1、OpenCL架构
OpenCL可以实现混合设备的并行计算,这些设备包括CPU,GPU,以及其它处理器,比如Cell处理器,DSP等。使用OpenCL编程,可以实现可移植的并行加速代码。[但由于各个OpenCL device不同的硬件性能,可能对于程序的优化还要考虑具体的硬件特性]。
通常OpenCL架构包括四个部分:
- 平台模型(Platform Model)
- 执行模型(Execution Model)
- 内存模型(Memory Model)
- 编程模型(Programming Model)
2、OpenCL平台模型
不同厂商的OpenCL实施定义了不同的OpenCL平台,通过OpenCL平台,主机能够和OpenCL设备之间进行交互操作。现在主要的OpenCL平台有AMD、Nvida,Intel等。OpenCL使用了一种Installable Client Driver模型,这样不同厂商的平台就能够在系统中共存。在我的计算机上就安装有AMD和Intel两个OpenCL Platform[现在的OpenCL driver模型不允许不同厂商的GPU同时运行]。
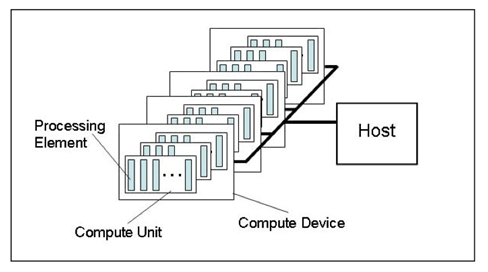
OpenCL平台通常包括一个主机(Host)和多个OpenCL设备(device),每个OpenCL设备包括一个或多个CU(compute units),每个CU包括又一个或多个PE(process element)。 每个PE都有自己的程序计数器(PC)。主机就是OpenCL运行库宿主设备,在AMD和Nvida的OpenCL平台中,主机一般都指x86 CPU。
AMD平台来说,所有的CPU是一个设备,CPU的每一个core就是一个CU,而每个GPU都是独立的设备。
3、OpenCL编程的一般步骤
下面我们通过一个实例来了解OpenCL编程的步骤,假设我们用的是AMD OpenCL平台(因为本人的GPU是HD5730),安装了AMD Stream SDK 2.6,并在VS2008中设置好了include,lib目录等。
首先我们建立一个控制台程序,最初的代码如下:
第一步,我们要选择一个OpenCL平台,所用的函数就是

通常,这个函数要调用两次,第一次得到系统中可使用的平台数目,然后为(Platform)平台对象分配空间,第二次调用就是查询所有的平台,选择自己需要的OpenCL平台。代码比较长,具体可以看下AMD Stream SDK 2.6中的TemplateC例子,里面描述如何构建一个健壮的最小OpenCL程序。为了简化代码,使程序看起来不那么繁琐,我直接调用该函数,选取系统中的第一个OpenCL平台,我的系统中安装AMD和Intel两家的平台,第一个平台是AMD的。另外,我也没有增加错误检测之类的代码,但是增加了一个status的变量,通常如果函数执行正确,返回的值是0。
第二步是得到OpenCL设备
这个函数通常也是调用两次,第一次查询设备数量,第二次检索得到我们想要的设备。为了简化代码,我们直接指定GPU设备。
下面我们来看下OpenCL中Context的概念:通常,Context是指管理OpenCL对象和资源的上下文环境。为了管理OpenCL程序,下面的一些对象都要和Context关联起来:
—设备(Devices):执行Kernel程序对象。
—程序对象(Program objects): kernel程序源代码
—Kernels:运行在OpenCL设备上的函数。
—内存对象(Memory objects): device处理的数据对象。
—命令队列(Command queues): 设备之间的交互机制。
注意:创建一个Context的时候,我们必须把一个或多个设备和它关联起来。对于其它的OpenCL资源,它们创建时候,也要和Context关联起来,一般创建这些资源的OpenCL函数的输入参数中,都会有Context。


这个函数中指定了和Context关联的一个或多个设备对象,properties参数指定了使用的平台,如果为NULL,厂商选择的缺省值被使用,这个函数也提供了一个回调机制给用户提供错误报告。
现在的代码如下:
接下来,我们要看下命令队列。在OpenCL中,命令队列就是主机的请求,在设备上执行的一种机制。Kernel执行前,我们一般要进行一些内存拷贝的工作,比如把主机内存中的数据传输到设备内存中。
另外要注意的几点就是:对于不同的设备,它们都有自己的独立的命令队列;命令队列中的命令(kernel函数)可能是同步的,也可能是异步的,它们的执行顺序可以是有序的,也可以是乱序的。

命令队列在device和context之间建立了一个连接。
命令队列properties指定以下内容:
- 是否乱序执行(在AMD GPU中,好像现在还不支持乱序执行)
- 是否启动Profiling。Profiling通过事件机制来得到kernel执行时间等有用的信息,但它本身也会有一些开销。
如下图所示,命令队列把设备和context联系起来,尽管它们之间不是物理连接。
添加命令队列后的代码如下: