日志服务(原SLS)是针对大规模日志实时存储与查询服务,半年内我们逐步提供文本、数值、模糊、上下文等查询能力。在五月份版本中日志服务提供 SQL 实时统计分析功能 ,能够在秒级查询的基础上支持实时统计分析。
支持SQL包括:聚合、Group By(包括Cube、Rollup)、Having、排序、字符串、日期、数值操作,以及统计和科学计算等(参见分析语法)。
如何使用?
例如,对访问日志(access-log)查询 “状态码=500,Latency>5000 us,请求方法为Post开头”所有日志:
Status:500 and Latency>5000 and Method:Post*
在查询后增加管道操作符”|“,以及SQL后(不需要from 和 where,既从当前Logstore查询,where条件在管道前):
Status:500 and Latency>5000 and Method:Post | select count() as c , avg(Latency) as latency_avg, sum(Inflow) as sum_inflow, ProjectName Group by ProjectName order by c Desc limit 10
可以在控制台上获得结果(包括一些基本图表帮助理解):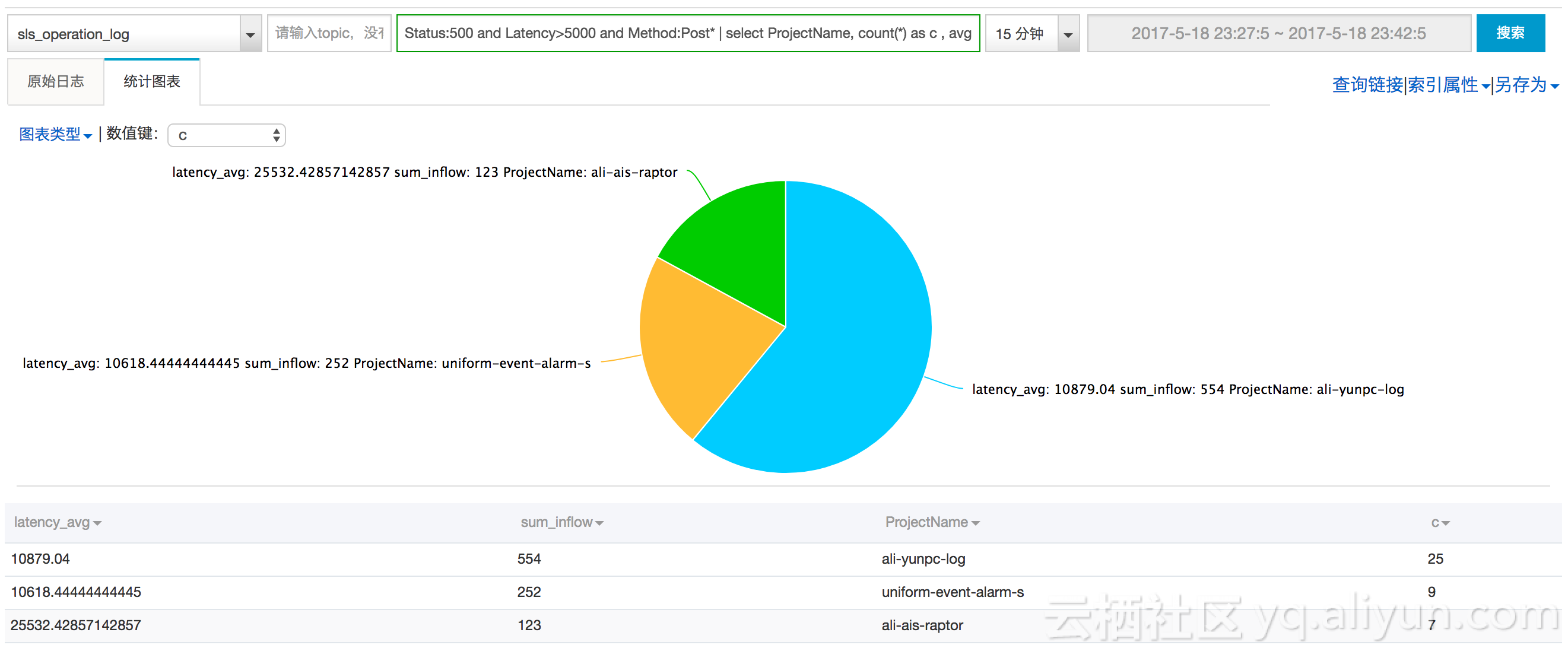
为了获得更好体验,我们对SQL执行数据量做了限制(参考SQL分析语法最后部分)。在机房扩容后和下一步优化后(大约2个月),我们会放开该限制,敬请期待。
案例(线上日志实时分析)
在几百台机器、十几个应用程序、面向万级用户定位问题是非常有挑战的,需要在多维度及条件变量进行实时排查。例如在网络攻击中,攻击者会不断地变化来源IP、目标等,让我们无法实时做出反应。
这类场景不光需要海量处理能力,还需要非常实时的手段,SLS+LogHub可以确保日志从服务器产生到被查询在3秒以内(99.9%情况),让你永远快人一步。
例如在监控发现线上有非200的访问错误产生,一般老司机的调查方法如下:
- 该错误影响了多少用户? 是个体,还是全局
Status in (200 500] | Select count(*) as c, ProjectName group by ProjectName - 确定大部分都是从Project为“abc”下引起的,究竟是哪个方法触发的?
Status in (200 500] and ProjectName:"abc"| Select count(*) as c, Method Group by Method - 我们可以获取到,都是写请求(Post开头)触发,我们可以将查询范围缩小,调查写请求的延时分布
Status in (200 500] and ProjectName:"abc" and Method:Post* | select numeric_histogram(10,latency) - 我们可以看到,写请求中有非常高的延时。那问题变成了,这些高延时是如何产生的
- 通过时序分析,这些高请求延时是否在某个时间点上分布,可以进行一个时间维度的划分
Status in (200 500] and ProjectName:"abc" and Method:Post* |select from_unixtime( time - time % 60) as t, truncate (avg(latency) ) , current_date group by time - time % 60 order by t desc limit 60 - 通过机器Ip来源看,是否分布在某些机器上
Status in (200 500] and ProjectName:"abc" and Method:Post and Latency>150000 | select count() as c, ClientIp Group by ClientIp order by c desc
- 通过时序分析,这些高请求延时是否在某个时间点上分布,可以进行一个时间维度的划分
- 最终大致定位到了延时高的机器,找到RequestId,可以顺着RequestId继续在SLS中进行查询与搜索
- 这些操作都可以在控制台/API 上完成,整个过程基本是分钟级别
什么场景适合使用SLS?
和数据仓库、流计算等分析引擎相比,有如下特点:
- 针对结构化、半结构化数据
- 对实时性、查询延时有较高要求
- 数据量大,查询结果集合相对较小
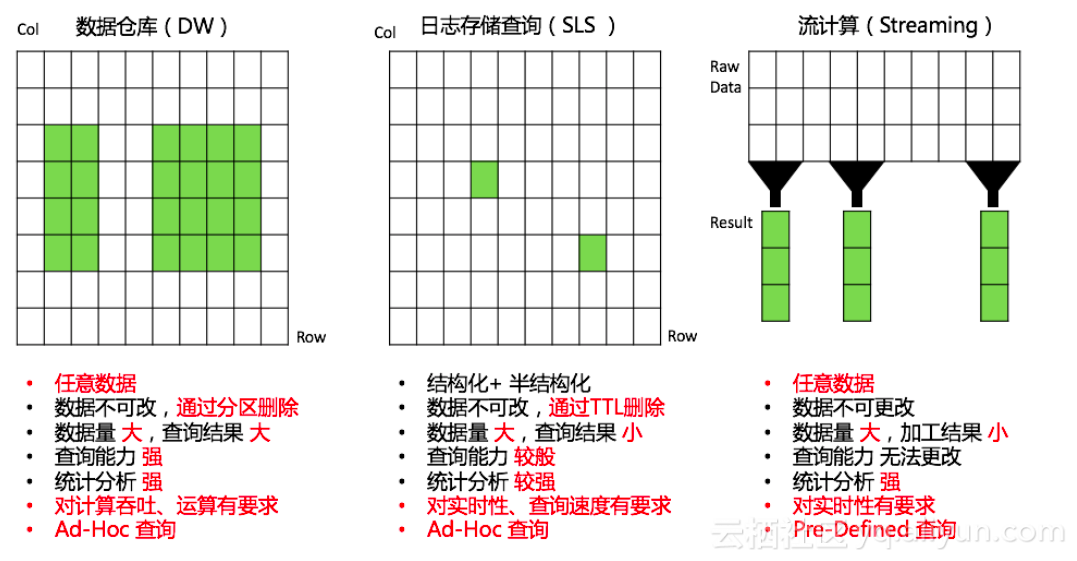
除此之外SLS与 MaxCompute、OSS(E-MapReduce、Hive、Presto)、TableStore、流计算(Spark Streaming、Stream Compute)、Cloud Monitor等已打通,可以方便地将日志数据以最舒服姿势进行处理。
更多的内容请关注产品主页,欢迎关注存储服务公众,也欢迎加入VIP钉钉群。
{kind=link}