2.1.2 TF/IDF评分公式
从Lucene 4.0版本起,Lucene引入了多种不同的打分公式,这一点或许你已经有所了解了。不过,我们还是希望在此探索一下默认的TF/IDF打分公式的一些细节。请记住,为了调节查询相关性,你并不需要深入理解这个公式的来龙去脉,但是了解它的工作原理却非常重要,因为这有助于简化相关度调优过程。
1. Lucene的理论评分公式
TF/IDF公式的理论形式如下: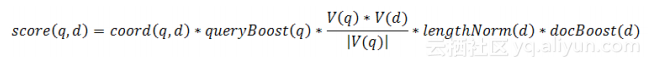
上面的公式融合了布尔检索模型和向量空间检索模型。我们不打算在此讨论理论评分公式,而是直接跳到实践中使用的评分公式,看看Lucene内部是如何实现和使用评分公式的。
关于布尔检索模型和向量空间检索模型的知识远远超出了本书的讨论范围,想了解更多相关知识,请参考http://en.wikipedia.org/wiki/Standard_Boolean_model 和http://en.wikipedia.org/ wiki/Vector_Space_Model。
2. Lucene的实际评分公式
现在让我们看看Lucene实际使用的评分公式: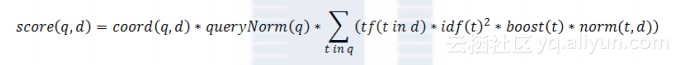
也许你已经看到了,评分公式是一个关于查询q和文档d的函数,正如我们之前提到的一样。有两个因子并不直接依赖查询词项,它们是coord和queryNorm,这两个因子与查询词项的一个求和公式相乘。
求和公式中每个加数由以下因子连乘所得:词频,逆文档频率,词项权重,范数。范数就是之前我们提到过的长度范数。
这个公式听起来很复杂。请别担心,你并不用记住所有的细节,你只需要意识到哪些因素是与评分有关的即可。从前面的公式我们可以导出一些基本的规则:
- 越罕见的词项被匹配上,文档得分越高。Lucene认为包含独特单词的文档比包含常见单词的文档更重要。
- 文档字段越短(包含更少的词项),文档得分越高。通常,Lucene更加重视较短的文档,因为这些短文档更有可能和我们查询的主题高度吻合。
- 权重越高(不论是索引期或是查询期赋予的权重值),文档得分越高。因为更高的权重意味着特定数据(文档、词项、短语等)具有更高的重要性。
正如你所见,Lucene将最高得分赋予同时满足以下条件的文档:包含多个罕见查询词项,词项所在字段较短(该字段索引了较少的词项)。该公式更“喜欢”包含罕见词项的文档。
如果你想了解更多关于Apache Lucene TF/IDF评分公式的信息,请参考Apache lucene 中TFIDFSimilarity类的文档:http://lucene.apache.org/core/4_9_0/core/org/ apache/lucene/search/similarities/TFIDFSimilarity.html.
时间: 2024-10-04 12:40:02