原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 、作者信息和本声明。否则将追究法律责任。http://koumm.blog.51cto.com/703525/1546326
一、基础环境
两台IBM x3650M3,操作系统CentOS5.9 x64 ,连接一台IBM DS3400存储,系统底层采用GFS文件系统实现文件共享,数据库是另一套独立的oracle rac集群,本架构无需考虑数据库的问题。
GFS文件系统及相关配置见上一文IBM x3650M3+GFS+IPMI fence生产环境配置一例。本文是在上一文的基础上进行延伸。 两台服务器主机名分别为node01,node02,因为应用架构相关简单,而且服务器资源有限,通过两台服务器实现双机互备模式高可用性架构。本文出自:http://koumm.blog.51cto.com/
IBM x3650M3+GFS+IPMI fence生产环境配置一例
http://koumm.blog.51cto.com/703525/1544971
架构图如下:
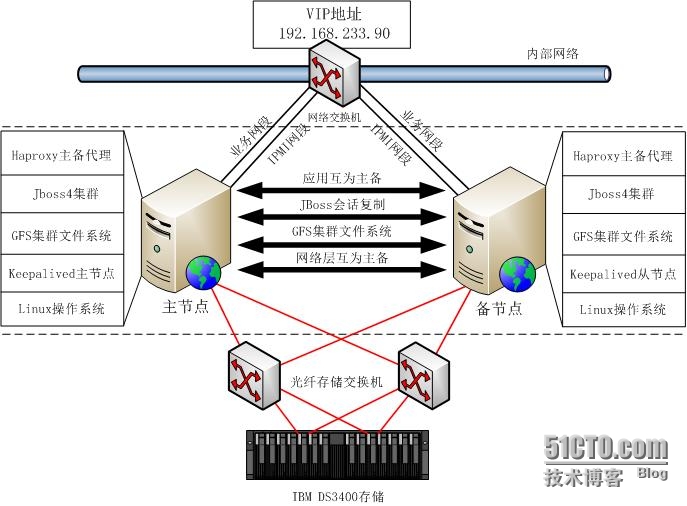
1. 网络环境及IP地址准备, CentOS5.9 x64
1) 节点1主机名: node01
说明:IBM服务器需要将专用IMM2口或标注有SYSTEM MGMT网口接入交换机, 与本地IP地址同段。
ipmi: 10.10.10.85/24
eth1: 192.168.233.83/24
eth1:0 10.10.10.87/24
2) 节点2主机名: node02
ipmi: 10.10.10.86/24
eth1: 192.168.233.84/24
eth1:0 10.10.10.88/24
3) node01, node02 hosts文件配置
# cat /etc/hosts
192.168.233.83 node01
192.168.233.84 node02
192.168.233.90 vip
10.10.10.85 node01_ipmi
10.10.10.86 node02_ipmi
二、双机Keepalived配置
实现一个VIP出现,出例采用VIP地址是192.168.233.90。
1.安装keepalived软件
说明:keepalive-1.2.12经过安装没有问题。
(1) 下载软件包并在node01,node02两个节点上安装
|
1 2 3 4 5 6 7 8 9 |
|
2. 创建keepalived配置文件
1) 在node01 节点一上配置文件
修改配置文件, 绑定的网卡是eth1
说明: 从机就是优先级与本机IP不一样外,其它都是一样。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
|
2) 在node02节点二上配置文件
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
|
3 .在node01,node02两节点上启动与创建keepalived服务
1) 启动服务并加为开机启动:
|
1 2 3 |
|
2) 测试并观察VIP漂移情况
(1) VIP地址观察
主机: 观察VIP地址如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
注:可以关闭keepalived服务,通过cat /var/log/messages观察VIP移动情况。
三、HAproxy反向代理配置
node01, node02配置操作
1. 添加非本机IP邦定支持
|
1 2 3 |
|
2. 安装haproxy软件
|
1 2 3 4 5 6 |
|
3. 安装socat工具
|
1 2 3 4 |
|
4. 创建配置文件
1)node01上创建配置文件
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
|
2)node02上创建配置文件
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
|
说明:两节点互为主备模式,均优化将本机的节点应用做为主节点,也可以为负载均衡模式。
5. node01,node02上配置HAproxy日志文件
1) Haproxy日志配置
|
1 2 3 4 |
|
说明: 第三行是去掉在/var/log/message再记录haproxy.log日志的功能的。
|
1 2 |
|
直接手动执行
|
1 2 3 4 5 |
|
2) haproxy日志切割
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
注:root权限执行脚本。
# crontab -e
59 23 * * * su - root -c '/root/system/cut_log.sh'
6. 配置HAproxy启动服务
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 |
|
(2) node01,node02上创建service服务
|
1 2 3 4 |
|
(3) 测试监控
http://192.168.233.85:91/admin
http://192.168.233.83:91/admin
http://192.168.233.84:91/admin
因为没有应用,代理会出现503报错。
四、Jboss-EAP-4.3集群配置
配置要点:
1)Jboss及java基础环境配置略, Jboss会话复制是本例的重点。
2)Jboss及应用程序代码部署在GFS集群文件系统目录上,两节点能够访问同一个内容。
3)延伸可以部署监控脚本监控jboss应用,如果进程死掉或无法访问,重启应用,本文略过该内容。
1. 添加JBoss会话复制功能
在应用程序中配置会话复制
# vi /cluster/zhzxxt/deploy/app.war/WEB-INF/web.xml
直接在<web-app>下加入一行<distributable/>
|
1 2 3 4 5 |
|
2. 修改集群标识
1)修改集群标识
# vi /cluster/jboss4/server/node01/deploy/jboss-web-cluster.sar/META-INF/jboss-service.xml
# vi /cluster/jboss4/server/node02/deploy/jboss-web-cluster.sar/META-INF/jboss-service.xml
<attribute name="ClusterName">Tomcat-APP-Cluster</attribute>
2)采用TCP方式实现会话复制通讯,注释掉原UDP多播配置文件, 因多播绑定端口到本机最后一个IP地址上,会造成多网段两台服务器绑定IP网段不一样,复制进程无法通讯,改为TCP模式问题解决。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
|
整个架构配置完毕,实际在测试过程中稳定可靠。
本文出自 “koumm的linux技术博客” 博客,请务必保留此出处http://koumm.blog.51cto.com/703525/1546326