3.1.1 XML文档的结构
XML文档应当以一个文档头开始,例如:
严格来说,文档头是可选的,但是强烈推荐你使用文档头。
注意:因为建立SGML是为了处理真正的文档,因此XML文件被称为文档,尽管许多XML文件是用来描述通常不被称作文档的数据集的。
文档头之后通常是文档类型定义(Document Type Def?inition,DTD),例如:
文档类型定义是确保文档正确的一个重要机制,但是它不是必需的。我们将在本章的后面讨论这个问题。
最后,XML文档的正文包含根元素,根元素包含其他元素。例如:
元素可以有子元素(child element)、文本或两者皆有。在上述例子中,font元素有两个子元素,它们是name和size。name元素包含文本“Helvetica”。
提示:在设计XML文档结构时,最好让元素要么包含子元素,要么包含文本。换句话说,你应该避免下面的情况:
在XML规范中,这叫做混合式内容(mixed content)。在本章中,稍后你将会看到,如果避免了混合式内容,就可以简化解析过程。
XML元素可以包含属性,例如: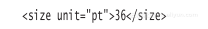
何时用元素,何时用属性,在XML设计人员中存在一些分歧。例如,将font做如下描述:
似乎比下面的描述更简单一些:
但是,属性的灵活性要差很多。假设你想把单位添加到size的值中去,如果使用属性,那么就必须把单位添加到属性值中去:
嗨!现在必须对字符串“36 pt”进行解析,而这正是XML被设计用来避免的那种麻烦。而向size元素中添加一个属性看起来会清晰得多:
一条常用的经验法则是,属性只应该用来修改值的解释,而不是用来指定值。如果你发现自己陷入了争论,在纠结于某个设置是否是对某个值的解释所作的修改,那么你就应该对属性说“不”,转而使用元素,许多有用的文档根本就不使用属性。
注意:在HTML中,属性的使用规则很简单:凡是不显示在网页上的都是属性。例如在下面的超链接中:
字符串Java Technology要在网页上显示,但是这个链接的URL并不是显示页面的一部分。然而,这个规则对于大多数XML并不那么管用,因为XML文件中的数据并非像通常意义那样是让人浏览的。
元素和文本是XML文档“主要的支撑要素”,你可能还会遇到的其他一些标记,说明
如下:
