前面有过一篇文章介绍TinyDbRouter,但是当时没有开出来,主要原因是:1偶的粉丝数太少,期望到100的时候,纪念性的发布这个重量级框架,另外一个原因是当时有个编译问题没有完美的解决,偶担心同学们使用的时候不方便--其实偶也不方便,尤其是发布和测试的时候。
现在粉够100了,那个编译问题也顺利的解决了,OK,没有什么理由不快些把它开放给大家。
前面偶起的名字是TinyDBCluster,后来由于有同学们反应说这个与数据库集群歧义,因此还是改成TinyDBRouter了,如果看到两个名字,请把它们当成一样的,后面就专门用TinyDBRouter。
其实在开发TinyDbRouter之前,偶主要是想找一个比较合适的数据库分区、分表方案,为此也学习了各种实现方案,比如就了解过routing4db,偶也专门做了对比,当然由于对routing4db的了解毕竟有不足,因此可能有许多不准确的地方;另外也对淘宝系的tddl做了相关研究,但是最后偶还是决定自己尝试写一下,当然写完之后感觉还是不错的,因此才有现在开源的TinyDbRouter。
好的,上面是一些背景情况,现在言归正传,我们正式说框架。
关于Tiny DBRouter的原理性文章,请移步查阅,这里主要讲使用。
要想使用Tiny DBRouter,很简单,首先搞清楚是jdbc3(JDK1.5)还是jdbc4(JDK1.6及以上)的规范。
然后选择对应的Maven坐标:
|
1 2 3 4 5 |
|
或者
|
1 2 3 4 5 |
|
之所以是SNAPSHOT版本,是因为Tiny框架的升级是阶段性升级的,过一段时间就会变成0.0.13正式版本。
当把相关jar包下载到本地之后,接下来就是配置分区分表数据源了。
我们拿一个例子来说明:
differentSchemaAggregate.xml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
|
内容虽然比较长,但是其实很简单的,听偶娓娓道来:
一个配置文件可以配置多个数据库集群,因此根节点叫routers,接下来一段router就是一个集群喽。
|
1 2 |
|
id非常重要,在通过jdbc访问数据库集群的时候,在url中要用到id,用户名和密码就是在通过jdbc连接时的用户名密码,呵呵,现在密码是明码,后续版本密码部分,会改为加密存储。
采用逻辑主键时,经常需要生成一个主键,由于集群环境中,主键的生成是一个细致活,原来采用数据库的自动生成序列、自增长啥的都不好用了,因此,一定需要一个集群模式的主键生成器。不过不用担心,框架已经提供了整型、长整型、UUID三种分布式主键生成器,大多数的情况下都够用了,如果再不够,请给我们提需求或者自已动手丰衣足食,自行进行扩展。
|
1 |
|
这里定义了数据主键生成的一些参数配置,首先,需要一个数据源的名称,因为有一些数据需要在数据库中存储。increment表示每次主键增长幅度,step表示每申请一次缓冲多个主键。当然,这两个参数都可以忽略,这时就采用系统默认值了--多数情况下都够了。
|
1 2 3 4 5 |
|
这里定义的就是集群中要用到的数据源的列表,熟悉jdbc的同学一看就知道什么意思就不讲了,为什么这里统一一个区域定义数据源呢??因为如果是同库分表的话,数据源实际上就是一个,这个时候只用定义一个就够了。
接下来就是定义分区了:
一个集群可以包含多个分区,一个分区可以包含多个分片。
|
1 |
|
mode这里用于声明分区的模式,分区有两种方式,为1的时候表示读写分离模式,为2的时候表示分表模式。
|
1 2 |
|
一个分区可以包含多个分区规则,分区规则主要用于确定哪些表跑到一个分区。这里很简单,配置的是只要表名是score,就跑到本分区来执行。
一个区分又可以有多个分片,每个分片可以有一到多个分片规则,以决定是否到当前分片执行。
|
1 2 3 4 5 6 7 |
|
上面的规则是指根据score表的id值对shard数进行取余,余数为0的命中。 另外的两个就是说余数为1和为2的时候执行。
很明显分片规则和分区规则都是可以自行扩展的---凡是可以指定bean或类名的,都是可以进行扩展滴。
用白话总结一下,上面的配置:
|
1 2 3 4 5 6 7 |
|
OK,上面的定义就算完成了,下面上大菜,看测试用例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 |
|
上面首先在setUp中做了一点初始化工作,主要就是下面两句:用于加载一个集群配置,实际使用有两种方法:
编程方式,约定方式。下面用的就是编译方式,如果用编写方式就简单了,只要按约定放在合适的位置,框架会自动加载配置文件,就可以不写下面的两行了。
|
1 2 |
|
其它的工作就与普通的JDBC没有任何不同了。
我们看看初始化之后, 数据的情况:
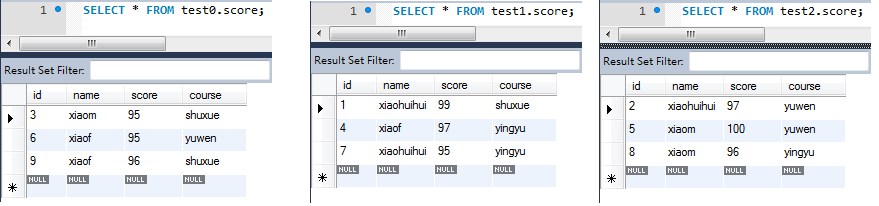
从上面可以看到,数据确实已经插入到三个数据表中。
后面的几个测试用例主要测试的是聚合统计方面的处理,实际上,所有的SQL语句都可以正常的执行,对于上层应用来说,它根本就不知道分表了。
急性子的同学们可能要问:
那如果我输入select * from score where id=3,结果会正确出来么?当然
那如果我输入select * from score order by id,结果会正确出来么?当然
我要说的,还远不止如此:
实际上TinyDBRouter已经竭尽全力,来支持数据库的特性:
比如:自增长
还是上面的score类子,如果在插入的时候不指定id值,如下:
|
1 |
|
TinyDBRouter会同样进行正常的插入,完全透明的处理好分布式主键的问题。这个与类似的框架比就先进许多了。类似的框架都是需要必须输入id,并且自己保证或必须调用其分库分表方案中提供的API来获取主键。这实际上就是有侵入性,也就是人编程人员可以感知到分库分表的存在,且必须按照相应规范进行使用。而使用TinyDBRouter,开发人员可以完全不知道有这么一层存在。
比如统计处理:
假设在一个表中有9条数据,我们执行下面的语句:
|
1 |
|
我们都知道实际处理是名字相同的score值加起来,然后除以记录数,得到平均值。
但是现在数据都分成3个表了,如果在3个表上执行同样的处理:
|
1 |
|
然后再进行平均值计算,可不可以呢???答案是否定的。卖个关子这里不做解释,有不理解的同学,下面回帖发问。但是TinyDBRouter框架却可以保证结果的正确性。
数据库支持的普适性:
TinyDBRouter理论上支持各种数据库,各种ORMapping框架,而一般的框架是针对某种ORMapping框架做的,比如:专门针对iBatis,Hibernate的;有的只针对MySql或Oracle等。
SQL支持的普适性:
TinyDBRouter理论上支持所有不违反TinyDBRouter适应规则的SQL。而许多同类框架则有诸多限制。
TinyDBRouter使用限制:
- 不支持跨分区关联查询
- 分表模式中只支持光标分页,不支持SQL分页
- 不支持savePoint
- 暂时不支持存储过程
总结
TinyDBRouter确实是非常优秀的分区分表方案,当然它也有缺点,那就是测试还不够充分,没有得到充分的验证。