1.4 Hadoop的安装
现在假定你已经了解了R语言,知道它是什么,如何安装它,它的主要特点是什么,以及为什么要使用它。现在,我们需要知道R的局限性(这样能更好地引入对Hadoop的介绍)。在处理数据前,R需要将数据加载到随机存取存储器(RAM)。因此,数据应该小于现有机器内存。对于数据比机器内存还要大的,我们将其看做大数据(由于大数据还有许多其他定义,这只适用于我们现在所说的例子)。
为了避免这类大数据问题,我们需要扩展硬件配置,但这只是一个临时解决方案。为了解决这一问题,我们需要使用一个Hadoop集群,能够存储大数据并在大型计算机集群进行并行计算。 Hadoop是最流行的解决方案。 Hadoop是一个开源的Java框架,它是Apache软件基金会操作下的顶级项目。 Hadoop的灵感源于Google文件系统和MapReduce,这两项技术主要用于进行分布式大数据处理。
Hadoop主要支持Linux操作系统。若要在Windows上运行它,我们需要使用VMware在Windows操作系统中加载Ubuntu。实际上使用和安装Hadoop的方法有很多种,但在这里我们考虑支持R语言的最佳方式。在我们整合R和Hadoop之前,先来理解什么是Hadoop。
机器学习包含了所有数据建模技术,深入了解这些技术请访问:http://en.wikipedia.org/wiki/Machine_learning。
Michael Noll的Hadoop安装指导博客:Http://www.michael-noll.com/tutorials/running-hadoop-on-ubuntu-linux-single-node-cluster/。
1.4.1 不同的Hadoop模式
Hadoop使用方式有以下三种模式:
the Standalone mode(单机版模式):在此模式下,不需要启动任何Hadoop后台程序。相反,只需要打开~/Hadoop-directory/bin/hadoop以单一Java进程方式执行Hadoop程序。建议此模式用于测试目的。这是默认模式,无须进行任何其他配置。所有的后台程序,如NameNode、DataNode、JobTracker和TaskTracker都以单一Java进程运行。
the pseudo mode(虚拟模式):在此模式下,需要在所有节点上配置Hadoop。每个Hadoop的组件或守护进程使用一个单独的JAVA虚拟机(JVM),类似于在一个主机上运行最小集群。
the full distributed mode(全分布模式):在此模式下,Hadoop将分布在多台机器中。专用主机根据每个Hadoop节点进行配置。因此,不同的JVM进程对所有的守护进程开放。
1.4.2 Hadoop的安装步骤
Hadoop的安装有几种可行方式,我们将选择与R整合更好的方式。我们将选择Ubuntu操作系统,因为它易于安装和操作。
1. 在Linux、Ubuntu面板(单节点以及多节点集群)上安装Hadoop。
2. 在Ubuntu上安装Cloudera Hadoop。
在Linux、Ubuntu面板上安装Hadoop(单节点集群)
要在Ubuntu操作系统安装Hadoop的虚拟模式,需要满足以下先决条件:
使用Sun Java 6
成为专用的Hadoop系统用户
配置SSH
禁用IPv6
以上提供的Hadoop的安装可使用Hadoop MRv1实现。
按照以下步骤安装Hadoop。
1. 从Apache软件基金会下载最新的Hadoop。在这里,我们采用Apache Hadoop 1.0.3,尽管最新的版本是1.1.x.
- 添加$JAVA_HOME和$HADOOP_HOME变量到Hadoop系统用户的.bashrc文件。更新后的.bashrc文件如下:

- 用conf / * -site.xml命令来更新Hadoop的配置文件。
最后,3个文件如下。
conf/core-site.xml:


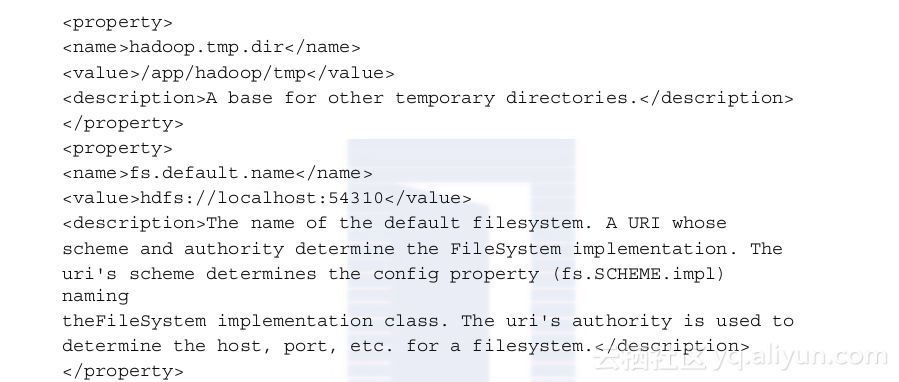
conf/mapred-site.xml:
conf/hdfs-site.xml:
完成这些配置文件的编辑后,需要在Hadoop的集群或节点上设置分布式文件系统。
使用下面的命令行通过NameNode格式化Hadoop分布式文件系统(Hadoop Distributed File System,HDFS):
通过使用以下命令行启动单节点群集:
在Linux、Ubuntu面板上安装Hadoop(多节点集群)
我们已经知道如何在单节点集群上安装Hadoop。现在看看如何在一个多节点集群上安装Hadoop(全分布式模式)。
为此,我们需要若干个已经配置好Hadoop单节点集群的节点。为了在多节点上安装Hadoop,我们需要一台已经配置好上一节描述过的单节点Hadoop集群的机器。
当安装好了这个单节点Hadoop集群后,我们需要进行下述步骤:
1. 在网络状态里,需要使用两个节点来创建一个全分布Hadoop模式。为了让节点之间相互通信,节点所在的软件和硬件配置必须在一个网络中。
2. 在这两个节点中,一个节点被设置成主节点,另一个被设置为从节点。为了进行Hadoop操作,从节点需要连接主节点。我们将主节点设置为192.168.0.1,从节点设置为192.168.0.2。
3. 在两个节点中升级/etc/hosts目录。这个目录将会成为192.168.0.1主节点和192.168.0.2从节点的镜像。
可以像进行过的单节点集群安装一样进行Secure Shell(SSH)的安装。详细情况可以访问http://www.michael-noll.com。
4. 升级conf/*-site.xml:必须改变所有节点的如下配置文件。
conf/core-site.xml和conf/mapred-site.xml:在单节点集群安装中,已经升级过这些文件。所以,只需在value标签中将localhost改变为master。
conf/hdfs-site.xml:在单节点集群安装中,将dfs.replication的值设成1,现在更新这个值为2。
5. 在格式化HDFS阶段,需要在启动多节点集群前,用以下命令(在主节点)格式化HDFS:
现在,我们已经完成安装一个多节点集群的所有步骤。需要进行以下步骤来启动这个Hadoop集群:
1. 启动HDFS进程:
- 启动MapReduce进程:
- 通常如下命令启动所有进程:
- 停止所有进程:


这些安装步骤是受Michael Noll的博客(http://www.michael-noll.com)启发而产生的,他是瑞士的一位研究学者以及软件工程师。他在威瑞信公司担任基于Apache Hadoop的大规模计算框架的技术指导。
现在Hadoop集群已经在机器上创建好了。如果想要使用扩展的Hadoop组件在单节点或者多节点上安装相同的Hadoop集群,可以尝试使用Cloudera工具。
在Ubuntu上安装Cloudera Hadoop
Cloudera Hadoop(CDH)是Cloudera的开源分布式架构,其致力于应用Hadoop技术进行企业级开发。Cloudera也是Apache软件基金会的捐助者。CDH有两个可用的版本:CDH3和CDH4。为了安装其中任何一个版本,都必须使用10.04 LTS版或者12.04 LTS版的Ubuntu(当然,也可以使用CentOS、Debian和Red Hat操作系统)。如果在一个集群上安装Hadoop,可以使用Cloudera管理器简化它的安装过程,这个管理器提供基于Hadoop的GUI界面以及覆盖整个集群的Cloudera组件安装。对于大型集群来说这个工具十分值得推荐。
我们需要满足如下先决条件。
配置SSH
具备以下特征的操作系统:
64位的10.04 LTS版或者12.04 LTS版Ubuntu
Red Hat企业级Linux 5或者Linux 6
CentOS 5或6
Oracle企业级Linux 5
SUSE Linux企业级服务器11(SP1或者lasso)
Debian 6.0
安装步骤如下。
1. 下载并运行Cloudera管理器:为了初始化Cloudera管理器的安装过程,需要首先从Cloudera下载版块下载cloudera-manager-installer.bin文件。之后,在集群上保存它,这样所有的节点可以读取这个文件。给用户执行cloudera-manager-installer.bin的权限。运行下面的命令来启动安装:
- 阅读Cloudera管理器的Readme文件并点击Next。
- 启动Cloudera管理器的管理员控制台:这个控制台允许你使用Cloudera管理器进行安装、管理以及监视集群上的Hadoop。在从Cloudera服务提供商得到许可后,需要在浏览器地址栏里输入http://localhost:7180。你同样可以使用以下浏览器:
Firefox 11或者更高版本
Chrome
Internet Explorer
Safari - 使用默认的用户名和密码admin登录Cloudera管理控制台。以后你可以根据自己的选择改变它。
- 通过浏览器使用Cloudera管理进行CDH3的自动化安装和配置:这一步会将所需的大部分Cloudera Hadoop安装包从Cloudera安装到你的机器中。步骤如下:
1)如果你已经选择了一个完整的软件版本,安装并验证你的Cloudera管理密钥许可文件。
2)为你的CDH集群装置指定主机名或IP地址范围。
3)使用SSH连接每台主机。
4)在每台群集主机上安装Java开发工具包(JDK)(如果尚未安装)、Cloudera管理代理和CDH3或CDH4。
5)在每个节点上配置Hadoop并启动Hadoop服务。 - 在运行该向导并使用Cloudera管理器后,应该尽快更改默认的管理员密码。为了更改管理员密码,需遵循这些步骤:
1)单击齿轮符号图标以显示管理页。
2)打开Password标签。
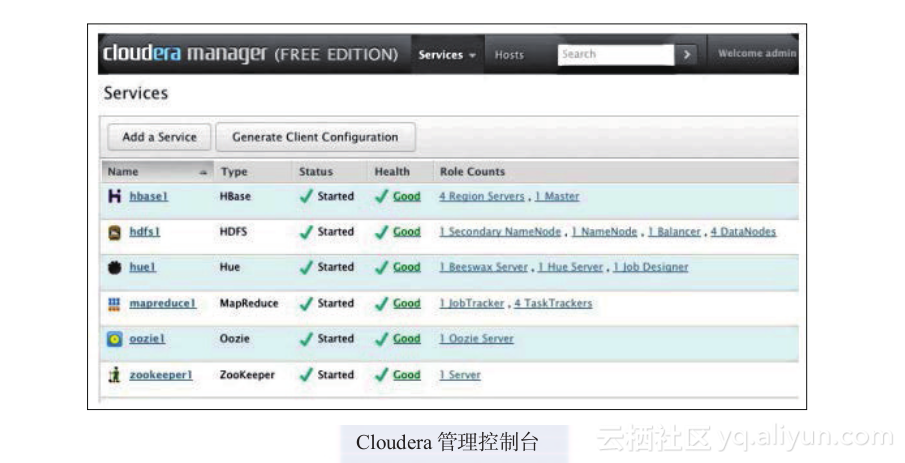
3)输入新密码两次,然后点击Update。 - 测试Cloudera Hadoop的安装:可以在群集上通过登录Cloudera管理控制台并点击Services标签来检查Cloudera管理的安装。你应该看到如下图所示的界面。
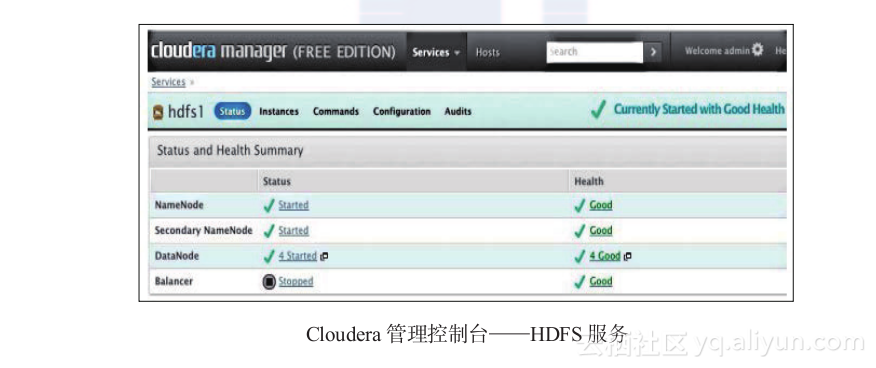
- 可以点击每个服务查看更详细的信息。例如,点击hdfs1链接,会看到类似下面的截图。
为了避免这些安装步骤,可以使用预先配置的带有Amazon Elastic MapReduce和MapReduce实例的Hadoop。如果在Windows上使用Hadoop,可以通过Hortonworks尝试HDP工具。这是百分百的开源产品,是企业级分布的Hadoop。可以在http://hortonworks.com/download/上下载HDP工具。