1.11 apply原理
apply函数以一个数组、一个矩阵或一个数据框作为输入,返回一个数组格式的结果。计算或运算由用户的自定义函数或内置函数定义。margin参数用于指定函数要作用于哪条边以及要保留哪条边。如果使用的数组是一个矩阵,那么可以指定margin是1(将函数应用于行)或2(将函数应用于列)。函数可以是任意用户自定义函数或内置函数,比如mean、median、standard deviation、variance等。这里我们将用Artpiece数据集来执行这个任务:

lapply函数在处理数据框(应用任何函数)时很有用。在R语言中,数据框被当作一个列表,数据框中的变量就是列表中的元素。因此,我们可以利用lapply将一个函数应用到一个数据框中的所有变量上,示例如下:

sapply函数适用于一个列表中的元素,返回的结果是一个向量、矩阵或者列表。当参数是simplify=F时,sapply函数会像lapply函数那样返回一个列表;反之,当参数是simplify=T,即默认参数时,sapply会以简化的格式返回结果:

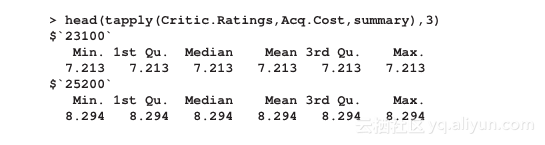
有时我们想将一个函数应用到一个向量的子集,这些子集通常由其他向量定义(通常是一个因子)。tapply函数输出的是一个矩阵/数组,矩阵/数组中的每个元素是向量的g分组上f的值,g分组作用于行/列名上:

apply函数族还包含其他一些函数,例如:
- eapply:将一个函数应用于一个环境中的变量。
- mapply:将一个函数应用于多个列表或多个向量参数。
- sapply:递归地将一个函数应用于一个列表。
时间: 2024-10-30 19:19:56