1.1 数据管理的发展
从计算机产生之后,人们就希望用计算机存储和管理数据。最初用计算机对数据进行管理是以文件方式进行的,即将数据保存在用户定义好的文件中,然后编写对数据文件进行操作的应用程序。这种数据管理方式对用户的要求比较高,需要有较高的计算机编程技能,同时还要具有数据存储和访问知识,以最大限度地提高数据访问效率。随着数据量的不断增大,计算机处理能力的不断增强,人们对数据的要求越来越多,希望达到的目的也越来越复杂,因此用文件对数据进行管理,通过编程的方法来操作文件中数据的方式已经很难满足人们对数据的需求,由此产生了数据库管理系统,也就是用数据库管理系统来对数据进行维护。综上所述,使用计算机对数据进行管理经历了文件管理和数据库管理两个发展阶段。
本节介绍文件管理和数据库管理在数据管理上的主要差别。
1.1.1 文件管理系统
理解当今数据库特征的最好办法是了解一下在使用数据库技术之前数据管理的特点。
早期的数据管理是采用文件方式进行的,即数据保存在文件中,文件是由操作系统和特定的软件或程序共同管理的。在文件管理方式中,数据按其内容、结构和用途分成若干个命名的文件。文件一般为某一用户或用户组所有。用户可以通过操作系统和特定的识别这些文件格式的软件对文件进行打开、读、写等操作,也可以通过程序设计语言编写对文件进行操作的程序。
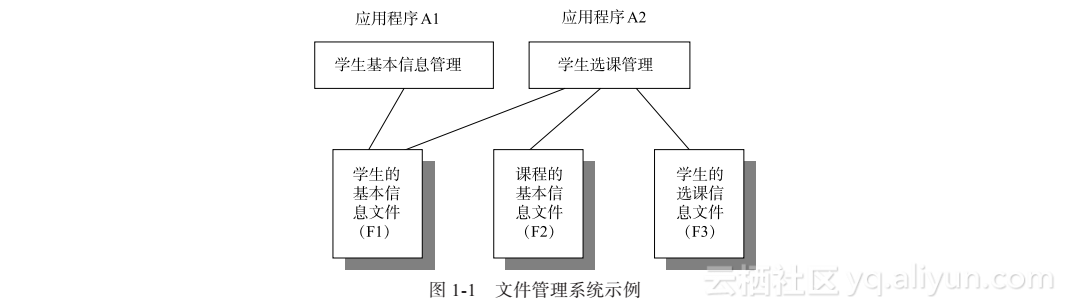
假设现在要用某种程序设计语言编写对学生信息进行管理的系统(注:程序负责对文件的打开、关闭以及对其中数据的读、写操作,具体对磁盘文件操作的实现是由操作系统中的文件管理等部分完成的)。在此系统中,要对学生的基本信息和选课情况进行管理。在学生基本信息管理中要用到学生的基本信息数据,假设此数据保存在F1文件中。学生选课情况的管理包括学生的基本信息、课程的基本信息和学生的选课信息。假设用F2和F3两个文件分别存储课程的基本信息和学生的选课信息数据,此部分的学生基本信息数据可以使用F1文件中的数据。设A1为实现“学生基本信息管理”功能的应用程序,A2为实现“学生选课管理”功能的应用程序。文件管理系统示例如图1-1所示。
假设F1、F2和F3文件分别包含如下信息。
F1:学号、姓名、性别、出生日期、所在系、专业、所在班、特长、家庭住址。
F2:课程号、课程名、授课学期、学分、课程性质。
F3:学号、姓名、所在系、专业、课程号、课程名、修课类型、修课时间、考试成绩。
我们将文件中所包含的每一个子项称为文件结构中的字段或列,将每一行数据称为一条记录。
“学生选课管理”的处理过程大致如下:
在学生选课管理中,若有学生选课,需先查F1文件,判断有无此学生;若有则访问F2文件,判断其所选的课程是否存在;若一切合乎规则,则将学生选课信息写到F3文件中。
这看起来似乎很好,但仔细分析,就会发现直接用文件管理数据有如下一些缺点。
1. 编写应用程序不方便
应用程序编写者必须对所使用的文件的逻辑及物理结构(文件中包含多少个字段,每个字段的数据类型,采用何种存储结构,比如链表或数组等)有清楚的了解。操作系统只提供了打开、关闭、读、写等几个低级的文件操作命令,而对文件的查询、修改等处理都必须在应用程序中编程实现。这样也易造成各应用程序在功能上的重复,例如图1-1中的“学生基本信息管理”和“学生选课管理”都要对F1文件进行操作。
2. 数据冗余不可避免
假设应用程序A2需要在F3文件中包含学生的所有或大部分信息。例如,除了学号之外,还需要姓名、专业、所在系等信息,而F1文件中也包含这些信息,因此F3文件和F1文件中有重复的信息,由此会造成数据的重复(又称为数据冗余)。
数据冗余所带来的问题不仅仅是存储空间的浪费,更为严重的是会造成数据不一致(inconsistency)。例如,假设学生所在的专业发生了变化,通常情况下,我们可能只记得在F1文件中进行修改,而忘记了在F3文件中也要进行同样的修改,由此会造成同一名学生在F1文件和F3文件中的“专业”不一样,也就是数据不一致。人们不能判定哪个文件中的数据是正确的,因此也就失去了数据的可信度。
文件系统中没有维护数据一致性的功能,这完全由用户(应用程序开发者)负责维护。这在简单的系统中还可以勉强应付,但在复杂的系统中,若要保证数据的一致性,几乎是不可能的。
3. 应用程序依赖性
就文件处理而言,程序依赖于文件的格式。文件和记录的逻辑结构通常是应用程序代码的一部分,如C语言用Struct、Visual Basic用Type来定义用户的数据结构。文件结构的每一次修改都将导致应用程序的修改。而随着应用环境和需求的变化,修改文件的结构是不可避免的事情。例如,增加一些字段、修改某些字段的长度(如电话号码从7位扩展到8位)。这些都需要在应用程序中做相应的修改,而(频繁)修改应用程序是很麻烦的,因为首先要熟悉原有程序,修改后还需要对程序进行测试、安装等。
所有这些都是由于应用程序对数据文件的过度依赖造成的,换句话说,文件系统的数据独立性(data independence)不好。
4. 不支持对文件的并发访问
在现代计算机系统中,为了有效地利用计算机资源,一般允许多个应用程序并发执行(尤其是在现在的多任务操作系统环境中)。文件最初是作为程序的附属数据出现的,它一般不支持多个应用程序同时对同一个文件进行访问。我们可以想一下,假设某个用户打开了一个Excel文件,如果第二个用户在第一个用户没有对此文件关闭之前,也想打开此文件,他会得到什么信息?他只能以只读的方式打开此文件,而不能在第一个用户打开的同时对此文件进行修改。上述就是文件系统不支持并发访问的原因。
对于以数据为中心的应用系统来说,支持多个用户对数据的并发访问是必不可少的功能。
5. 数据间联系弱
在文件系统中,文件与文件之间是彼此独立、毫不相干的,文件之间的联系必须通过程序来实现。例如上述的F1文件和F3文件,F3文件中的学号、姓名等学生的基本信息必须是F1文件中已经存在的(即选课的学生信息必须是已经存在的);同样,F3文件中的课程号等与课程有关的基本信息也必须是F2文件中已经存在的(即学生选的课程也必须是已经存在的)。这些数据之间的联系是实际需求当中所要求的很自然的联系,但文件系统本身不具备自动实现这些联系的功能,必须依靠应用程序来保证这些联系,也就是必须通过编写程序来手工地保证这些联系。这不但增加了程序编写的工作量和复杂度,而且当联系很复杂时,也难以保证其正确性。因此,文件系统不能反映现实世界事物间的联系。
6. 难以按不同用户的愿望表示数据
如果用户需要的信息来自于多个不同文件中部分信息的组合,就需要对多个文件进行提取、比较、组合和表示。例如,假设有用户希望得到如下信息:
(所在班,学号,姓名,课程名,学分,考试成绩)
这些信息涉及了3个文件:从F1文件中得到“所在班”信息,从F2文件中得到“学分”,从F3文件中得到“考试成绩”;而“学号”、“姓名”可以从F1文件或F3文件中得到,“课程名”可以从F2文件或F3文件中得到。在生成一行数据(所在班,学号,姓名,课程名,学分,考试成绩)时,必须对从3个文件中读取的数据进行比较,然后组合成一行有意义的数据。例如,将从F1文件中读取的学号与从F3文件中读取的学号进行比较,学号相同时,才可以将F1文件中的“所在班”、F3文件中的“考试成绩”以及当前所对应的学号和姓名组合成一行数据的内容。同样,在处理完F1文件和F3文件的组合后,可以在组合的结果中再与F2文件中的内容进行比较,找出课程号相同的课程的学分,再与已有的结果组合起来。如果数据量很大,且涉及的表比较多,我们可以想象这个过程有多么复杂。因此,这种大容量且复杂信息的查询,在文件管理系统中是很难处理的。
7. 无安全控制功能
在文件管理系统中,很难控制某个人对文件的操作权,如只能读和修改数据而不能删除数据,或者对文件中的某个或某些字段不能读或修改等。而在实际生活中,数据的安全性是非常重要且不可缺少的。例如,在学生选课管理中,学生对其考试成绩一般只有查看权,而教师则有录入其所授课程的考试成绩的权限、教务部门对录入有误的成绩有修改权等。
随着人们对数据需求的增加以及计算机科学的不断发展,如何对数据进行有效、科学、正确、方便的管理已成为人们的迫切愿望。针对文件系统的上述缺陷,人们逐步发展了以统一管理和共享数据为主要特征的数据库管理系统。
1.1.2 数据库管理系统
数据库技术的发展主要源于文件管理系统在管理数据上的诸多缺陷。对于上述学生基本信息管理和学生选课管理,如果使用数据库技术来实现,其实现方式与文件系统有本质的区别,如图1-2所示。

比较图1-1和图1-2,可以直观地发现两者有如下差别:
使用文件系统时,应用程序直接访问存储数据的文件,而使用数据库系统时则通过数据库管理系统(DataBase Management System,DBMS)访问数据,而且存储数据的文件以数据库的形式展示给客户,这个变化使得应用程序开发人员不再需要关心数据的物理存储方式和存储结构,这些都交给了数据库管理系统来完成,从而极大地简化了应用编程工作。
在数据库系统中,数据不再仅仅服务于某个程序或用户,而是看成一定业务范围的共享资源,由一个称做数据库管理系统的软件统一管理。
与文件系统相比,数据库管理系统实际上是在应用程序和存储数据的数据库(在某种意义上也可以把数据库看成是一些文件的集合)之间增加了一层—数据库管理系统。数据库管理系统实际上是一个系统软件。正是因为有了这个系统软件,才使得以前在应用程序中由开发人员编程实现的很多烦琐的操作和功能交给了数据库管理系统,这样应用程序不再需要关心数据的存储方式。而且数据存储方式的变化也不再影响应用程序,这些变化交给数据库管理系统来处理,经过数据库管理系统处理后,应用程序感觉不到这些变化,因此,应用程序也不需要进行任何修改。
与直接用文件管理数据的局限性进行比较,我们就能体会到使用数据库技术管理数据所带来的好处。
1. 将相互关联的数据集成在一起
在数据库系统中,所有的数据都存储在数据库中,应用程序可通过DBMS访问数据库中的所有数据。
2. 数据冗余小
由于数据被统一管理,因此可以从全局着眼,合理地组织数据。例如,将1.1.1节中的F1、F2和F3文件中的重复数据,可以形成如下所示的几部分信息。
学生基本信息:学号、姓名、性别、出生日期、所在系、专业、所在班、特长、家庭住址。
课程基本信息:课程号、课程名、授课学期、学分、课程性质。
学生选课信息:学号、课程号、修课类型、修课时间、考试成绩。
在关系数据库(关系数据库的概念在本章后续部分介绍)中,可以将每一种信息存储在一个表中,重复的信息只存储一份,当在学生选课中需要学生的名字时,根据学生选课信息中的学号,可以很容易地在学生基本信息中找到此学号对应的名字。因此,消除数据的重复存储并不影响对信息的提取,同时还可以避免由于数据重复存储而造成的数据不一致问题。例如,当某个学生所学的专业发生变化时,我们只需在“学生基本信息”一个地方进行修改即可。
同1.1.1节中的问题一样,当检索(所在班,学号,姓名,课程名,学分,考试成绩)信息时,这些信息需要从3个地方(关系数据库为3张表)得到,也需要对信息进行适当的组合,即学生选课中的学号只能与学生基本信息中学号相同的信息组合在一起,同样,学生选课中的课程号也必须与课程基本信息中课程号相同的信息组合在一起。在以前的文件管理系统中,这个工作是由开发者编程实现的,而现在有了数据库管理系统,这些烦琐的工作完全交给了数据库管理系统来完成。
3. 程序与数据相互独立
在用数据库技术管理数据的方式中,所有的数据以及数据的存储格式都与数据一起存储在数据库中,它们通过DBMS而不是应用程序来访问和管理,应用程序不再需要处理数据文件的存储结构。
程序与数据相互独立有两个方面的含义,一方面是指当数据的存储方式发生变化(这里包括逻辑存储方式和物理存储方式)时,比如从链表结构改为哈希结构,或者是顺序和非顺序之间的转换,应用程序不必做任何修改;另一方面是指当数据的逻辑结构发生变化时,比如增加或减少了一些数据项,如果应用程序与这些修改的数据项无关,则应用程序也不用修改。这些变化都由DBMS负责维护。大多数情况下,应用程序并不需要知道数据存储方式或数据项已经发生了变化。
4. 保证数据的安全和可靠
数据库技术能够保证数据库中的数据是安全的、可靠的。数据库中有一套安全控制机制,可以有效地防止数据库中的数据被非法使用或非法修改;同时它还有一套完整的备份和恢复机制,以保证当数据遭到破坏(由软件或硬件故障引起的)时,能够很快将数据库恢复到正确的状态,并使数据不丢失或只有很少的丢失,从而保证系统能够连续、可靠地运行。
5. 最大限度地保证数据的正确性
保证数据的正确性是指存放到数据库中的数据必须符合现实世界的实际情况,比如人的性别只能是“男”或“女”,人的年龄应该在0~150岁之间(假设没有年龄超过150岁的人),如果我们在性别中输入了其他的值,或者将一个负数输入到年龄中,在现实世界中显然是不对的。数据库系统能够保证进入到数据库中的数据都是正确的数据。保证数据正确性的特征也称为数据完整性。数据完整性是通过在数据库中建立约束来实现的。当用户建立好保证数据正确的约束之后,如果有不符合约束条件的数据进入到数据库中,数据库管理系统能主动拒绝这些数据。
6. 数据可以共享并能保证数据的一致性
数据库中的数据可以被多个用户共享,共享是指允许多个用户同时操作相同的数据。当然,这个特点是针对大型多用户数据库系统而言的,对于单用户系统,在任何时候最多只有一个用户访问数据库,因此不存在共享的问题。
多用户问题是数据库管理系统内部解决的问题,它对用户是不可见的。这就要求数据库能够对多个用户进行协调,保证多个用户之间对数据的操作不发生矛盾和冲突,即在多个用户同时使用数据库时,能够保证数据的一致性和正确性。可以想象一下火车订票系统,如果多个订票点同时对一列火车进行订票操作,那么必须要保证不同订票点订出票的座位不能相同。
数据库技术发展到今天已经是一门比较成熟的技术,经过上面的讨论,可以发现数据库具备如下特征:数据库是相互关联的数据的集合,它用综合的方法组织数据,具有较小的数据冗余,可供多个用户共享,具有较高的数据独立性,具有安全控制机制,能够保证数据的安全、可靠,允许并发地使用数据库,能有效、及时地处理数据,并能保证数据的一致性和完整性。
需要再次强调的是,所有这些特征并不是数据库中的数据固有的,而是靠数据库管理系统提供和保证的。