在本节,我们主要介绍OpenCL中buffer的使用,同时提供了两个个完整的例子,一个是图像的旋转,一个是矩阵乘法(非常简单,没有分块优化)。
1、创建OpenCL设备缓冲(buffer)
OpenCL设备使用的数据都存放在设备的buffer中[其实就是device memory中]。我们用下面的代码创建buffer对象:
如果host_ptr指向一个有效的host指针,则创建一个buffer对象的同时会实现隐式的数据拷贝(会在kernel函数进入队列时候,把host_prt中的数据从host memory拷贝到设备内存对象bufferobj中)。
我们可以通过flags参数指定buffer对象的属性。

函数clEnqueueWriteBuffer()用来实现显示的数据拷贝,即把host memory中的数据拷贝到device meomory中。
2、图像旋转的例子
下面是一个完整的OpenCL例子,实现图像的旋转。在这个例子中,我把美丽的Lenna旋转了90度。
下面是原始图像和旋转后的图像(黑白)


在这个例子中,我使用FreeImage库,可以从FreeImage网站或者我的code工程中下载。
http://code.google.com/p/imagefilter-opencl/downloads/detail?name=Dist.rar&can=2&q=#makechanges
图像旋转是指把定义的图像绕某一点以逆时针或顺时针方向旋转一定的角度,通常是指绕图像的中心以逆时针方向旋转。
假设图像的左上角为(left, top),右下角为(right, bottom),则图像上任意点(x0, y0)绕其中心(xcenter, ycenter)逆时针旋转angle角度后,新的坐标位置(x′, y′)的计算公式为:
xcenter = (right - left + 1) / 2 + left;
ycenter = (bottom - top + 1) / 2 + top;
x′ = (x0 - xcenter) cosθ - (y0 - ycenter) sinθ + xcenter;
y′ = (x0 - xcenter) sinθ + (y0 - ycenter) cosθ + ycenter;
下面给出kernel的代码:
src_data为原始图像(灰度图)数据,dest_data为旋转后的图像数据。W、H分别为图像的高度和宽度。sinTheta和cosTheta是旋转参数。我在代码中实现了旋转90度,所以sinTheta为1,cosTheta为0,大家可以尝试其它的值。
下面是程序的流程图:
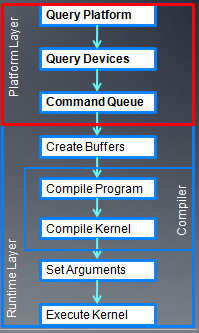
在前面向量加法的例子中,我已经介绍了OpenCL一些基本的步骤。
- 创建platform对象
- 创建GPU设备
- 创建contex
- 创建命令队列
- 创建缓冲对象,代码如下:
- 创建程序对象
- 编译程序对象
- 创建Kernel对象
- 设置kernel参数
- 执行kernel
- 数据拷贝回host memory,我采用映射memory的方式
kernel执行时间的计算后面教程会有详细介绍,但在本节中,我们会给出通过事件机制来得到kernel执行时间,首先要在创建队列时候,使用CL_QUEUE_PROFILING_ENABLE参数,否则计算的kernel运行时间是0。
下面是代码:
完整的程序代码:
感兴趣的朋友可以从http://code.google.com/p/imagefilter-opencl/downloads/detail?name=amdunicourseCode2.zip&can=2&q=#makechanges下载完整代码。
注意代码运行后,会在程序目录生成lenna_rotate.jpg,这时gpu执行的结果,另外还有一个cpu_lenna_rotate.jpg这是CPU执行的结果。
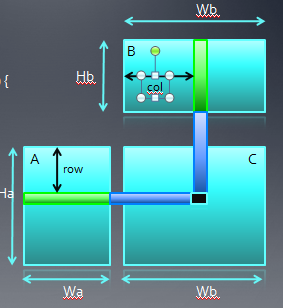
3、一个矩阵乘法的例子
在amd的slides中,本节还讲了一个简单的,没有优化的矩阵乘法,一共才两页ppt,所以我也不在这儿详细讲述了,…但简单介绍还是需要的。
上面的代码是矩阵乘法的例子,有三重循环,下面我们只给出kernel代码,完整程序请从:http://code.google.com/p/imagefilter-opencl/downloads/detail?name=amdunicodeCode3.zip&can=2&q=#makechanges下载。