11.71 在线多示例度量学习的结构化稀 疏表观模型
正如上一节所述,稀疏表示作为一种有效的物体中层表示策略,在视觉目标跟踪中得到了成功应用。然而,基于稀疏的跟踪算法中[3-9]最终跟踪结果的确定大多以重构误差大小为衡量标准。研究发现,以重构误差构造目标的观测似然概率存在一些问题。
(1)重构误差的大小很大程度上依赖于字典的构成。很多跟踪算法[12-13]采用在线地更新字典基元的方式以适应目标表观变化,即所谓的跟踪中字典学习策略。然而,用最新的跟踪结果来更新字典基元,由于潜在的误差累积很容易造成跟踪漂移。
(2)跟踪中,重构误差通常以预先定义好的度量来计算,比如L2距离[14-15] 、Matusita距离 [16] 等。而预先设定的度量往往缺少适应表观变化的能力。
(3)大部分算法直接用重构误差构造目标的观测似然概率却没有考虑背景信息,尤其是基于稀疏表示的产生式跟踪算法,以致于在处理复杂背景时由于缺少判别力而失败。
为了解决上述问题,这里主要关注的是通过在线度量学习算法学习合适的度量以确定与给定模板最相似的候选区域,而不是直接用重构误差来定位目标区域。本章提出了一种基于在线多示例度量学习的结构化稀疏表观模型。目的是在局部稀疏编码特征空间中通过学习合适的度量矩阵使得同一物体的不同表观彼此相似,同时能使物体很好的从背景分离出来。所提方法主要包括以下两点内容:① 权重局部稀疏编码的多尺度最大汇聚操作。直接从感兴趣区域获得稀疏编码易受旋转变换、噪声等影响。为减轻这些影响,对候选目标中采样得到的局部图像块的稀疏编码向量进行多尺度最大汇聚操作(Multi-scale max pooling)。这种汇聚操作既考虑了局部表示的空间信息又对平移、旋转变换有很好的鲁棒性。采用这种表示策略能提高目标定位的准确性。② 在线多示例度量学习。一般地,在跟踪结果周围区域采用训练样本更新表观模型。轻微的误差累积会使学到的度量性能下降从而跟丢目标。受多示例学习的启发,提出一种在线多示例度量学习策略,利用“打包”的思想为训练样本分配标签,能很好的减轻跟踪的漂移问题。
本节提出的方法与其他基于局部稀疏编码的目标跟踪方法[3,17-18]不同,本节用权重局部稀疏编码建模物体表示,即在整个目标表示的稀疏向量中,越靠近目标中心的图像块的稀疏编码权重越大;反之越小。并且利用度量学习的思想构建目标的似然概率,使得目标能很好的从背景中分离出来。在文献 [3] 中,作者用对齐汇聚方法对局部图像块的稀疏编码进行汇聚操作以提高跟踪性能。当目标的形变较小或者变化比较平稳时对齐汇聚能取得较好的跟踪效果,然而,它不能处理较大形变的情况。与文献 [17] 不同的是本方法无需独立地将产生式跟踪和判别式跟踪结合在一起,建模的视觉特征相似性度量目标函数既考虑背景信息又具有产生式跟踪的特点。
与已有的基于度量学习的目标跟踪算法[19-23]不同,所提出的在线多示例度量学习算法,能有效地减轻跟踪中目标漂移问题。Jiang et al [19] 在核跟踪[24]的 框 架 下 采 用(neighborhood component analysis,NCA)度量学习策略自适应的更新相似性矩阵取得了理想的结果;然而其采用简单的颜色直方图来表示物体,不能很好地处理遮挡情况。其次,在当前帧跟踪结果周围选择正负样本,这样会随着跟踪结果的误差累积使得度量学习失去它应有的作用,即产生漂移问题。Wu et al [21] 通过学习不同分布之间合适度量用到轮廓跟踪中。然而,上面提到的这些算法[19-21]都是采用离线的形式每隔几帧重新学习度量矩阵,这无疑增加了计算负担。Li et al [22] 用学到的 Mahalanobis 距离建模非稀疏的表观模型用于跟踪,由于忽略了琐碎模板从而不能很好地处理遮挡问题。Tsagkatakis et al [23] 用在线度量学习自适应地为最近邻分类器寻找最优的度量矩阵;然而,它和众多判别式跟踪方法类似很容易产生漂移问题。需要指出的是,Hong et al [25] 在原始的图像空间中运用 Dual-force 度量学习和 L1 最小化框架提出了一种抗干扰的跟踪算法。与文献 [25] 方法不同,本方法是在稀疏编码特征空间中学习合适的度量;采用了三种不同的距离约束使学得的距离能聚合同类数据并分离不同类数据。同时,采用多尺度最大汇聚的局部稀疏表示比单纯地使用灰度特征的方法[20,23,25]能更好的处理遮挡挑战。
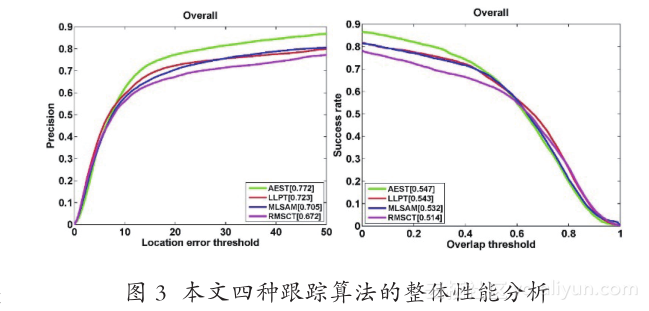
至此,本文从表观建模中目标表示和统计建模两个要素出发一共提出了四种跟踪方法。分别是基于锚点标签传播的判别式跟踪方法(RobustDiscriminative Tracking via Landmark-based LabelPropagation,LLPT)、基于主动样本选择的判别式 跟 踪 方 法(Online Discriminative Tracking withActive Example Selection,AEST)、 基 于 黎 曼 流形稀疏表示的目标跟踪方法(Sparse Representationon Riemannian Manifold for Visual Tracking,RMSCT)和在线多示例度量学习的结构化表观模型(Metric Learning based Structural AppearanceModel,MLSAM)。其中 LLPT 和 AEST 关注的是统计建模,RMSCT 主要关注目标的表示策略,而MLSAM 同时考虑了表示和统计建模。本文利用精确度(Precision Plot)重叠率(Overlap Rate)来衡量跟踪器的性能[26] 。精确度统计的是在一个图像序列中跟踪位置与真值之间的误差,在一定阈值范围内的图像帧数占整个图像序列帧数的百分比。比如,阈值设定为 20 个像素。一个好的跟踪算法在较低阈值下能有较高的精确度。如果一跟踪器在跟踪过程中丢失了目标,它很难得到较高的精确度,除非是跟踪器在图像序列的最后几帧丢失目标。重叠率则更能体现跟踪性能的鲁棒性,因为它不但考虑了跟踪框的位置,还考虑了跟踪框的面积、旋转等因素。图 3 给出了本文四种算法在 Benchmark测试集[26]上的精确度和成功率的结果。从图 4 可以看出,关注统计建模的 LLPT 和 AEST 要比关注目标表示的 RMSCT 好。虽然 MLSAM 同时考虑了表示和统计建模,但是在 MLSAM 中统计建模用的是监督的度量学习。监督的学习策略还是很容易引起漂移问题。LLPT 和 AEST 都采用半监督的学习策略,充分利用了标签数据和无标签数据的几何结构关系,使学到的分类器更能适应表观变化。