3.3 耗时耗力的数据整理过程
数据的整理往往是一个痛苦的耗时耗力的过程,有人曾经以做饭菜来打比方:做过饭菜的人都知道,下油锅炒菜的时间其实并不长,几分钟就够了,而做菜之前的买菜、泡菜(用水浸泡菜去除农药)、洗菜、切菜、配菜等会消耗2~3小时。这和做数据分析很类似,做一个聚类分析,如果选择的模型得当并且电脑运行很快的话,几分钟甚至几秒钟就做完了,但是要把聚类的数据全部收集完毕,很可能要花几天甚至几个月的时间。
数据分析之前的数据整理工作要做哪些事情呢?我们看看以下逻辑。
(1)尽可能保证数据是对的
在错误的数据上分析得出的结论往往是错误的,因此要尽量保证数据的准确性,重复数据以及空行、空列、异常值、不符合逻辑关系的数据都会造成数据质量的降低,要想办法剔除这些数据。至少也要对这些数据有所警醒!
(2)尽可能保证数据能用得上
通常情况下,数据中都会有很多缺失值,面对这种情况,删除肯定是个简单的处理方法,但问题是,这样操作会丢失很多数据和信息。我曾经对某个项目进行测算,如果用“简单粗暴”的方法去删除包含缺失值的数据,那么大概要损失70%左右的数据,这样一来,根据30%左右的数据分析得出来的结论肯定是不准确的。
(3)要保证数据的格式能够直接用于分析
数据有多种组织方式,统计和挖掘中的很多算法模型都需要针对固定格式来做,比如对应分析、关联分析等,因此免不了要做格式转换,有时,为了实现对大数据量的分析,还需要进行编程。
3.3.1 重复、空行、空列数据删除
以案例文件3.1为例,如何对数据进行重复值的排查呢?可综合运用三种方法进行删除,其中,EXCEL提供了两种方法,不过都是直接删除,而SPSS中的重复值处理可以先标识然后再删除,相对更合理一点。下面分别讲讲这三种方法。
(1)EXCEL中的“删除重复项”
首先,选择“数据”中的“删除重复项”,如图3-2所示。
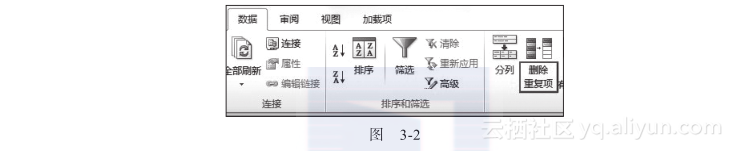
然后选择判断是否重复的项,如图3-3所示。
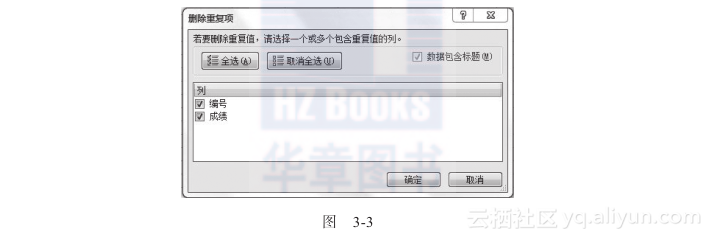
请注意,图3-3中的“编号”、“成绩”之前的勾选就是重复值的判断条件,意思就是如果编号和成绩都相同,那么就是重复值。我们可以用是否勾选来灵活决定判断重复值的条件。
点击“确定”后会弹出图3-4所示的对话框。

删除重复项的操作简单易行,但是有一个重大缺陷,就是它会直接将重复值删除,这有点“简单粗暴”,更理想的方法是先标注一下,待操作人员查看确认之后,再删除比较好。因此在做这个操作之前最好先进行数据备份。
(2)高级筛选
很多人都知道高级筛选是用来做多条件的复杂筛选的,但是知道用高级筛选来删除数据的人却不多,下面会介绍这个方法。首先进入高级筛选界面,如图3-5所示。
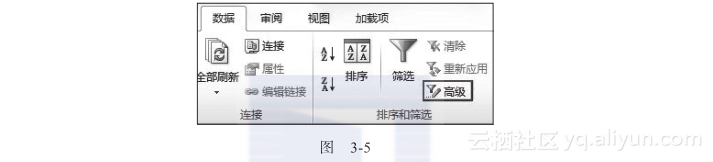
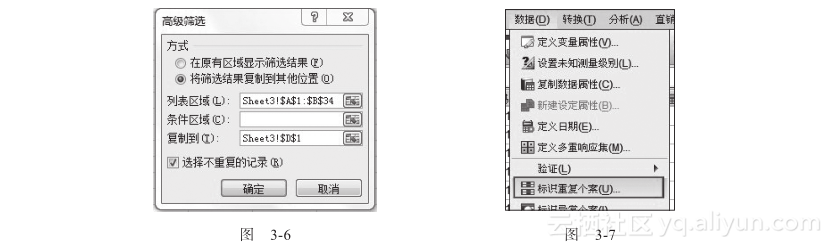
在高级筛选界面中,选择源数据区域和将要复制的数据块位置,如图3-6所示。
特别要注意的是,图3-6左下角的“选择不重复的记录”一定要勾选,然后点击确定,操作即完成。
相对于删除重复项,高级筛选连个输出提示都没有,这让初次使用的人往往感到有点没头没脑,起码应该有一个操作告诉我处理了多少数据、删除了多少数据吧。因此,高级筛选这个操作也需要谨慎,要事先做好数据备份。
(3)SPSS中的处理重复值
在SPSS中有专门处理重复值的模块,请见图3-7。
进入“标识重复个案”模块后,会弹出如图3-8所示的界面。
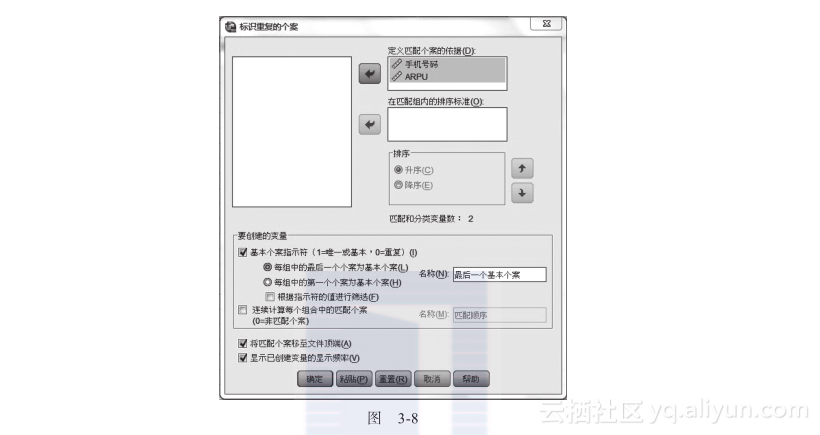
如同EXCEL中的“删除重复项”,SPSS中也需要选择若干字段作为判断是否重复的依据,图3-8中选择了手机号码和ARPU,代表手机号码和ARPU都相同才表示数据重复。“基本个案指示符”中的1表示唯一值,0表示重复值。勾选左下角的“将匹配个案移至文件顶端”表示会将有重复的数据移到文件最上端。
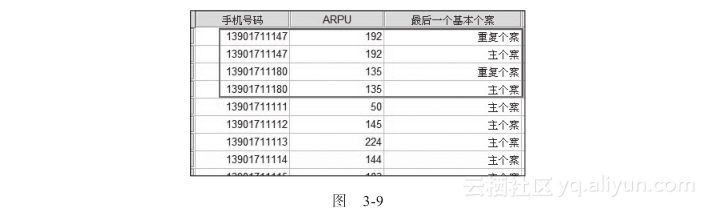
最后的输出结果如图3-9所示。这样的输出结果是比较合理的,可以先观察再删除,比直接删除要安全。
(4)删除空行
以案例文件3.3为例,为了删除空行,先用EXCEL进行排序,如图3-10所示。
排序结束后,删除空行即可,如图3-11所示。
以上删除空行的方法打乱了数据的顺序,若想不打乱数据的顺序,可采用辅助列的方法,如图3-12所示。
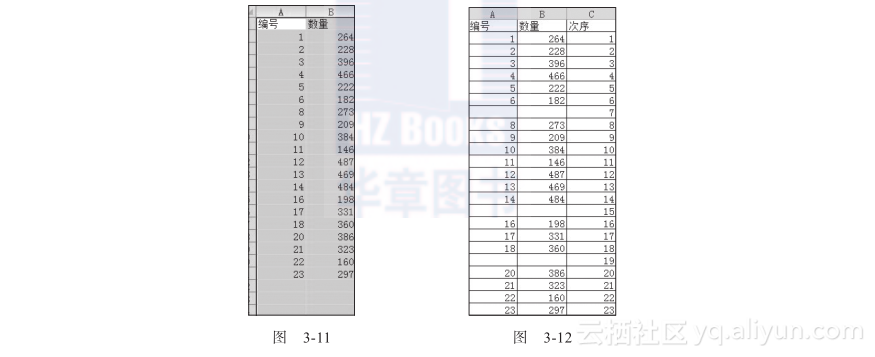
也就是先按照编号进行排序,删除空行后,再按照“次序”进行排序,最后删除“次序”辅助列。
3.3.2 缺失值的填充和分析
数据中的缺失值产生的原因很多,有的是原始数据中就没有,有的是漏了,有的则是因种种原因没有收集;还有填写者故意不填的,例如市场调查的问卷中,涉及收入、对竞争对手如何看待等敏感性问题时,就经常会出现缺漏的情况。还有一种比较特殊的情况是,最近的数据还没有统计出来,例如现在是2017年,可能2017年的Q1的数据还没有出现,甚至有可能2016年的Q4的数据都还没有出来。
之前已经说过,对于缺失值数据,一般不能采用“简单粗暴”的删除方法,而应尽可能地进行填充,下面就介绍一些填充的方法。
(1)手工填充
以案例文件3.4为例,2011年和2012年的数据都是完整的,2013年的数据有一些缺漏,这个时候有几种填充思路:
1)按照2013年销量的平均值做填充,这是比较简单的做法。
2)用历年同月的平均值做填充,例如2013/12/21的数据是空缺的,就拿2011年和2012年销量的平均值来填充,这是比较精准的做法。
以上的填充技术非常简单,不再赘述,直接用average函数即可。
(2)利用SPSS“替换缺失值”进行填充
案例文件3.5,SPSS中有两处菜单功能涉及缺失值,一是“转换”中的“替换缺失值”,二是“分析”中的“缺失值分析”。“替换缺失值”中可以用多种替换方法,以案例文件3.5为例来看一下,先在图3-13所示的菜单找到“替换缺失值”。
然后,进入“替换缺失值”界面,如图3-14所示。
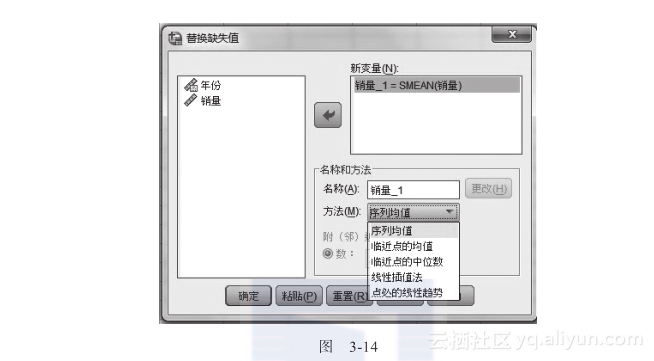
在替换的方法中,有序列均值、临近点的均值、临近点的中位数等多种方法可以选择,一般选择“序列均值”和“临近点的均值”比较多一些。
(3) 利用SPSS“缺失值分析”进行填充
对于案例文件3.6,在分析分组和年龄这两个因素对分析指标的影响时,可采用SPSS的线性回归来处理,如图3-15所示。
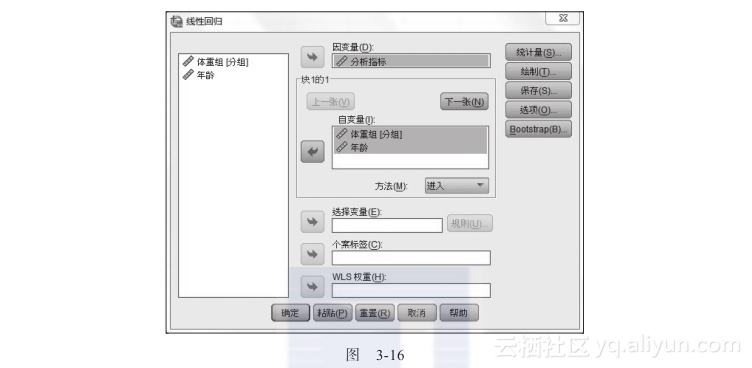
然后进入线性回归的界面进行设置,如图3-16所示。
得到的结论如图3-17所示。
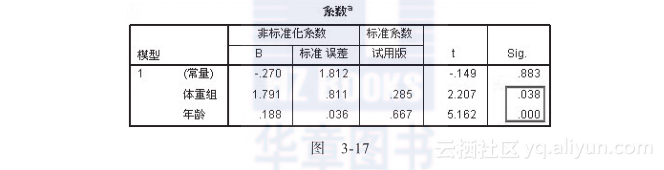
由于体重组和年龄的检验p值都小于0.05,因此得到结论:体重组和年龄对于分析指标都有着显著的影响。
若对案例文件3.7(该案例有缺失值)执行同样的操作,得到的输出结果如图3-18所示。
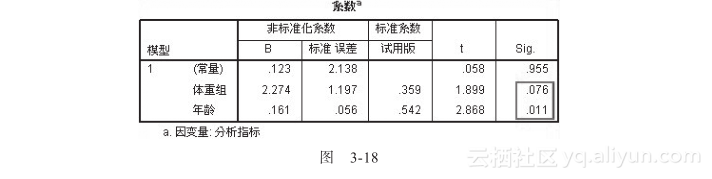
从图3-18所示的输出可以看出,在有缺失值的情况下,体重组的sig是0.076>0.05,因此得到结论:体重组对于分析指标的影响不显著,而年龄对于分析指标的影响显著。
现在考虑如何填充数据,在图3-19所示的界面选择“缺失值分析”。

SPSS的缺失值分析中,常用的有EM和回归这两种方式。下面首先展示EM方式填充缺失值的方法,如图3-20所示。
在图3-20所示的界面中,点击“EM...”,进入如图3-21所示的界面。
将填充好的缺失值放到数据集a中,就完成了相应的操作。
同样也可以用回归方法实现缺失值的填充,如图3-22所示。
为了比较EM和回归这两种填充方法的优劣,仍旧做数据回归来比较EM和回归这两种填充方式的差异,请注意,这里出现了两个“回归”,前面一个“回归”是数据分析的回归方法,后面一个“回归”是SPSS里面的一种填充算法。
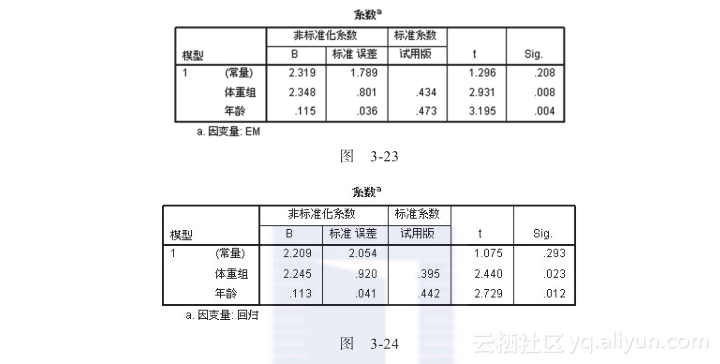
图3-23是采用EM方法填充数据后进行回归分析的输出结果,图3-24是采用“回归”方法填充数据后进行回归分析的输出结果。可以看到,EM回归的两个检验P值0.008和0.004,分别小于0.023和0.012,这说明EM填充缺失值的质量要高于回归填充缺失值。
3.3.3 数据间逻辑的排查

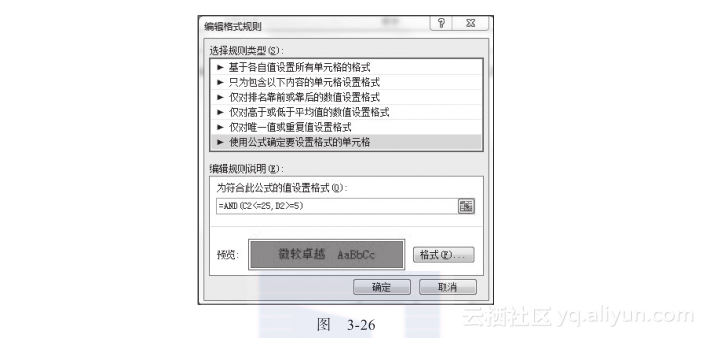
在图3-26中,选择自定义公式,在公示栏中输入公式:=AND(C2<=25, D2>=5),也就是当C2(年龄)小于等于25,并且学历大于等于5(5是硕士,6是博士)的时候,将编号填充为红色,结果如图3-27所示。
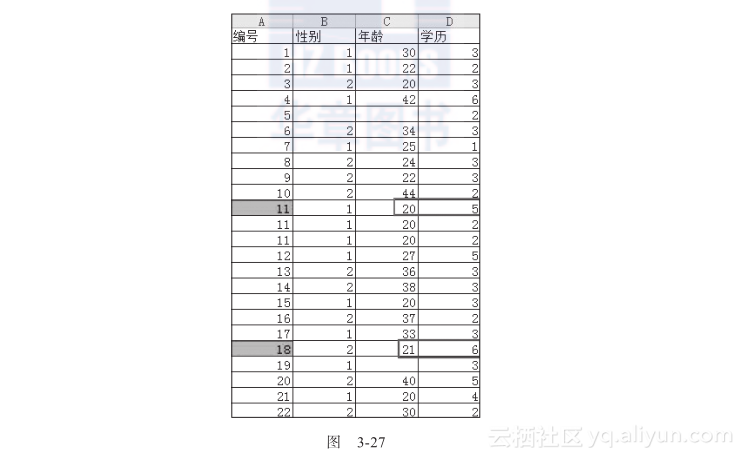
从图3-27可以看出,编号为11和18的,其学历和年龄之间的逻辑关系不正常,需要重点关注和纠正。
根据业务关系来排查数据的例子还很多,这需要读者结合自己的业务逻辑努力去排查判断。
此外,数据合并也是数据准备的重要内容,这将在4.1节中详细叙述,在此不再重复。