2.4 基于规则的日志流分析
任何合理的日志管理系统都需要具备以下特性:
(1)过滤无关紧要的日志信息,无须对这类日志进行统计和排序。这类日志常常包含INFO或DEBUG等级的日志记录(没错,产品系统中也会包含这些信息 )。
(2)深入分析日志记录并提取更多有价值的信息和新的字段。
(3)在保存日志之前增改日志记录。
(4)当收到特定日志记录时发送通知信息。
(5)通过关联日志事件来获取有价值的信息。
(6)应对日志结构和格式的变更。
本节在Bolt中集成了JBoss库和Drools,以便于我们通过声明和清晰的方式,轻松实现上面列举出的这些目标。Drools是一个基于正向推理的规则引擎的开源实现,它可以推断新的值并根据匹配逻辑执行相关逻辑操作。你可以在这个网站上找到Drools项目的更多信息:http://www.jboss.org/drools/。
2.4.1 实战
Step01 使用Eclipse,在storm.cookbook.log包中创建LogRulesBolt类,并继承BaseRichBolt。与LogSpout类一样,LogRulesBolt类会发送一个包含LogEntry实例的值到Topology中。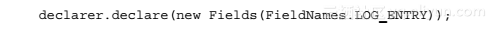
Step02 在StatelessKnowledgeSession类中添加一个私有成员变量kssession,并在Bolt的prepare方法中对其进行初始化。
该知识会话只初始化了一组syslog日志规则。建议把规则管理的工作交给Drools Guvnor或者类似的软件,然后通过代理来获取有关规则资源。这个主题已经超出了本书的讨论范围,更多信息可以参考以下链接:http://www.jboss.org/drools/drools-guvnor.html。
Step03 在Bolt的execute方法中实现这个逻辑:把Tuple中的LogEntry对象传递到知识会话中。
Step04 接着创建规则资源文件,使用文本编辑器或Eclipse插件就可轻松搞定。可以从更新站点http://download.jboss.org/drools/release/5.5.0.Final/org.drools.updatesite/下载到相关Eclipse插件。规则资源文件应该放置在classpath的根目录下。在src/main/resources下创建Syslog.drl,然后右击该目录,依次选择 “Build Path ”→ “Use as source folder”菜单项,将这个目录添加到Eclipse的构建路径中。
Step05 将以下内容添加到规则资源文件中:
2.4.2 解析
Drools支持两种类型的知识会话,分别是有状态(stateful)会话和无状态(stateless)会话。在这个例子中,我们只需要一个无状态会话就足够了。
在我们使用有状态会话的时候,需要时刻注意其可能导致的性能问题。有状态会话主要是维持工作会话中内存的“事实”(fact),这在有些用例中十分重要。但需要了解的是,Drools所使用的正向推理Rete算法引擎的性能还是会随着知识库中“事实”的增加而呈指数级下降。
知识会话根据已知的一组规则来评估事实。Bolt的prepare方法中定义了这一系列操作,并在该方法中指定了相关规则。在Bolt执行过程中,通过如下调用从Tuple中提取LogEntry并将其传递到知识会话中:
在执行过程中会把知识会话当做一条记录进行处理,而且该记录在每次调用结束时有可能改变。LogEntry对象中包含一个名为filter的控制字段,如果将这个字段设置为true,那么这条日志记录将被丢弃。实现方法是:在规则执行后,发送包含记录的Tuple之前,检查这个字段。
在规则资源文件中,定义了三个规则:
(1)Host Correction
(2)Filter By Type
(3)Extract Fields
这些规则只是为了我们演示一些基本概念而设计的,所以在产品中可能并没有什么用。Host Correction规则会尝试纠正主机名以使其符合要求。该规则会在满足匹配标准时自动将结果显示出来。该规则的when子句将LogEntry实例的sourceHost字段与localhost做匹配操作,当满足条件时触发相关动作。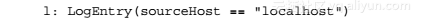
这个条件子句也会在规则允许的范围内把满足条件的实例赋给局部变量l。then子句是一段传统的 Java 代码(POJO),它会在编译后的运行时添加到当前classpath中。这些规则能让localhost值满足我们的需求。
Filter By Type规则会将所有非syslog类型日志记录的filter字段设置成true。
Extract Fields规则更加有趣。首先,它所包含的salience命令可以确保其在最后才被执行。这样就可以避免它从已过滤的日志中提取字段。借助于正则表达式匹配,该规则可以从日志文件中提取更多的字段和结构。虽说有关正则表达式的内容超出了本书的讨论范围,但有不少总结得很好文档可供我们参考。
考虑到介绍的完整性,我们在这里罗列了一些有助于删选日志记录的正则表达式示例:
匹配日期:((?<=>))\w+\x20\d+
匹配时间:((?<=\d\x20))\d+:\d+:\d+
匹配IP地址:((?<=[,]))(\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3})
匹配协议:((?<=[\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}]\s))+\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}
可以在维基百科中找到更多有关正则表达式的内容:
http://en.wikipedia.org/wiki/Regular_expression
这些附加字段可以被添加到字段或者标签当中,我们会在稍后的分析、搜索和分组操作中使用这些字段。
Drools中还有一个叫做Drools Fusion的模块,用于支持复杂事件处理(CEP)。CEP常常被视为一个新的企业级方法,这么讲不为过,但实际上就是指让规则引擎能够在与时间相关的情况下进行正常的处理。它可以根据时间来关联事件,然后导出新的知识或触发相关动作。在本节的Bolt实现中就有时序算子的身影。欲了解更多的信息,可以浏览以下链接:
http://www.jboss.org/drools/drools-fusion.html