进行压缩处理的---这个在图片、视频、音频领域都都适用,LZ77是对不连续重复的数据进行压缩处理的(也就是下面的词典编码算法). 在字符串匹配场景中,LZ77的压缩率会比RLE要高,LZ77用于ZIP压缩:ZIP压缩算法详细分析及解压实例解释,RLE + Huffman(Deflate/Inflate)。
词典编码算法
词典编码算法通过“原始值-替代值”的映射词典,将数据中”原始值“替换为更为简短的“替代值”。具体的实现算法分2种:
第一种是查找正在压缩的字符序列是否在以前输入的数据中出现过,然后用已经出现过的字符串替代重复的部分,它的输出仅仅是指向早期出现过的字符串的“指针”。例如:LZ77以及改良版LZ78、LZSS算法。
借用别人ppt中的图片,️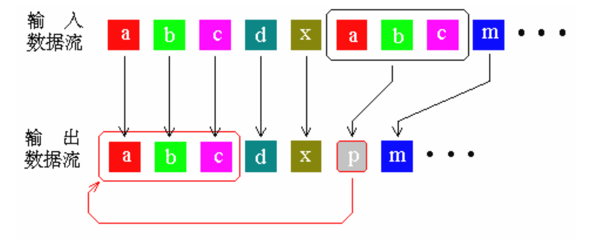
LZ77算法包括一个(sliding window滑动窗口,大概是一个容量可变的存储器)和一个预读缓存器(read ahead buffer)。sliding window是由0-64K的input stream,LZSS是用4K的sliding window.sliding window后面的字节填充预读缓存器,预读缓存器的大小通常在0-258K,与sliding window对应的.
LZ77就是处理sliding window和预读缓存器的匹配,如果这个匹配的长度大于最小匹配长度(最小匹配长度取决于编码器,通常取决于sliding window的长度。比如一个4K的sliding window,最小匹配长度为2),然后输出一个,长度(length)是这个匹配的长度,距离(distance)是在向前多少字节的地方匹配的。
第二种是基于源数据中创建一个“短语词典(dictionary of the phrases)”,短语可以是任意字符的组合。算法在编码数据过程中遇到已经在词典中出现的“短语”时,就将原始值替换为这个词典中的短语的“替换值”。典型代表是:LZW,LZW算法的专利是美国Unisys所有,非商业软件公司可以免费试用LZW。
再次借用别人ppt中的图片,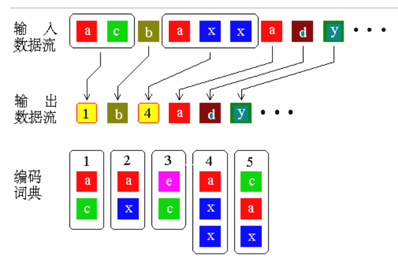
位向量编码算法
这个听着高大上的算法其实就是位图索引算法,适用于低基数的列,相对于B树索引,它的count,and,or操作更有效,位图索引位存放的是0,1的bit,相对于B树索引,占字节数特别少,不适合update、insert、delete频繁的列-因为要一个数据的更新可能会导致2个位图向量的更新(分段位图索引 Multi Components Bitmap Index)。
如果数据基数大,创建的位图索引会越来越多,空间占用也会很大,所以,位图索引 + RLE 可以算作天作之合,例如:
| id | 年龄 | 消费 |
|---|---|---|
| 1 | 25 | 60 |
| 2 | 45 | 60 |
| 3 | 50 | 75 |
| 4 | 50 | 100 |
| 5 | 50 | 120 |
| 6 | 70 | 110 |
| 7 | 85 | 140 |
| 8 | 30 | 260 |
| 9 | 25 | 350 |
| 10 | 45 | 270 |
| 11 | 50 | 260 |
| 12 | 60 | 400 |
对年龄和消费创建位图索引。
对于“年龄”字段有7个值,位图索引有7个向量:
25: 100000001000
30: 000000010000
45: 010000000100
50: 001110000010
60: 000000000001
70: 000001000000
85: 000000100000
查询所有年龄在[30,55]之间用户的消费数据:
30: 000000010000 and 45: 010000000100 and 60: 000000000001
在这个例子下年龄是稀疏字段,除非有龟鹤延年的人,正常数据范围是1-100,假设有天地同寿的仙人消费记录,随着年龄的数据增多,向量个数增多,占用的空间也会增多,这时应该召唤压缩算法:RLE。
算法思想:
就是将1前面的N个0用少量的二进制数字记录。
算法规则:
- n是向量中某个1之前0的个数
- e是n的二进制格式下的数据
- m是e的长度,如果n=0,m=0;n=1,m=0
- t是(m-1)个'1'和1个'0'组成的字符串,如果n=0,t='0';n=1,t='0'
例如:
示例1:
字符串:00000000000001,不用数了,1之前真的是13个0,n=4,13=0b1101,e=1101,m=3,t=1110,压缩之后的字符串为:11101101
示例2:
字符串:0,压缩:00
示例3:
字符串:1,压缩:01
示例4:
字符串:1100000010000000001,切分为4组字符串:[1,1,0000001,0000000001],对应的压缩组:[00,00,110110,11101001],最终的字符串:000011011011101001
这里有更详细、更多的位图压缩算法:位图索引算法
参考:java bitmap/bitvector的分析和应用
结束
这个只是存储相关的,执行过程的优化和cpu cache line黑科技的应用都有待挖掘、总结~~~